Web Scraping Product Data in R with rvest and purrr
Written by Joon Im

This article comes from Joon Im, a student in Business Science University. Joon has completed both the 201 (Advanced Machine Learning with H2O) and 102 (Shiny Web Applications) courses. Joon shows off his progress in this Web Scraping Tutorial with rvest.
R Packages Covered:
rvest & jsonlite - Web Scraping HTML and working with JSON datapurrr - Iteration through lists using map() and safely()stringr - Text manipulationggplot2 - Data visualization and understanding data
Scraping Website Data and Analyzing Specialized Bicycles
by Joon Im, Data Analyst with Instacart
Happy Monday everyone! I recently completed the Part 2 of the Shiny Web Applications Course, DS4B 102-R and decided to make my own price prediction app. The app works by predicting prices on potential new bike models based on current existing data.
Using techniques gleaned from Matt Dancho’s Learning Lab 8 on web-scraping with rvest to get data, I took on the challenge he mentioned there and scraped product data on bicycles from Specialized.com to create my own data set. (I highly encourage you to sign up for Learning Labs Pro: web-scraping with rvest has fundamentally changed the way I understand the Internet). I also tried to match the website’s styling with some CSS tweaking but I’m new to all that so please bear with me if there are issues (e.g. fonts).
I welcome any questions and would appreciate any feedback. Thank you for your time, BSU community!
My Workflow
Here’s a diagram of the workflow I used to web scrape the Specialized Data and create an application:
-
Start with URL of Specialized Bicycles
-
Use rvest and jsonlite to extract product data
-
Clean up data into “tidy” format using purrr and stringr
-
Visualize product prices with ggplot2
-
Make a Shiny Web App using the Business Science 102 Course.
My Code Workflow for Web Scraping with rvest
My Shiny App
I built a shiny web application to recommend product prices of new bicylces, which you can try out: Specialize Product Price Recommendation Application.
I explain more details about how I built my shiny app in Section 5 - Predictive Web App.
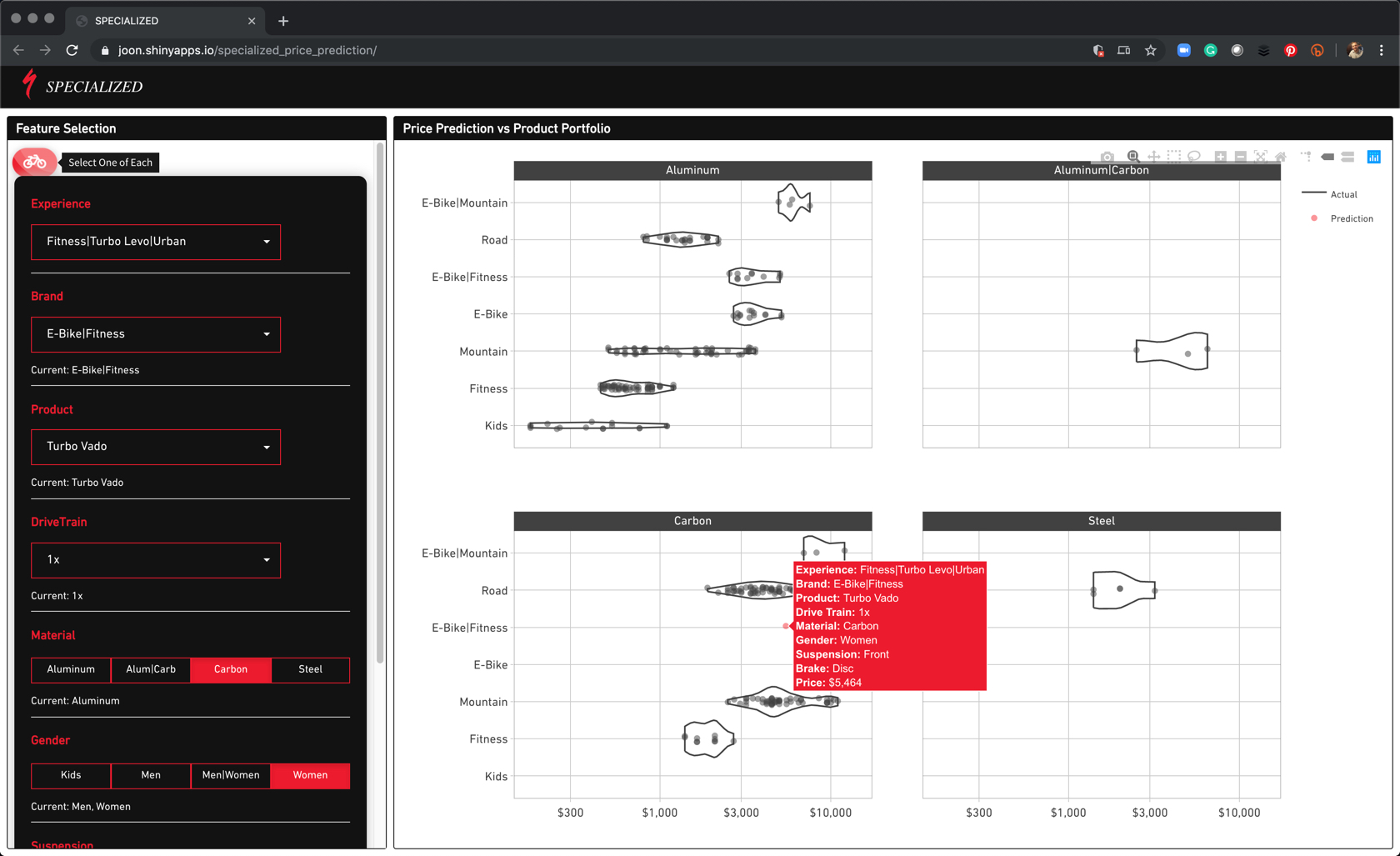
Try out my Shiny App that Recommends Specialized Bicycle Prices using XGBoost
Tutorial - Web Scraping with rvest
This tutorial showcases how to web scrape websites using rvest and purrr. I’ll show how to collect data on the 2020 Specialized Bicycles Product Collection, a useful task in building a strategic database of product and competitive information for an organization.
1. Set Up
1.1 Introduction
Specialized® is a bicycle company founded by Mike Sinyard in 1974 from his hometown of Morgan Hill, California. They became known for creating the first production mountain bike back in 1981, called the Stumpjumper. Now they are building professional-grade bikes for riders around the world. Here’s a nice breakdown of different models on Bike Radar if you are interested in learning more.
Business Science is an online learning company founded by Matt Dancho in 2017 and is my favorite place to learn data science skills with R such as:
One great offering is their ongoing Learning Labs Pro series, which teaches additional skills such as time series forecasting, customer churn survival analysis, web-scraping and more.
In Learning Lab 8: Web Scraping — Build A Strategic Database With Product Data from Business Science, a challenge for students was issued to scrape product data on bikes from Specialized’s website. Today, we’re going to do just that.
In Learning Lab 8, a challenge for students was issued to scrape product data on bikes from Specialized’s website. Today, we’re going to do just that.
1.2 Check Robots
Always look at the website’s robots.txt to check crawling permissions. Here’s Specialized’s robots.txt.

1.3 Load Libraries
Let’s start with loading libraries that we know we will need.
# Load libraries
library(rvest) # HTML Hacking & Web Scraping
library(jsonlite) # JSON manipulation
library(tidyverse) # Data Manipulation
library(tidyquant) # ggplot2 theme
library(xopen) # Opens URL in Browser
library(knitr) # Pretty HTML Tables
1.4 Check Out the Products
Let’s navigate to the “Bikes” Page for Specialized.
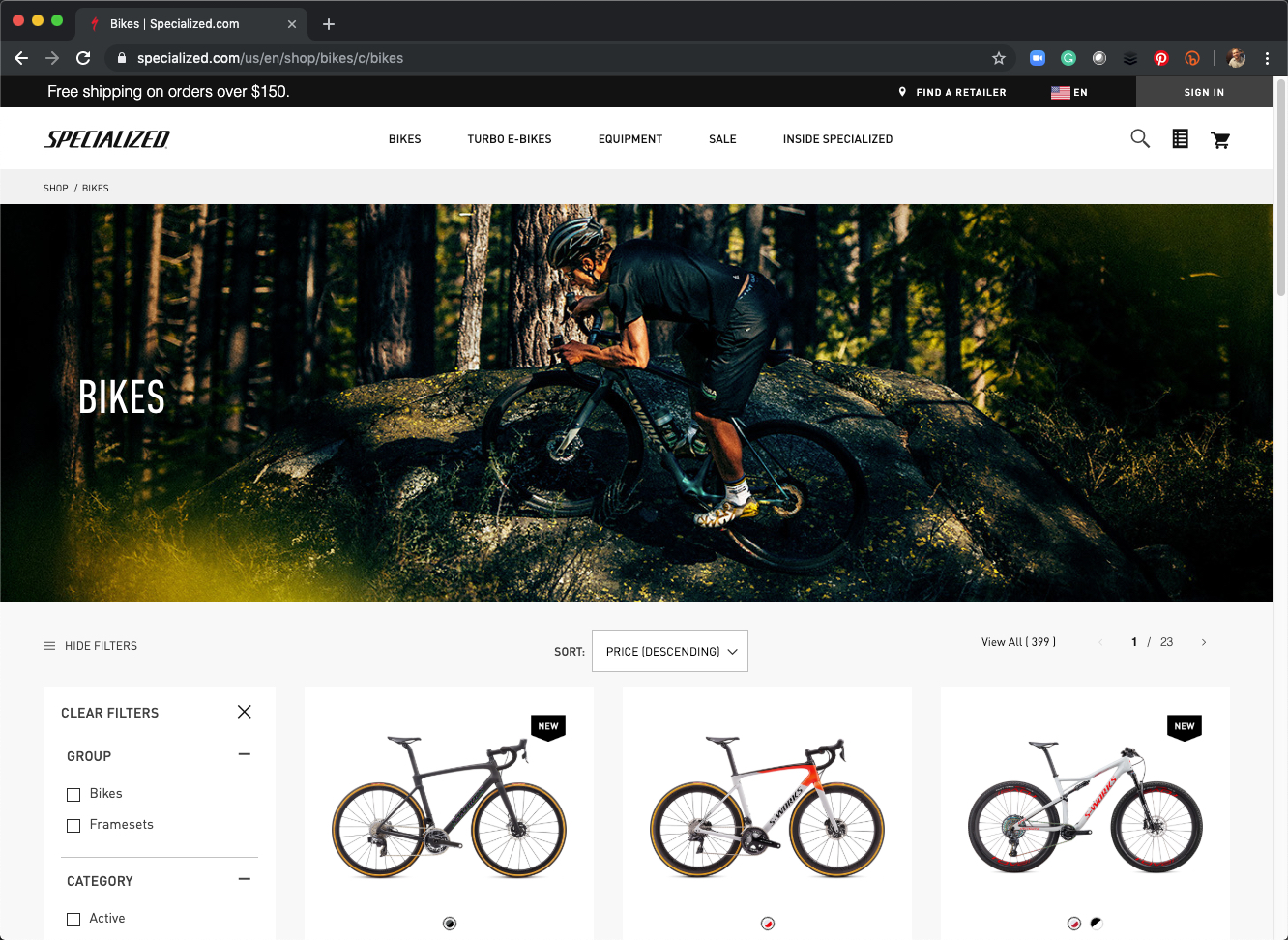
We can click “View All” to view all 399 bikes on a single page. This makes things a bit easier when it comes time to scrape so we don’t have to iterate over multiple pages.
Save the URL.
# URL to View All Bikes
url <- "https://www.specialized.com/us/en/shop/bikes/c/bikes?q=%3Aprice-desc%3Aarchived%3Afalse&show=All"
You can then use xopen() to open the URL in your default web browser.
# View URL in Browser
xopen(url)
1.5 Read HTML
Load the HTML code into an object using read_html(). We’ve just grabbed all of the HTML from that page.
# Read HTML from URL
html <- read_html(url)
html
## {html_document}
## <html lang="en">
## [1] <head>\n<title>\n Bikes | Specialized.com</title>\n<meta ...
## [2] <body class="page-productListPage pageType-CategoryPage templat ...
2. Get the Raw Data
Use Chrome DevTools to locate the product information. In our case, there is a JSON-like dictionary containing what we need.
Find the data by using the hover tool.
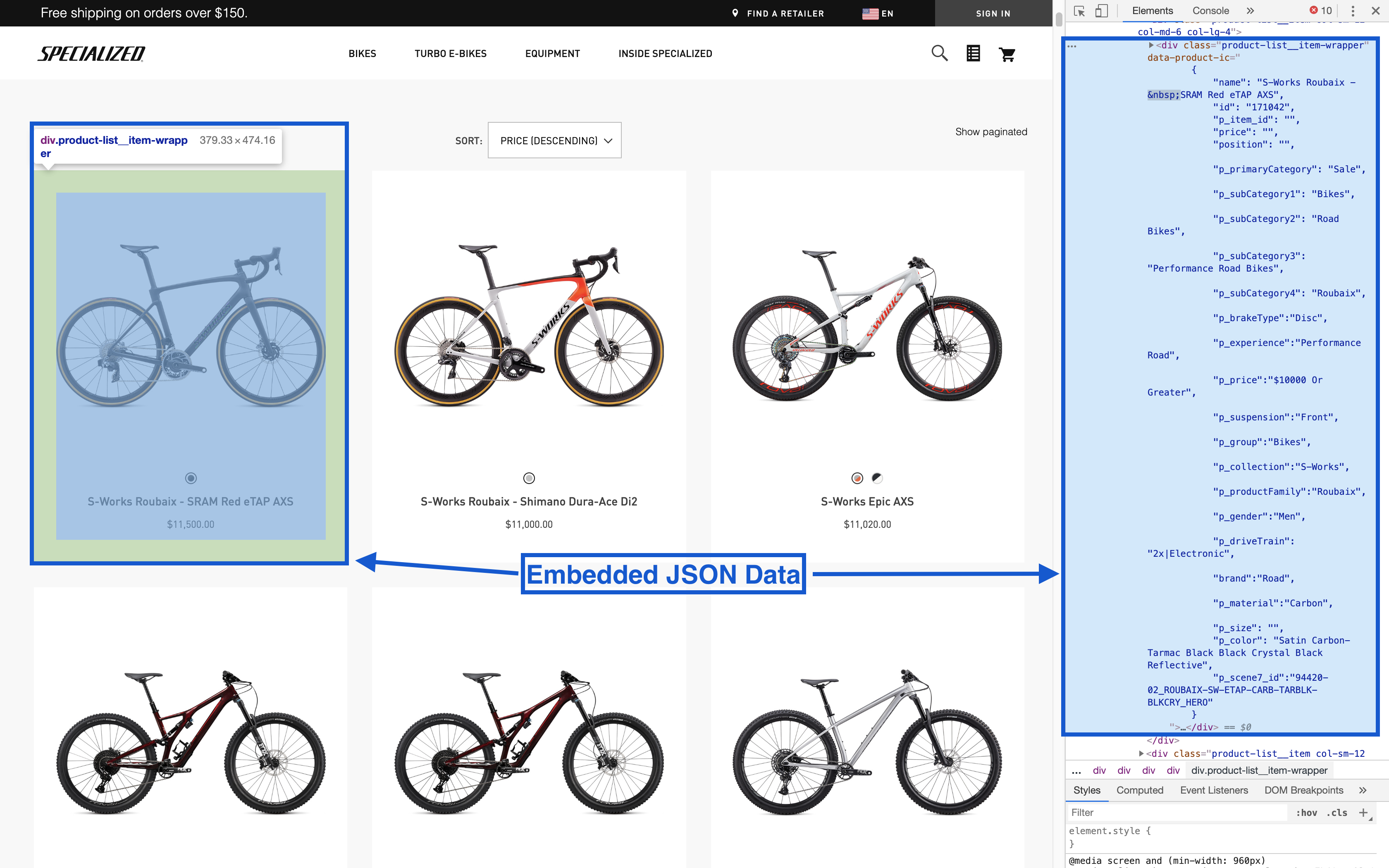
2.2 Find Product Data Nodes
Find the nodes where the product data lives.

2.3 Filter HTML to Isolate Nodes
Copy and paste the class into the html_nodes() function from the rvest library.
html %>%
html_nodes(".product-list__item-wrapper")
2.4 Find the Attribute That Contains the Data
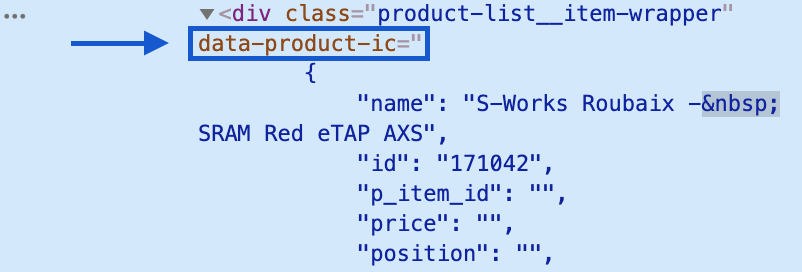
Extract the attributes with the html_attr() function and store it as a JSON object. Note that we’ll need to convert the JSON into a better format for analysis (more on this in a minute).
# Store JSON as object
json <- html %>%
html_nodes(".product-list__item-wrapper") %>%
html_attr("data-product-ic")
# Show the 1st JSON element (1st bike of 399 bikes)
json[1]
## [1] "{\"name\":\"S-Works Roubaix - SRAM Red eTap AXS\",\"id\":\"171042\",\"brand\":\"Specialized\",\"price\":11500,\"currencyCode\":\"USD\",\"position\":\"\",\"variant\":\"61\",\"dimension1\":\"Bikes\",\"dimension2\":\"Road\",\"dimension3\":\"Roubaix\",\"dimension4\":\"\",\"dimension5\":\"Performance Road\",\"dimension6\":\"S-Works\",\"dimension7\":\"\",\"dimension8\":\"Men/Women\"}"
Tidy data is a tibble (data frame) that has one row for the each of the Specialized Bike Models and columns for each of the features like model name, price, and various categories (denoted as dimensions).
3.1 Make a Function that Converts JSON to Tibble
This function is just a wrapper for toJSON from the jsonlite package. The only addition is converting the data frame to a tibble using as_tibble().
# Make Function
from_json_to_tibble <- function(json) {
json %>%
fromJSON() %>%
as_tibble()
}
We can run this on the first element of the list.
json[1] %>%
from_json_to_tibble() %>%
knitr::kable()
| name |
id |
brand |
price |
currencyCode |
position |
variant |
dimension1 |
dimension2 |
dimension3 |
dimension4 |
dimension5 |
dimension6 |
dimension7 |
dimension8 |
| S-Works Roubaix - SRAM Red eTap AXS |
171042 |
Specialized |
11500 |
USD |
|
61 |
Bikes |
Road |
Roubaix |
|
Performance Road |
S-Works |
|
Men/Women |
3.2 Iterate to All JSON Elements
We’ll use map() to iteratively apply our from_json_to_tibble() function. If we just run this, the iterative conversion error’s out - This is common in long-running iterative scripts. We can get around this using the safely() function, which isolates the errors and allows the iteration to continue (instead of grinding to a hault).
# Iterate - All JSON objects ----
bike_data_list <- json %>%
map(safely(from_json_to_tibble))
3.3 Inspect First Converted Element
We can see that a list is returned with 2 elements for each item:
-
$result - Contains the result. If conversion succeeds, we get a tibble. If error, we get NULL.
-
$error - Contains the error message (if error). Otherwise, we get NULL.
# Inspect first conversion: $result & $error
bike_data_list[1]
## [[1]]
## [[1]]$result
## # A tibble: 1 x 15
## name id brand price currencyCode position variant dimension1
## <chr> <chr> <chr> <int> <chr> <chr> <chr> <chr>
## 1 S-Wo… 1710… Spec… 11500 USD "" 61 Bikes
## # … with 7 more variables: dimension2 <chr>, dimension3 <chr>,
## # dimension4 <chr>, dimension5 <chr>, dimension6 <chr>,
## # dimension7 <chr>, dimension8 <chr>
##
## [[1]]$error
## NULL
3.4 Inspect for Errors
We are bound to get errors in this JSON conversion process for 399 bikes. Let’s check to see where errors occurred.
error_tbl <- bike_data_list %>%
# Grab just the $error elements
map(~ pluck(., "error")) %>%
# Convert from list to tibble
enframe(name = "row") %>%
# Return TRUE if element has error
mutate(is_error = map(value, function(x) !is.null(x))) %>%
# Unnest nested list
unnest(is_error) %>%
# Filter where error == TRUE
filter(is_error)
error_tbl
## # A tibble: 2 x 3
## row value is_error
## <int> <list> <lgl>
## 1 222 <smplErrr> TRUE
## 2 288 <smplErrr> TRUE
3.5 What happened?
We got two errors - Bike 222 and 288. We can use pluck() to grab the first error in the “value” column. It’s the result of an errant " symbol that represents inches.
error_tbl %>% pluck("value", 1)
## <simpleError: lexical error: invalid char in json text.
## osition":"","variant":"22.5" TT","dimension1":"Bikes","dimen
## (right here) ------^
## >
We can get around this by replacing the ". Let’s re-run the code using the str_replace() function to replace the quote.
json[222] %>%
str_replace('22.5\\" TT', '22.5 TT') %>%
from_json_to_tibble()
## Error: lexical error: invalid char in json text.
## imension4":"","dimension5":""BMX / Dirt Jump"","dimension6":
## (right here) ------^
We get another error. There is an errant set of quotes around “BMX / Dirt Jump”. We can use str_replace() again to resolve. Success!
json[222] %>%
str_replace('\\"BMX / Dirt Jump\\"', 'BMX / Dirt Jump') %>%
str_replace('22.5\\" TT', '22.5 TT') %>%
from_json_to_tibble()
## # A tibble: 1 x 15
## name id brand price currencyCode position variant dimension1
## <chr> <chr> <chr> <int> <chr> <chr> <chr> <chr>
## 1 P.Sl… 1710… Spec… 2500 USD "" 22.5 TT Bikes
## # … with 7 more variables: dimension2 <chr>, dimension3 <chr>,
## # dimension4 <chr>, dimension5 <chr>, dimension6 <chr>,
## # dimension7 <chr>, dimension8 <chr>
3.6 Run Again - Success - Errors Fixed!
We can try one more time, now using the str_replace() to remove the quotes causing conversion errors, and map_dfr() to return a data frame stacked row-wise.
# Fix errors, re-run
bike_features_tbl <- json %>%
str_replace('\\"BMX / Dirt Jump\\"', 'BMX / Dirt Jump') %>%
str_replace('22.5\\" TT', '22.5 TT') %>%
map_dfr(from_json_to_tibble)
# Show first 6 rows
bike_features_tbl %>%
head() %>%
kable()
| name |
id |
brand |
price |
currencyCode |
position |
variant |
dimension1 |
dimension2 |
dimension3 |
dimension4 |
dimension5 |
dimension6 |
dimension7 |
dimension8 |
| S-Works Roubaix - SRAM Red eTap AXS |
171042 |
Specialized |
11500 |
USD |
|
61 |
Bikes |
Road |
Roubaix |
|
Performance Road |
S-Works |
|
Men/Women |
| S-Works Roubaix - Shimano Dura-Ace Di2 |
170241 |
Specialized |
11000 |
USD |
|
56 |
Bikes |
Road |
Roubaix |
|
Performance Road |
S-Works |
|
Men/Women |
| S-Works Epic AXS |
171229 |
Specialized |
11020 |
USD |
|
S |
Bikes |
Mountain |
Epic FSR/Epic |
|
Cross Country |
S-Works |
|
Men/Women |
| Stumpjumper EVO Comp Carbon 29 |
173494 |
Specialized |
4520 |
USD |
|
S3 |
Bikes |
Mountain |
Stumpjumper EVO |
|
Trail |
|
|
Men/Women |
| Stumpjumper EVO Comp Carbon 27.5 |
173495 |
Specialized |
4520 |
USD |
|
S2 |
Bikes |
Mountain |
Stumpjumper EVO |
|
Trail |
|
|
Men/Women |
| Fuse Expert 29 |
171068 |
Specialized |
2150 |
USD |
|
XS |
Bikes |
Mountain |
Fuse |
|
Trail |
|
|
Men/Women |
4. Explore Bike Models
I want to understand how price depends on various features like model, type of bike (electric, mountain, road), and other features that will eventually be used in my XGBoost Machine Learning model inside of my Shiny Web App.
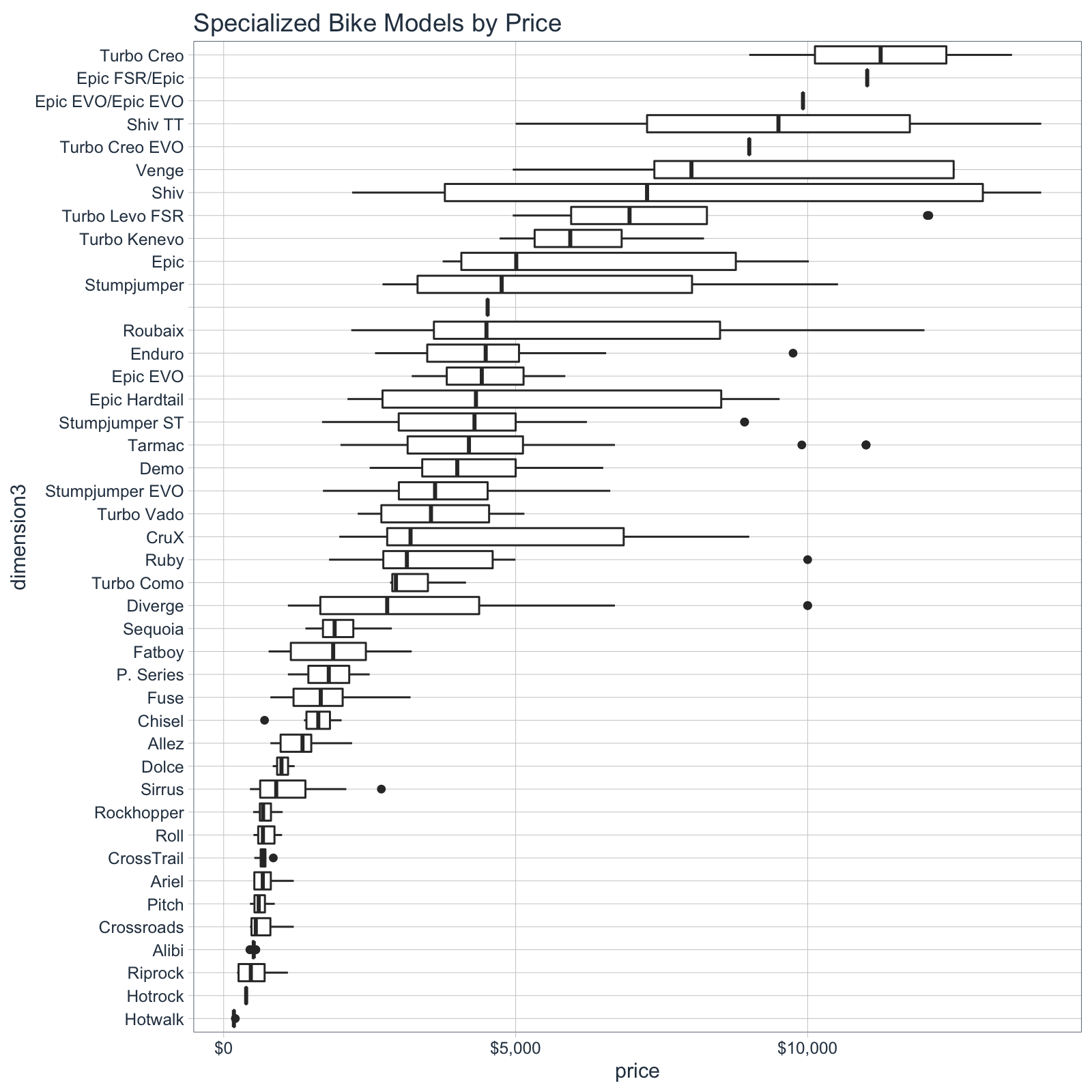
4.1 Most and Least Expensive Bike Models
There’s a clear relationship between price and “Dimension 3” (bike model). We can see this visually.
bike_features_tbl %>%
select(dimension3, price) %>%
mutate(dimension3 = as_factor(dimension3) %>%
fct_reorder(price, .fun = median)) %>%
# Plot
ggplot(aes(dimension3, price)) +
geom_boxplot() +
coord_flip() +
theme_tq() +
scale_y_continuous(labels = scales::dollar_format()) +
labs(title = "Specialized Bike Models by Price")
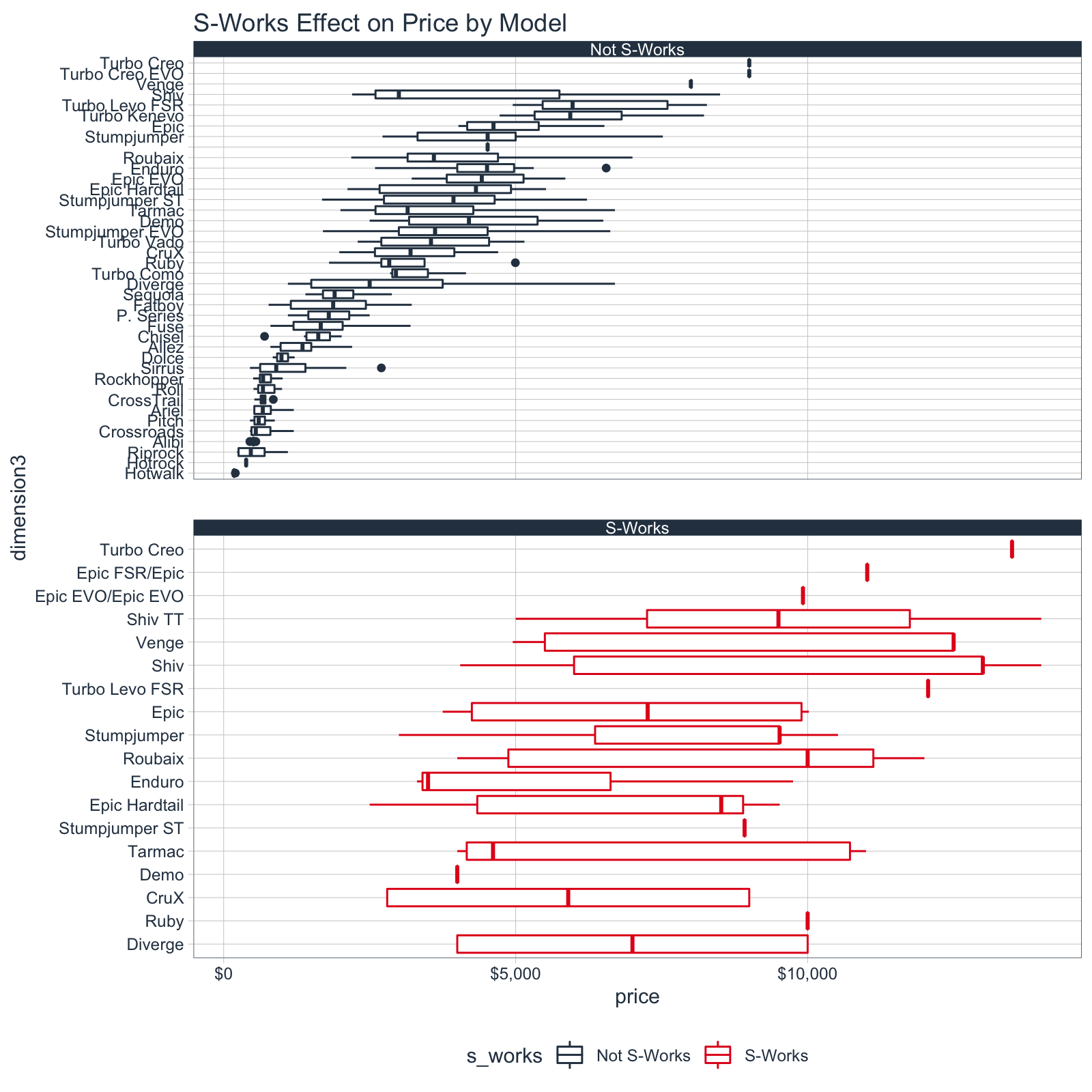
4.2 S-Works Effect
I also noticed that “S-Works” is Specialized’s Premium Brand. We can update the ggplot2 visualization to segment bikes with “S-Works” in the model name to visually compare the “S-Works Effect”. I see that the S-Works bikes tend to have a higher median price than “non-S-Works”.
bike_features_tbl %>%
select(name, price, dimension3) %>%
mutate(s_works = ifelse(str_detect(name, "S-Works"), "S-Works", "Not S-Works")) %>%
mutate(dimension3 = as_factor(dimension3) %>%
fct_reorder(price, .fun = median)) %>%
# Plot
ggplot(aes(dimension3, price, color = s_works)) +
geom_boxplot() +
coord_flip() +
facet_wrap(~ s_works, ncol = 1, scales = "free_y") +
theme_tq() +
scale_color_tq() +
scale_y_continuous(labels = scales::dollar_format()) +
labs(title = "S-Works Effect on Price by Model")
5. Predictive Web Application
I made and deployed a Product Price Recommendation Application for Specialized Bicycles using the web-scraped Specialized Data. Here’s how I built it:
-
The Shiny app uses the webscraped data from 2019 Specialized Models (this tutorial covers web-scraping 2020 models), which I learned in Learning Lab 8.
-
I built the Shiny app using Part 2 of the Shiny Web Applications Course (DS4B 102-R), the 2nd course in the 3-Course R-Track.
-
The shiny application uses an XGBoost Machine Learning model to recommend product prices based on the existing product portfolio.
-
The code is available in my GitHub Repo Here.
Try out my Shiny App that Recommends Specialized Bicycle Prices using XGBoost
Parting Thoughts
Web-scraping with rvest has fundamentally changed the way I understand the Internet. Once I realized that the entire Internet (well, most of it) is basically just one big database, it rocked my world. I highly encourage you to sign up for Learning Labs Pro. Learning Lab 8 - Web Scraping - Build A Strategic Database With Product Data with rvest was what opened my eyes to the power of web scraping.
Using the data, I was able to make and deploy a Shiny web application that uses an XGBoost Machine Learning model to predict and recommend bicycle prices. This is just one way that businesses can use the strategic database. If you want to learn shiny, I highly recommend the Shiny Web Applications Course by Business Science. You can take it as part of the 3-Course R-Track Bundle offered by Business Science.
See what our students are doing:
Student Success Stories
Real stories of success from our students applying their skills learned at Business Science University to get jobs and help their organizations!
Student Code Tutorials
Tutorials made by our students using their new skills learned at Business Science University!