Marketing Analytics and Data Science
Written by David Curry
Summary
The data science community, Kaggle, recently announced the Google Analytics Customer Revenue Prediction competition. The competition uses data from the Google Merchandise store, and the challenge is to create a model that will predict the total revenue per customer.
I’m using the Kaggle competition as an opportunity to show how data science can be used in digital marketing to answer a specific question, and take what is learned from the data and apply it to marketing strategies.
In my approach to the competition, I am using the Business Science Problem Framework (BSPF), a methodology for applying data science to business problems.
The BSPF was developed by Matt Dancho of Business Science. Business Science has an online university for learning data science on a pro level. I learned the BSPF methodology from their course, Data Science for Business with R.
Other articles you might like:
Table of Contents
1. The Business Problem
The competition outlines the problem:
The 80/20 rule has proven true for many businesses – only a small percentage of customers produce most of the revenue. As such, marketing teams are challenged to make appropriate investments in promotional strategies.
The Google merchandise store wants to know which customers are generating the most revenue (customer value). Understanding customer value will allow the business to strategically dedicate resources to maximize their return on investment. More about this in the Impact section.
The Goal: Predict the revenue of a customer
Note: The article excludes some of my thought process and analysis for brevity and understanding for a non-technical.
2. Data Understanding
Exploratory data analysis (EDA) is an observational approach to understand the characteristics of the data. This step will provide insight into a data set, uncover the underlying structure and extract important variables.
EDA is a necessary step to understand the data before attempting to create a predictive model.
A big thanks to Erik Bruin for sharing his exploratory data analysis on Kaggle. I share Erik’s EDA findings below. The full exploratory data analysis is quite long, therefore, I will focus on highlighting some of the important findings.
2.1 Data Overview
The data consists of approximately 1.7 million records (observations) and is split between training and test datasets. The training data is used to train a machine learning model, while the test data is used to validate the accuracy of the model.
Each observation contains information, such as the number of times a user visited the store, the date/time of visit, the visitor’s country, etc. The data does not contain personal identifying information, with all persons identified by a visitor ID.
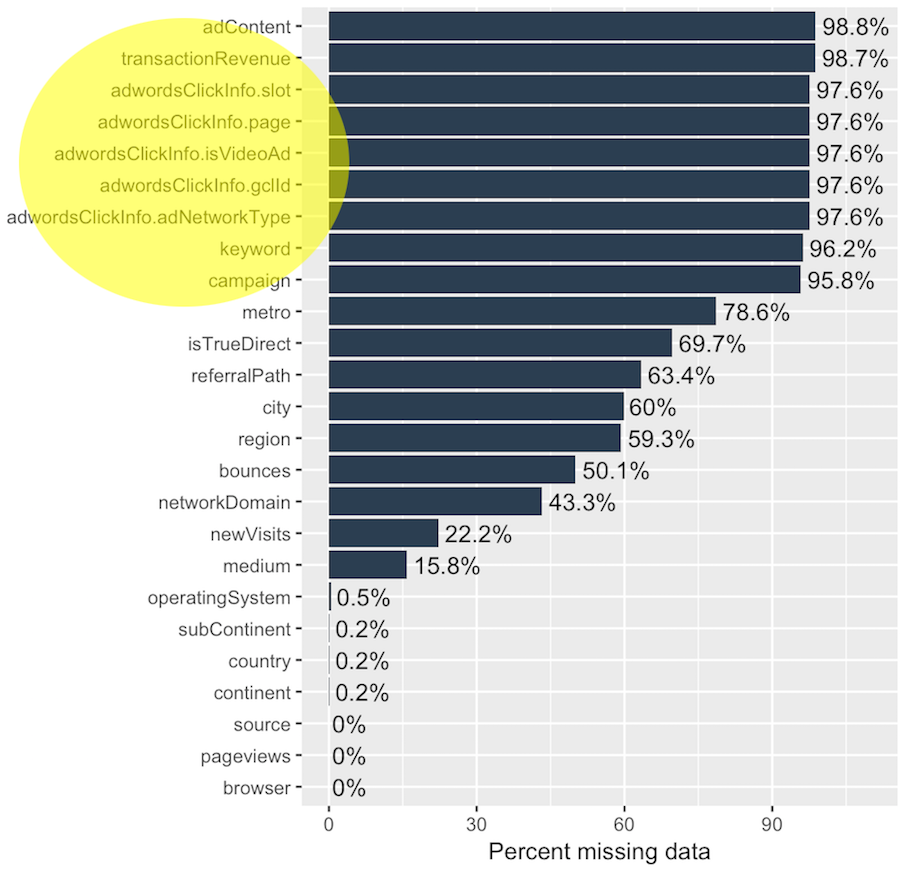
2.2 Missing Data
There are over 900,000 observations in the training dataset, with each observation representing a store visit.
The Takeaway: There are 14 variables in the training dataset containing missing values. Most of these variables are related to Google AdWords campaigns, we surmise the missing transaction revenue data means there was no transaction.
2.3 Understanding Transaction Revenue
Only 11,515 web sessions resulted in a transaction, which is 1.27% of the total observations.
Altogether, the store had 1.5 million dollars revenues in that year, with the range of revenues-per-transaction from $1 to approximately $23,000. Only 1.6% of the 11,515 transactions had revenues over $1,000.
The Takeaway: Only a small percent of all the data resulted in a transaction, with almost all of the transactions resulting in less than $1000.
2.4 Sessions and Revenues by Date
The number of daily website sessions peaked in October and November 2016 but did not lead to higher daily revenues. In the revenues plot below, Daily Revenues vary between $0 and approximately $27,000 and that there is no revenues trend visible.
In addition, there are some outliers with high daily revenues. Notice the revenue spikes marked in yellow.
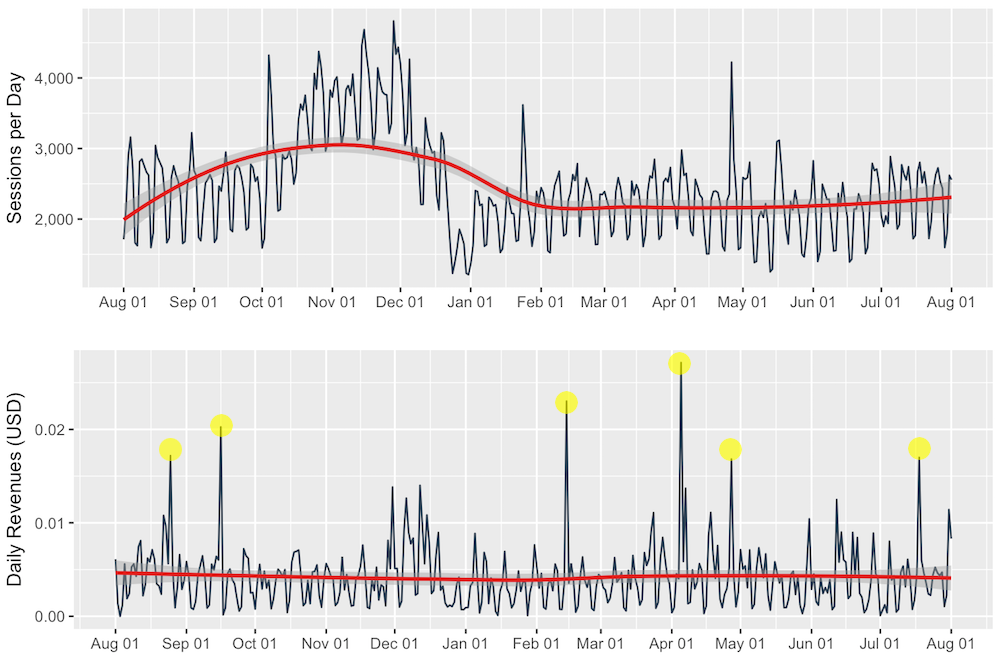
The Takeaway: I should consider revenue anomalies to accurately predict customer revenue.
2.5 Sessions and Revenues by Workday
Notice from the plot below there are fewer sessions and revenues on the weekend. A logical explanation seems that Google-branded merchandise is mostly bought by businesses who operate during the weekdays.
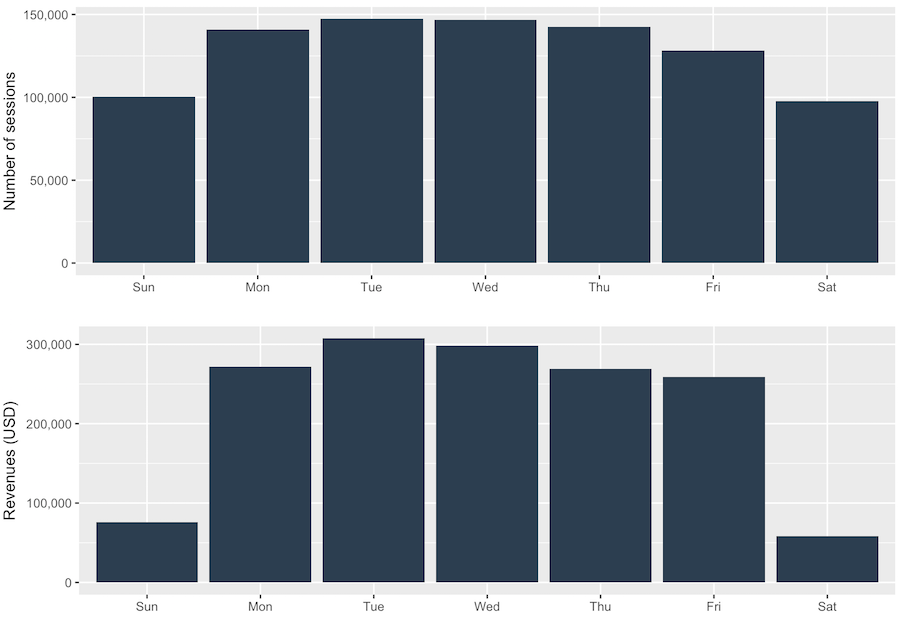
The Takeaway: The weekend website sessions and revenue are lower than the weekdays.
2.6 Sessions and Revenues by Month
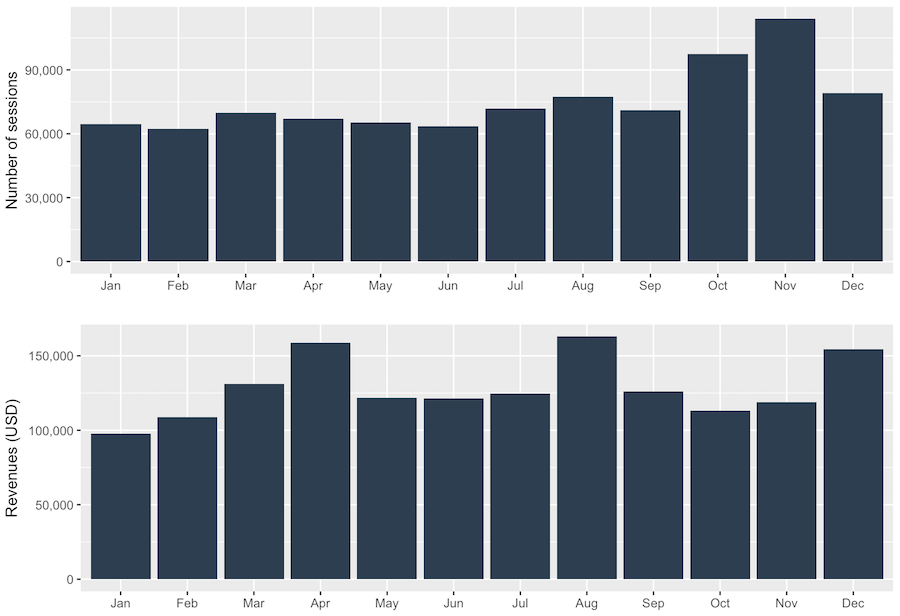
The Takeaway: Looking at the month patterns, April has a high ratio of revenues/sessions, and November has a low ratio of revenues/sessions. This is something to keep track of.
2.7 Channel Grouping
Channels define how people come to your website. The default channel groupings can be found here. These groups are mostly defined by the Medium, and some also by Source, Social Source Referral or Ad Distribution Network. From Google Analytics:
- Source: the origin of your traffic, such as a search engine (for example, Google) or a domain.
- Medium: the general category of the source, for example, organic search (organic), cost-per-click paid search (CPC), web referral (referral).
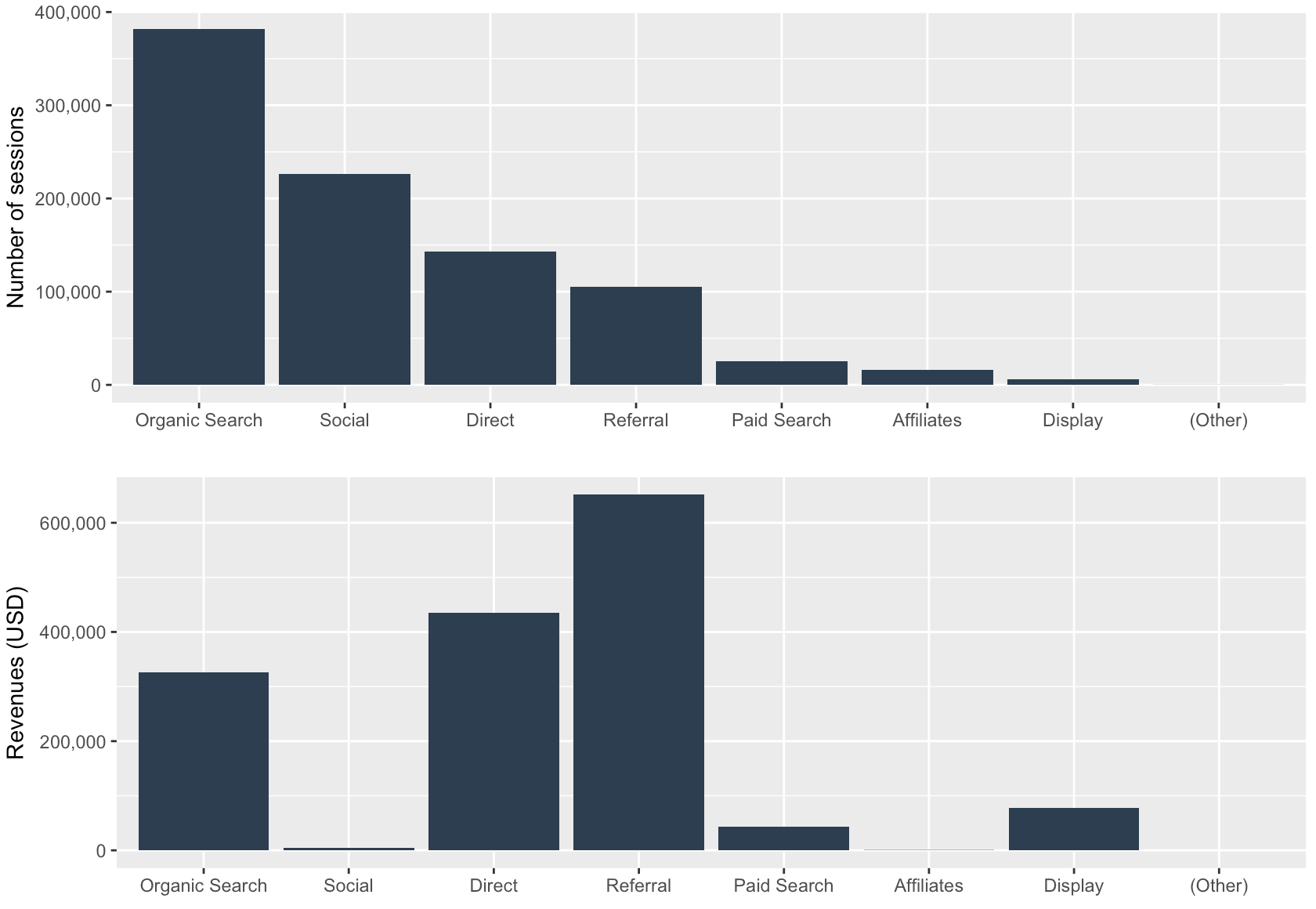
The Takeaway: Organic Search and Social have a high number of sessions, with social producing very low revenue. Referral produces the most revenue, with a relatively small number of sessions.
2.8 Pageviews; All Sessions
A pageview indicates each time a visitor views a page on your website, regardless of how many hits are generated.
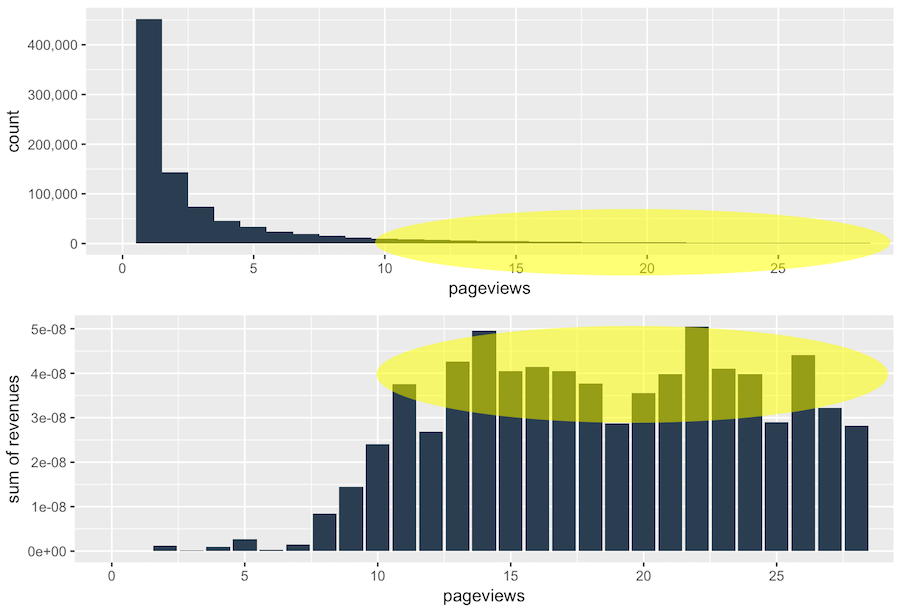 Most revenue relates to a low number of pageviews.
Most revenue relates to a low number of pageviews.
The Takeaway: The distribution of pageviews is skewed. However, the second graph shows that most revenues came from a small number of sessions with a lot of pageviews! It may be that pageviews is a good factor for predicting revenue.
10-Week System: Data Science Education For Enterprise

Learn to analyze data, create machine learning models and solve business problems with our DS4B 201-R Course.
- Learn by following a proven data science framework
- Learn
H2O & LIME for building High-Performance Machine Learning Models
- Learn Expected Value Framework by connecting Data Science to ROI
- Learn Preprocessing with
recipes
- Learn how to build a Recommendation Algorithm from scratch
- All while learning
R coding!
3. Data Preparation
With an understanding of the data, the next step is to prepare the data for modeling.
Data preparation is the process of formatting the data for people (communication) and machines (analyzing/modeling), and perform correlation analysis to review and select the best features for modeling.
Much of this process is code-related, however, below is a correlation analysis that orders variables that are most likely to be good predictors.
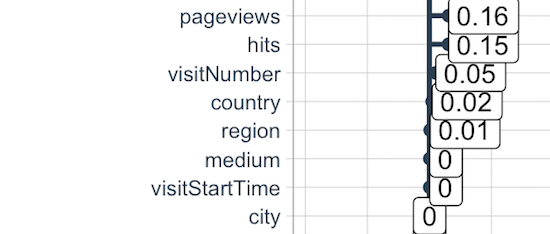 Correlation analysis.
Correlation analysis.
The correlation analysis is important because it gives insight into which variables have a good chance of helping the model. Above, pageviews and hits are two highly correlated (good for predicting) variables.
3.1 Hypotheses – Important Variables
Exploring and preparing the data provided a good understanding of the relationships between customer revenue and other variables in the data.
The following are my initial hypotheses that go into the model:
-
Hypothesis 1: The time of day is an indicator of how much a person spends.
To test this hypothesis, I created a new variable, hour of day. I extracted the hour of day from the store visitor’s session time.
-
Hypothesis 2: Visitor behavior is an indicator of how much a person spends.
The existing data contains each visitor’s number of hits, pageviews, and visits. Along with the individual variables, I created a sum of these and combined them as visitor behavior.
Before modeling, I performed an additional correlation analysis after adding the new variables from Hypothesis 1 and Hypothesis 2.
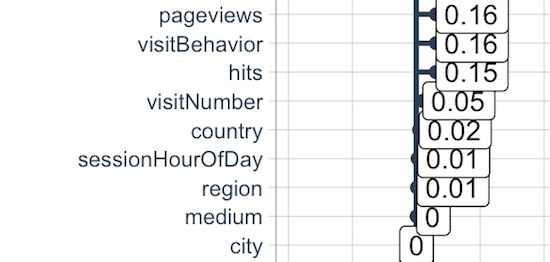 The new visitBehavior variable has a high correlation.
The new visitBehavior variable has a high correlation.
So far the variable visitBehavior from Hypothesis 2 looks correct. From the correlation ranking above, visitBehavior is a good variable for the model to predict customer revenue. The variable sessionHourOfDay from Hypothesis 1, however, is not a good predictor.
Additional hypotheses to be tested (not in the current model):
- New site visits is an indicator of how much a person spends.
- A time-series approach will produce a more accurate model.
- Address holidays and big sales days (such as Black Friday) to increase revenue prediction. The data does contain spikes in revenue. It would be interesting to see if there is an annual trend in revenue spikes and if there is a geographic trend with revenue spikes.
4. Modeling
Deciding which variables that go into modeling will take into account the EDA takeaways, the correlation analysis, and my own hypotheses. I will be using the automated machine learning library H2O. H2O takes the prepared data and automatically creates several machine learning models. Once the models are created, they are ranked by performance and can be analyzed in detail.
Modeling with large datasets can use a lot of compute resources and take a long time to process. The H20 machine learning model was generated with a low runtime setting. Increasing this setting will help produce a more accurate model.
The top-performing generated machine learning model was a distributed random forest.
5. Evaluation
With the baseline model now complete, I will submit the model to the Kaggle competition for results.

Now that the submission has been completed, I will continue to improve the model’s accuracy by testing additional hypotheses and evaluating model metrics.
6. Impact – Business Benefit
With the machine learning model complete, the Google Merchandise Store can identify customers that generate the most revenue.
Below are the business benefits to identifying high-value customers:
- Reduce customer churn with retention marketing for high-value customers
- Identify likely high-value customers by analyzing existing high-value customer purchasing behavior
- Predict revenue based on high-value customer purchasing history
- Focus product development on high-value customer products
You’ve made it all this way!
Thank you for taking the time to read through this analysis. My purpose for making it is to show how digital marketing can benefit from data science analysis.
It’s not explicitly mentioned in the article, but what really makes this work is having a clearly defined question, sufficient data to answer the question, and a business process to work through the data science problem, such as Business Science Problem Framework.
Although the exercise uses a large dataset, data science can be used to answer questions with fewer data as well.
Author: David Curry
Founder, Sure Optimize – SEO and Marketing Analytics