Time Series Analysis for Business Forecasting with Artificial Neural Networks
Written by Blaine Bateman

In this article, you will experience an end-to-end forecasting project that was adapted from a real business case between a client and consulting firm, EAF LLC. The article showcases time series deep learning using multiple data sources including alternative data, advanced tools like artificial neural networks, with a focus on generating business value: saving a hypothetical client $10.5M with a 10% improvement in forecast performance (results based on a client with $100M in annual revenue).
The article showcases time series machine learning using multiple data sources including alternative data, advanced tools like artificial neural networks, with a focus on business value: saving a hypothetical client $10.5M with a 10% improvement in forecast performance
This is an end-to-end analysis of a real-world project that a leading data science consultant has graciously provided. Blaine Bateman is the Founder and Chief Data Engineer at EAF LLC. He specializes in business forecasting. Blaine is also a student in the Data Science For Business With R (DS4B 201-R) Course offered through Business Science University. Blaine showcases a number of advanced techniques including using Keras to create a cutting-edge deep learning model.
What I like most about this analysis is the process he uses to create business value for his clients, which is the Business Science Problem Framework and CRISP-DM taught in the DS4B 201-R Course. Blaine’s focus is on generating business value in terms of Return-On-Investment (ROI). This is how real-world data science is done.
Contents
This is a detailed article that follows an end-to-end business problem. The article contains the following sections.
You’ll experience how Blaine achieved the following results, which are representative of a real forecasting problem his organization solved.
| Model |
Train Error |
Val Error |
Test Error |
| Linear Regression |
-0.7% |
7.5% |
5.1% |
| Optimal GLM |
-0.6% |
7.1% |
5.2% |
| Linear Network |
3.2% |
-9.4% |
5.2% |
| Neural Network |
3.0% |
2.4% |
-3.3% |
| Average LR/LN/NN |
1.8% |
0.2% |
2.3% |
Summary of Results
Here is the final ensemble model combining multiple times series machine learning techniques.
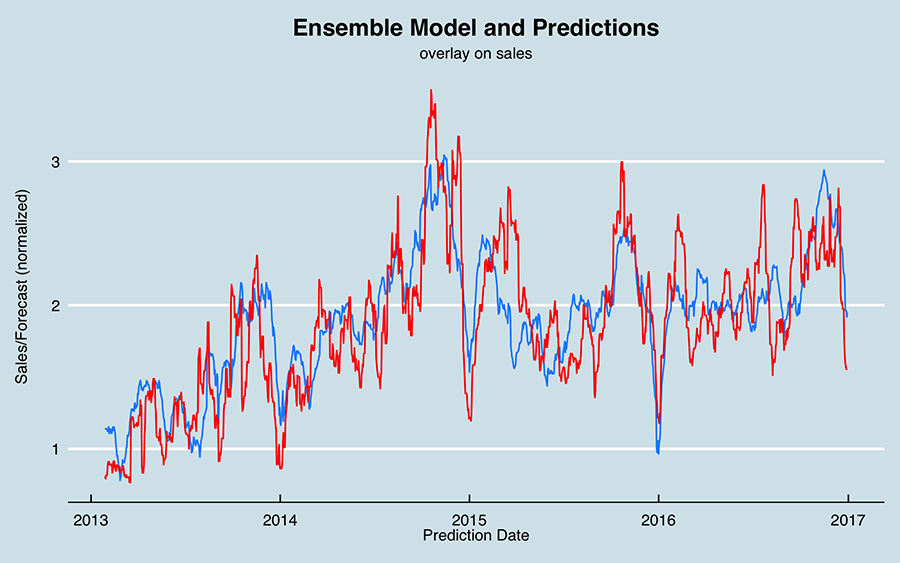
Final Ensemble Model
Get the Data and Code
Blaine has graciously provided all code and data used in the production of his analysis. You can access the data and code here.
1. Introduction
Forecasting is an historical pain point dating back to at least the time of Mesopotamia and even being regulated during the Roman empire. Unfortunately forecasters have been persecuted through the ages; a recent example being the charging of scientists and their managers with manslaughter in Italy for failing to warn of an earthquake (fortunately they were exonerated). In their excellent book “Forecasting Principles and Practice”, Rob Hyndman and George Athanasopoulos note the perils of being a forecaster, quoting Emperor Constantine’s decree in AD357 forbidding “to consult a soothsayer, a mathematician, or a forecaster” (note the historical lumping of math in with fortune telling!).
2. Problem Statement
In this article I want to demonstrate some methods of time series forecasting that are less often cited in the myriad data science tutorials etc.; namely the use of regression models, including artificial neural networks, to forecast. I will describe a business use case adapted from a client engagement, where the goal was to forecast sales up to a year in advance for a specialty electronics manufacturing firm in the B2B segment. Some aspects have been adjusted or simplified for confidentiality reasons, but everything shown here is based on anonymized data using the methods described.
The data used are from 2012 through 2016; the end product was used to forecast into 2017. I arranged the training data as one block of dates from 2012 through 2015, the validation data as 1/1/2016 to 6/30/2016, and the test data as 7/1/2016 to 12/31/2016. This was a pretty challenging task but made sense based on the business case, as I’ll explain later.
While simple methods like ARIMA can be highly effective in short-term forecasts, they are not as well suited if, say, I want to forecast sales with daily granularity several months (or more) into the future. One reason for those limitations is that business phenomena are impacted by multiple forces including the internal business activities, the behavior of customers, the macro behavior of the vertical market, larger macro-economic forces, government regulation, and nowadays even social-media and reputation factors. Modeling the future using only the past values of a time series of figures cannot possibly take into account these external forces as they change over time. On the other hand, using a multivariate set of predictors and modeling with regression tools can incorporate nearly all business knowledge found relevant to the outcome desired to forecast. The challenges become uncovering all the causes and effects, and their timing.
In this context, using these methods fits perfectly into the Business Science Problem Framework (BSPF) and CRISP-DM.
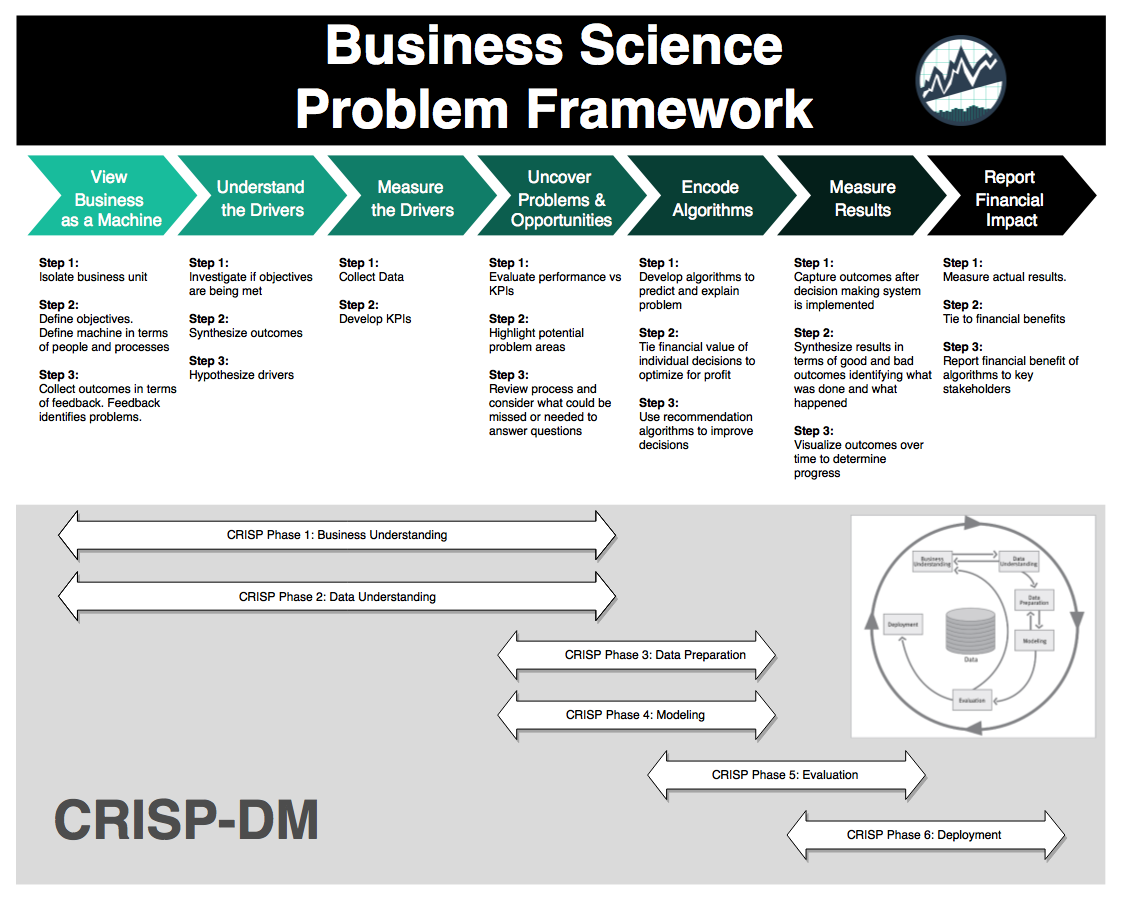
Business Science Problem Framework (BSPF)
3. Business Understanding
The client wanted to improve their sales forecast for several reasons. Stock analysts are very negative when results miss targets, and shareholders get restless when share prices fall. In recent quarters, sales had missed forecasts–but that was only part of the story.
More urgent was a situation that inaccurate forecasts meant some orders were delayed in shipment because some products were selling significantly above forecast while others were below. This was exacerbated as some manufacturing was done by a contract manufacturer, causing further delays when shipments didn’t match the operations forecasts provided to them.
3.1 Project Goal
Since earnings reports are quarterly, forecasts longer than 90 days were desired; in combination with the manufacturing issues, the goal was to forecast to 6 months at 10 percent accuracy and hopefully better in the short term. The goal was to generate something like Figure 1.

Figure 1. Optimistic goal of forecasting project.
The green line is the mean forecast; the dotted lines represent a confidence interval to be determined. At any point the forecast is represented as a probability distribution (possibly unknown); on the right is the interpretation of the hypothetical distribution in the middle of the time frame.
3.2 Project Benefit (Business Value)
To establish Business Value (Return on Investment, ROI) for the forecasting project, it is necessary to estimate the impact of forecast errors. Impacts of, for example, under-forecasting, include canceled orders (due to inability to meet requested delivery dates), cost of carrying excess material as a hedge against the forecast errors, overtime to build late orders once material is available, etc.
Table 1 is an example calculation for a hypothetical business for one under-forecasting scenario. I’ve weighted the reactions to reflect that the response isn’t the same for all customers etc. The result suggests in this case about a 1% of sale impact for every +/- 1% error in the forecast. I could refine this with more discussion with the client; examples include quality impacts of overtime use, customer churn due to missed delivery dates, and any number of other factors.
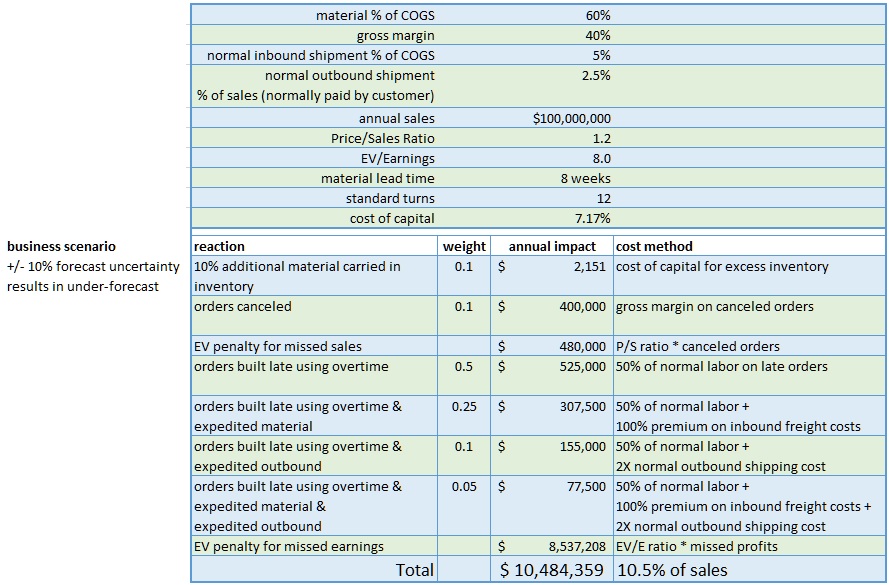
Table 1. Forecast Error Impact Example Calculation
Here a hypothetical $100M (sales) company with a +/- 10% forecast uncertainty takes a range of actions when under-forecasting results in inability to meet customer requested ship dates.
3.3 Data Sources
The data available from the business were as follows:
| Data Type |
Source |
Format |
| CRM |
SFDC |
csv export |
| ERP |
proprietary |
csv export |
| prior forecasts |
Sales |
Excel |
| prior results |
Sales |
Excel |
Table 2. Data sources from the business.
- CRM = customer relationship management system
- SFDC = SalesForce
- ERP = enterprise resource planning system.
In discussion with the client, they explained that they tracked their sales by subsets of sales managers; these subsets were a combination of geographic and market based. In addition, there were hundreds of item numbers (SKUs) that were organized into a set of groups. Eventually we agreed to include 9 sales areas and 10 product groups in the project. The data provided per Table 1 were intended to support this structure in the analysis.
To understand the business relationship of the data it’s important to consider a few realities. Most business people and sales professionals don’t have formal education or training in forecasting, instead substituting on the job experience and professional judgement. These skills can be surprisingly useful to produce accurate forecasts, but it can also lead to large errors, and no way to gauge the uncertainty of the forecasts. We decided after discussion to approach the confidence interval part of the project by reconstructing past forecasts and errors in discussion with sales, then using a Monte Carlo method to estimate the forecast distributions. Although I won’t go deeper into that method here due to length constraints, it’s explained in an article I wrote.
CRM data in B2B companies often do not reflect all the future business expected, but only major new opportunities. Sales may include a large recurring or carryover business in the forecast that is not in the CRM. In addition, there may be significant sales that are handled by Customer Service or Inside Sales that may be viewed as “drop in”. In this case, it seemed clear that the future sales depended on all of these, and I wanted to account for the CRM portion explicitly. The other sources would be reflected in the sales history. However, many companies have no explicit process in place to include CRM into the forecast–it is up to sales to decide how this is done, and it may be very ad-hoc. The issue is important in the business understanding phase–CRM reports are often used mainly to manage sales and not for forecasting. I chose to attempt to estimate the average “lag time” between opportunities in the CRM at various stages and future revenue. I’ll discuss this more in the Data Understanding section.
3.4 Alternative Data (External) and Stakeholder Communication
Another point to consider is that in business, forecasting is often confounded with goal setting–in other words, if the CEO says ‘We need to sell $300M next year’, then the forecast is forced to be at least $300M for next year. This often results in one or more line items labeled TBD, stretch, or other euphemisms meaning ‘we don’t know where this revenue is coming from’ (at the time of the forecast). The challenge for analyzing history and forecasting using a model-based approach is that past forecasts and errors may have large biases in them, affecting understanding of uncertainty and risk.
One of the things I wanted to accomplish was to incorporate business knowledge explicitly into the forecast. This can include asking what markets the business is in, and seeking external data regarding the behavior and growth of those markets. If such external data are available, they can be incorporated as a predictor in the model data. Other examples include government regulations that may negatively or positively impact the business, overall health of the economy in which the company sells, and commodity prices that may affect the business levels of customers. After several discussions with various stakeholders, I decided to look at three factors: industrial activity, manufacturing capital expenditures, and pricing of a commodity. The business motivations for these are as follows. Most sales were B2B into industrial or manufacturing customers, so a measure of industrial activity might correlate with sales. Also, since significant sales were known to go into manufacturing operations, spending to install new manufacturing capacity might be a good sales predictor. Finally, due to large sales into one industrial segment involved with the production of a commodity, it was believed that global price increases in the commodity drove increased spending for production equipment in the segment. In the data understanding discussion I’ll talk about challenges of incorporating these factors.
One has to talk to a lot of stakeholders to get all the information I’ve discussed. One thing I like to advise those in similar situations is to not assume you have all the relevant information. Stakeholders may forget to tell you something important, or decide it’s not relevant and omit it. In addition, different stakeholders may use different data as the truth and you may get divergent answers to similar questions. My approach is to just keep asking questions throughout the project, and engage as many stakeholders in the client as possible.
“My approach is to just keep asking questions throughout the project, and engage as many stakeholders in the client as possible.”
4. Data Understanding
There are 3 areas of data that impact this problem:
-
CRM Data: Customer Relationship Management including data on where prospective sales are in the sales funnel
-
ERP Data: Data contained in an Enterprise Resource Planning database, which contains sales history (i.e. orders, products purchased, customer purchase history)
-
Alternative Data: Data available that is external to the organization including commodity pricing, manufacturing indexes, and other non-traditional data sources
This section discusses each data sources. It ends with a brief discussion on how to select features and combine the various data sources.
4.1 CRM Data
The CRM data represented the “sales pipeline”, each entry representing the future sale of one product to one customer, organized into one of six sales stages, labeled as 0%, 5%, 25%, 50%, 75%, 90%. As is typical, the percentages don’t represent probabilities, so it is better to think of them as simply labels, which are usually called stages. This complicates the interpretation of the pipeline and the use of it as input to the forecast, as I’ll discuss later. In addition to the “open” pipeline, historical data were available including wins and losses, the time to close from creation, and the stage history for every closed item.
I don’t have enough room or time here to fully discuss the analysis of the CRM data, so I’ll just summarize a few points here. First, if I consider the life cycle of one item in the CRM (call it an ‘opportunity’), then the opportunity is created when a new business lead is identified, it evolves from stage to stage as more sales effort is applied and (hopefully) it is moving towards a business win, and eventually it is either won or lost. If I look back at history, I can find some fraction of opportunities at a given stage that are typically won (the ‘closed/won’ rate), and an average time from the point an opportunity enters a given stage to closing. If I am looking at, say, stage 25% opportunities, I might find 30% of them are typically won, and on average it takes 315 days to close them. I can then say that if I look at the amount of revenue represented in stage 25% at some point in the past, I can expect 30% of that to show up as sales 315 days in the future. Therefore, if I can build a time series of the total dollar value of stage 25% versus time in the past, I can use that as a predictor for some of the future sales.
In this case after a lot of analysis and discussion with the sales stakeholders, I decided to use only the stage 25% opportunities. The data preparation then consisted of determining, from the stage history, what 25% opportunities were open for all dates in the past over the date range of interest. This was done according to the sales areas and product groups agreed upon with the stakeholders. The result was simply tabulated data for each area-group combination at every date in the past. To use them in the model, these tabular data were offset by the number of days determined to best represent the average time to close. Here are the (normalized) pipeline data by product group; I’ve added vertical lines at each year boundary to help visualize the behavior over time.
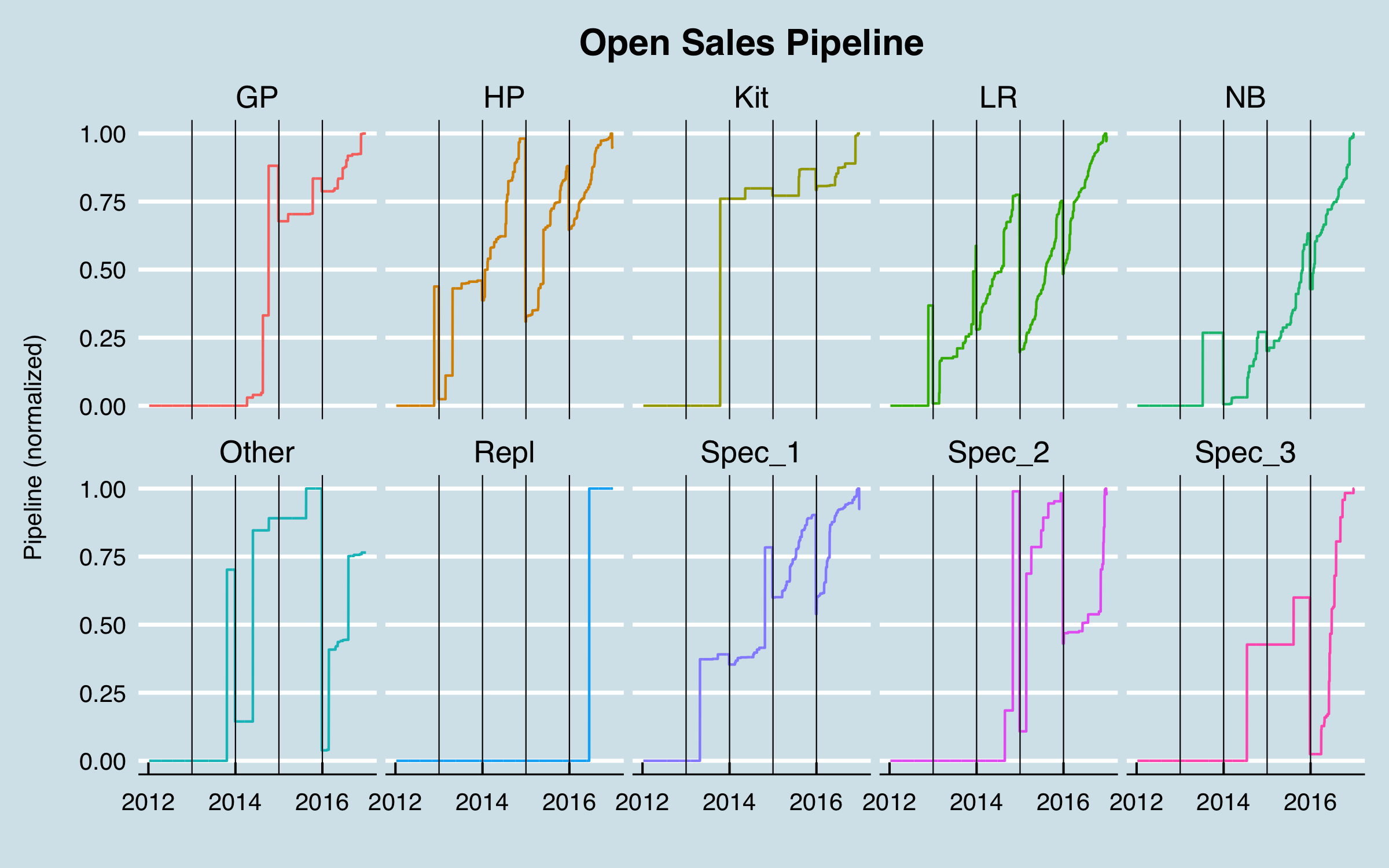
These data have some issues! The “notchiness” of the curves is due to a typical process that occurs in sales management wherein the pipeline is cleaned up periodically–opportunities that are known to be lost but had not been closed are closed in bulk, leading to the sudden drops. It can be seen that this happens often at the end of the year. One group, Repl, has no data until very recently, and others, GP, Spec_2, and Spec_3, have no data until mid-2014 or later. I dropped those from further analysis, leaving this:
-1.png)
Although less than ideal, these data contain important information not otherwise available in the data set, so I retained them. The average time to revenue was found to be 606 days. However, the distribution of time to revenue is not at all Gaussian (i.e. it is not a normal distribution).
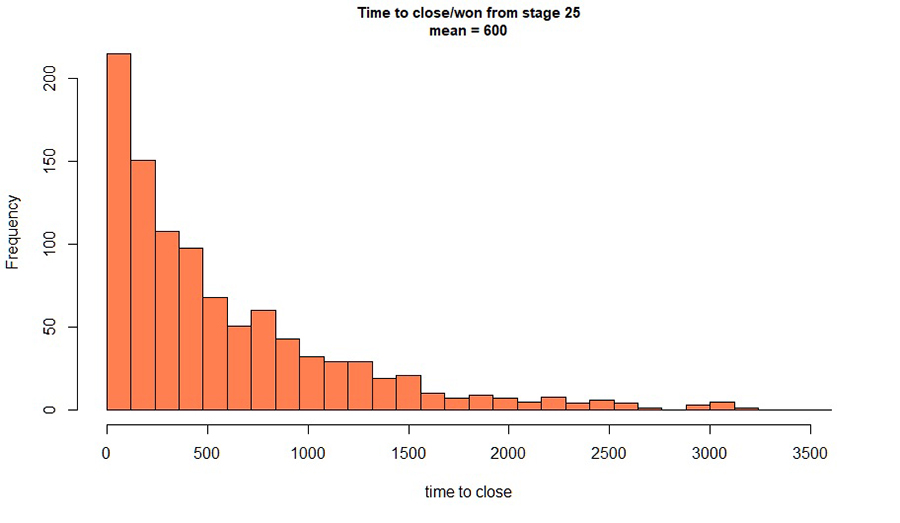
Figure 2. Distribution of time to revenue for '25%' opportunities.
Ideally I would sample this distribution in some way and estimate fraction of revenue at all future dates and use that in the model. For the purposes here, I chose to use the time for which 50% of the revenue would be closed, which was calculated from the distribution as 357 days. (This value was actually taken as a midpoint between two histogram bins; a more precise figure could be taken from a fitted distribution.) This “lag time” represents the time from when an event happens in a predictor (in this case, an opportunity reaches a given stage at a given dollar value) to when it impacts the dependent variable–the values I am trying to predict. Determining lag times from proposed predictors to the future sales I am predicting is a significant theme of this work.
4.2 ERP Data
he ERP data were provided as tabular data with each line representing an order of one unique item (SKU) by one customer on a given purchase order for a given ship date. Since the goal of the project was mainly to improve the Operations situation, I initially focused on ship dates. However, an analysis of the shipments vs. order dates showed that the vast majority of orders shipped very soon after they were placed; in most cases ship dates long after order dates represented problems where materials or production capacity were not available in time to meet customer needs. Ultimately, I reverted to forecasting order dates after agreeing with stakeholders that this was the visibility they needed.
As with the CRM data, I won’t detail all the steps required to prepare the ERP data for use in the project, but will touch on some important points. I found some erroneous dates in the data provided, flagged because the order dates were after the ship dates. In discussion with stakeholders, this was confusing as there was no process to allow orders to be entered after shipments. As a working solution, it was agreed to just use the order dates as the “truth”. In addition, the ERP was not coded with the areas or product groups that had been agreed to as the granularity of the project. This is not unusual–sales may have their own definitions to manage sales activities, but the ERP is coded with “official” (and sometimes cryptic) categories. In this case, neither the sales areas or the product families were included in the ERP data. This required additional data cleaning and preparation steps wherein lookup tables that matched customer IDs to sales areas and item numbers to product groups were used. This raised another issue in that the totals by area and some product groups did not match the historical data provided by sales. A first round analysis was completed with the understanding that the discrepancies would be resolved later as a possible refinement.
With these caveats, a tabular data set comprising the order dates, areas, product groups, and CRM pipeline was prepared. I now look at one additional aspect of the sales data to consider. Here is a plot of the (normalized) raw sales vs. date:
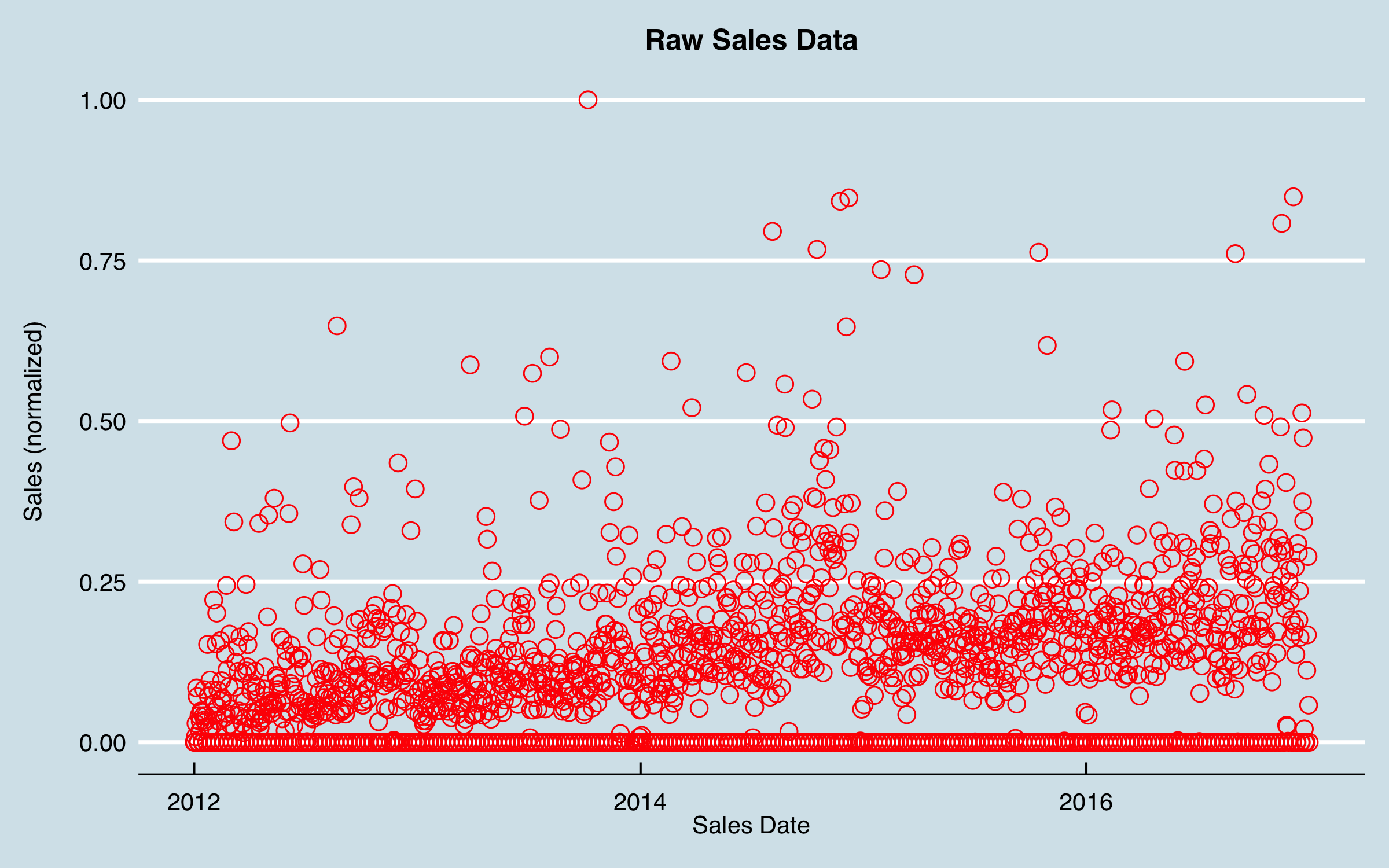
Although I can see a fairly clear trend, the data are very noisy, and it’s not evident there are patterns that can be modeled. I could jump into some autocorrelation and ARIMA analysis, but I decided to try an old tool–smoothing–before anything else. Also evident in this chart is that there are may dates with zero sales. These values were due to no data on most weekend and holiday dates, as orders are not taken and entered on those days. I knew that there were likely to be monthly and quarterly cycles due to sales goals, and I didn’t want to smooth those out too much. I decided to use a 21-day moving average as a first approach, using uniform dates (i.e. filling in the missing dates); the data then appear as follows.
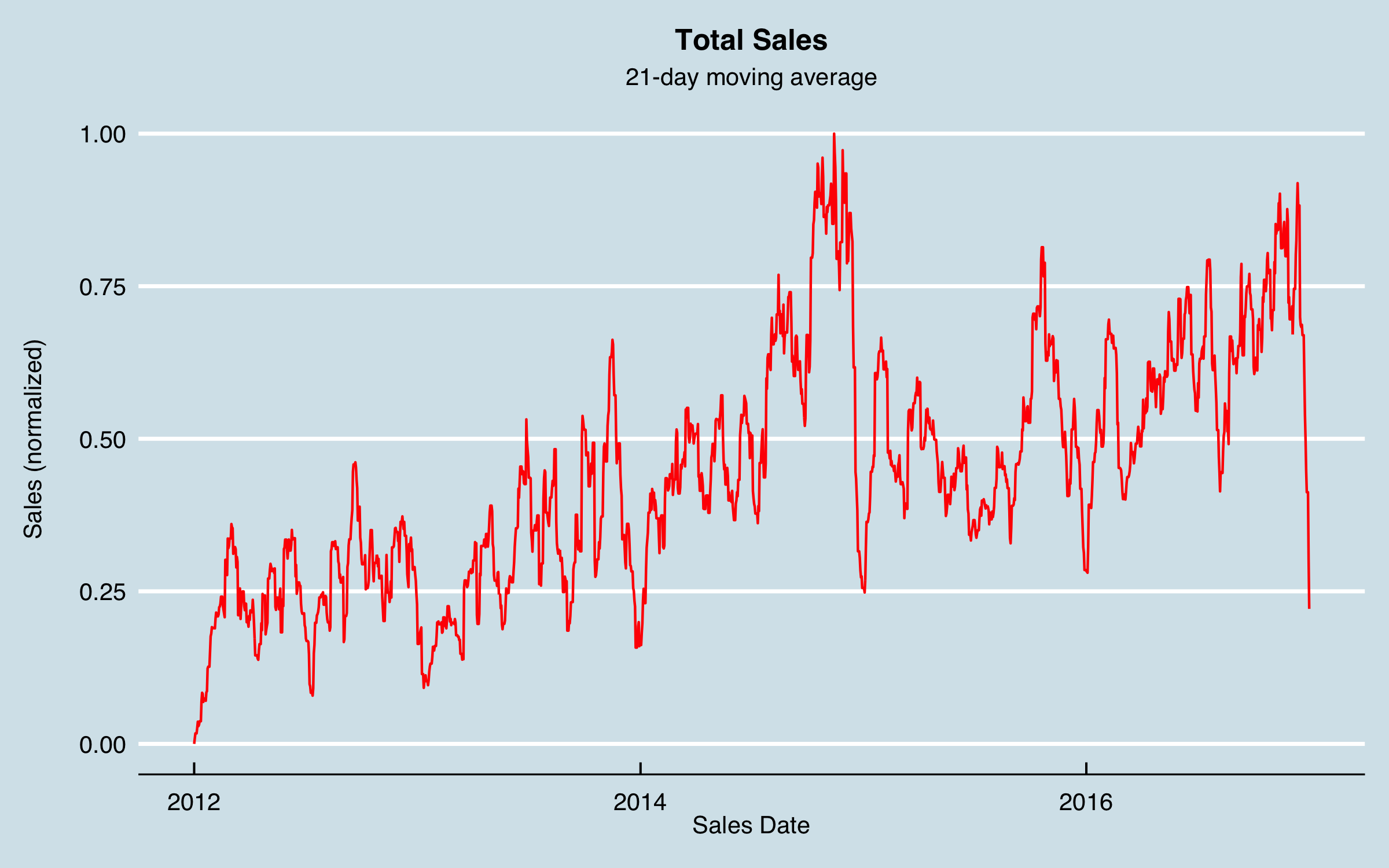
Now I can see something of a pattern–there are big dips at the end of each year as well as some possibly recurring patterns within the year, including monthly, albeit noisy and not consistent. I chose to move forward modeling the smoothed data as the target output. Note that with some error, the forecasted moving averages can be converted back to weekly data, by distributing the weekend and holiday values back into the actual sales days. However, for understanding, say, sales by month or quarter the forecasted values could be used as is.
Consider this series for a moment. Most “textbook” time series examples are clearly periodic, sometimes growing, and sometimes with one big shift. In comparison, this modeling challenge is really hard. Although there are some patterns, it’s clearly not a given I can forecast this. That’s the point of this article, to explore methods that can generate predictive power for complex problems like this. I believe every business related time series has causes, and our job is to find them and build a model that accounts for the causes and predicts the business.
From this figure I see there are clearly annual and likely more frequent recurring patterns. I performed a Discrete Fourier Transform (DFT) to look for the dominant recurring frequencies, and found evidence of 6-month and monthly cycles, a cycle around 102 days, as well as less-intuitive cycles at 512 days. For the 102 day cycles I chose to use 91.3 days (roughly a quarter year) as being more consistent with the business understanding. While I thought the model would likely pick up the key frequencies based on the business cycles, I decided to provide periodic predictors using sine and cosine series tied to the day of the year. In addition, I used a mathematical technique as follows:
Define the sine series as:
sin(2 * \(\pi\) * (cycles/day) * time(days))
Then add a second series as:
cos(2 * \(\pi\) * (cycles/day) * time(days))
and by using the two corresponding series in combination in a regression, the model coefficients encode the best fit phase as well as the amplitude. Predicting with only the sine/cosines and the date using a linear regression model fits a surprising amount of the variation:
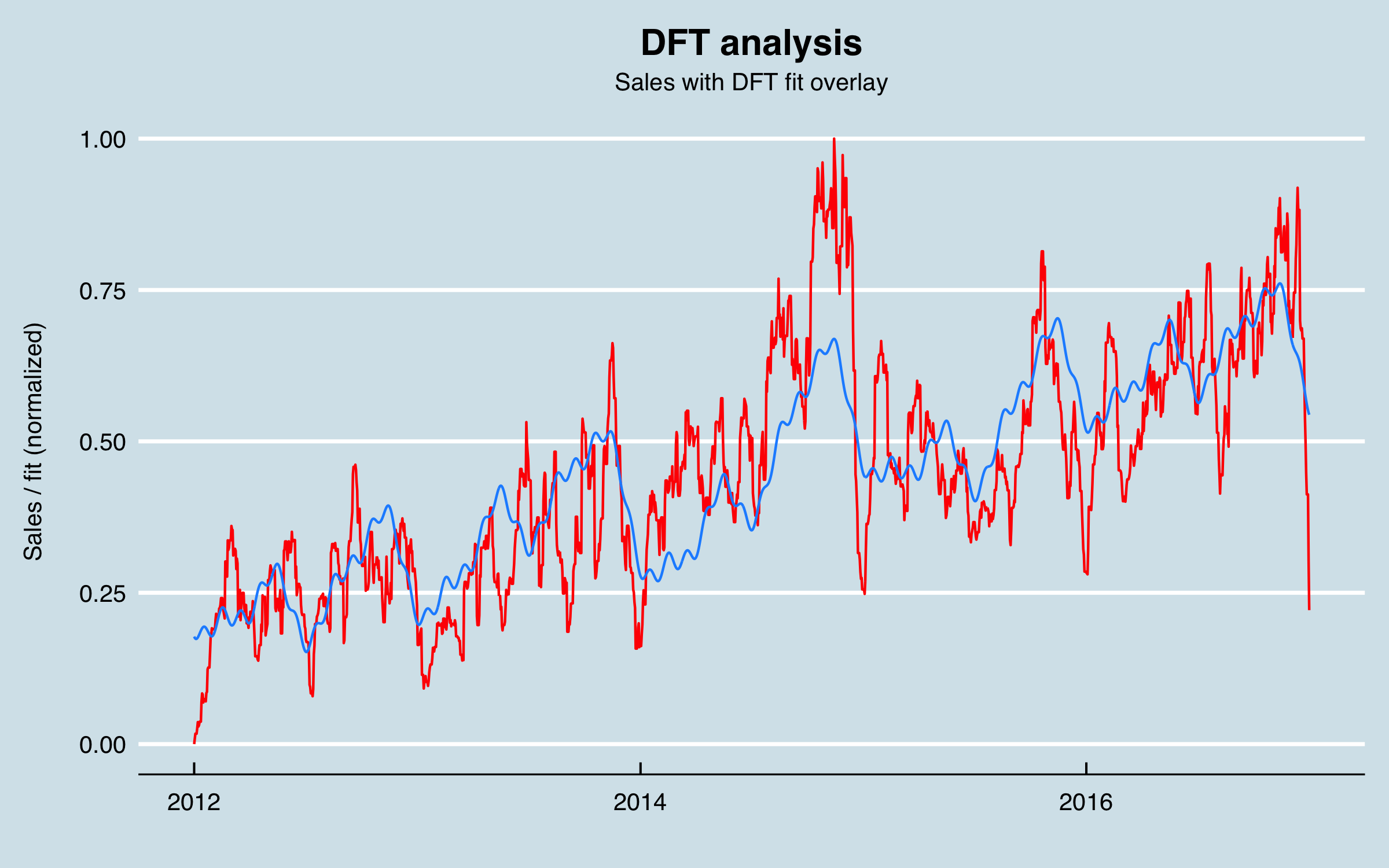
A word of caution using DFT and related methods to fit sine/cosines to a time series. These approaches can dramatically over-fit; that is, if I did a full frequency based reconstruction of the signal, it could perfectly match the training data, but when extended outside that region it would simply be a copy. Therefore, my approach is to use these predictors for a limited number of frequencies.
With this analysis, the data set now includes a day column and 10 columns with the calculated sine and cosine series (normalized), along with the previous data. Also, the sales area was encoded as a dummy variable, and the sales amounts by date-area-group were recorded in columns for each product group. At this stage I also encoded the day of the year (1 - 366), the day of the month (1 - 31) and variables indicating weekend and non-working holidays. The reason for these latter variables is based on my experience and data understanding that the model could use this information as predictive.
I now look at the autocorrelation of the sales data, to investigate if I can use lagged sales data to predict future sales.
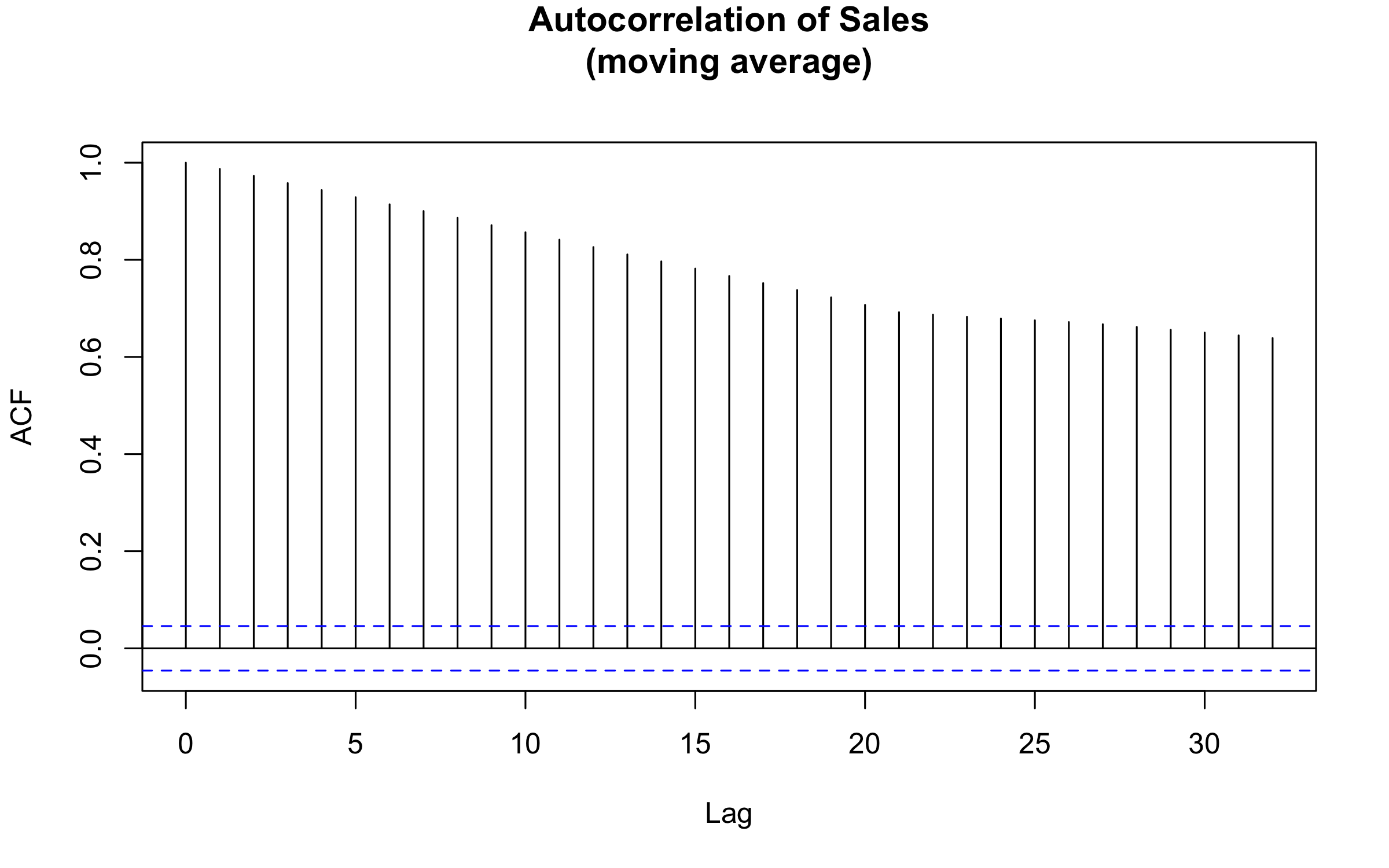
This result isn’t surprising for a couple of reasons. Like a lot of time series, the data are highly correlated at small lags. Unfortunately, this isn’t helpful for the business case, since I need to forecast at up to 6 months. In addition, I can see that the 21-day moving average increases the correlation up to that lag period. However, here is what results when extending the analysis to much longer lags:
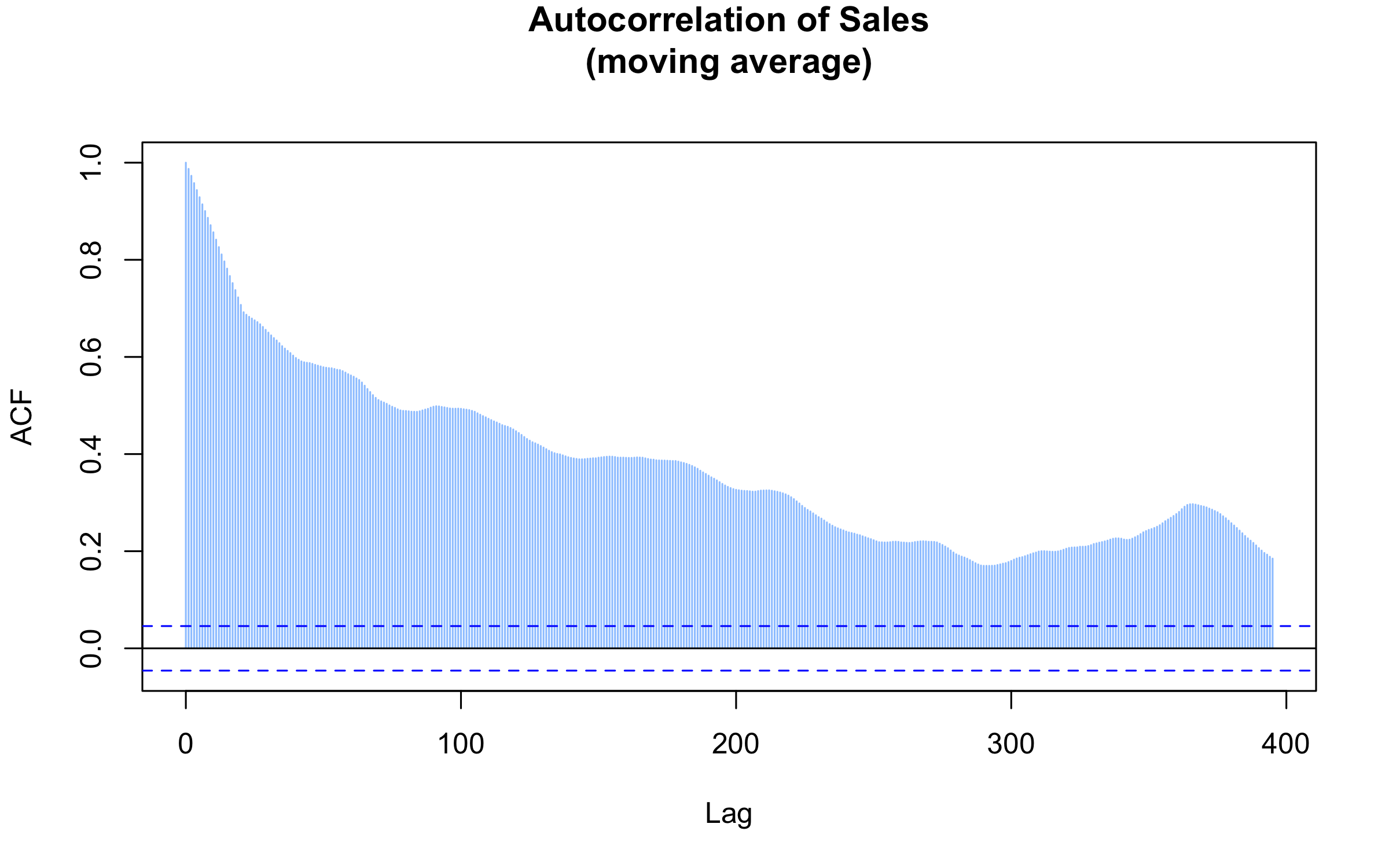
Happily, there is a peak in the correlation at one year! That means I can use sales data lagged one year to predict sales, at least in part. I’ll return to this later in data understanding.
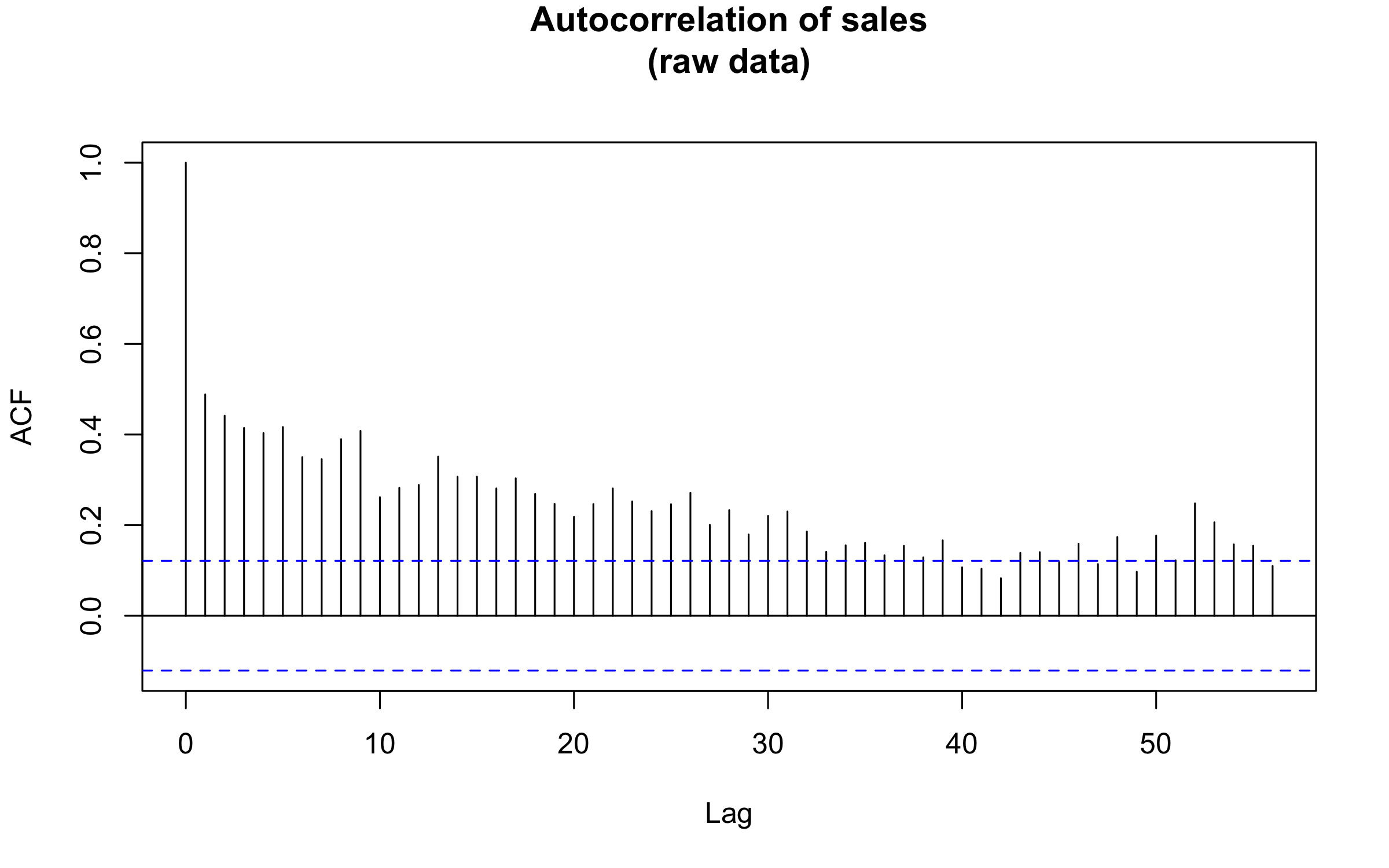
One reason for using the moving averages are the gaps in the sales data as orders are not entered on weekends or holidays. However, to sanity check the previous result, I can aggregate the raw data into weekly data without any smoothing, and perform an autocorrelation analysis on that. The result is shown here; 52 weeks appears as a long-lag peak in correlation, consistent with the previous result.
Further, before I get fully into modeling, I will predict the Sales figures with the 365-day lagged sales to do a preliminary validation that using such a long lag is useful. On the left are the original and lagged sales data, and on the right the result of fitting a linear model with the date and lagged sales as predictors.
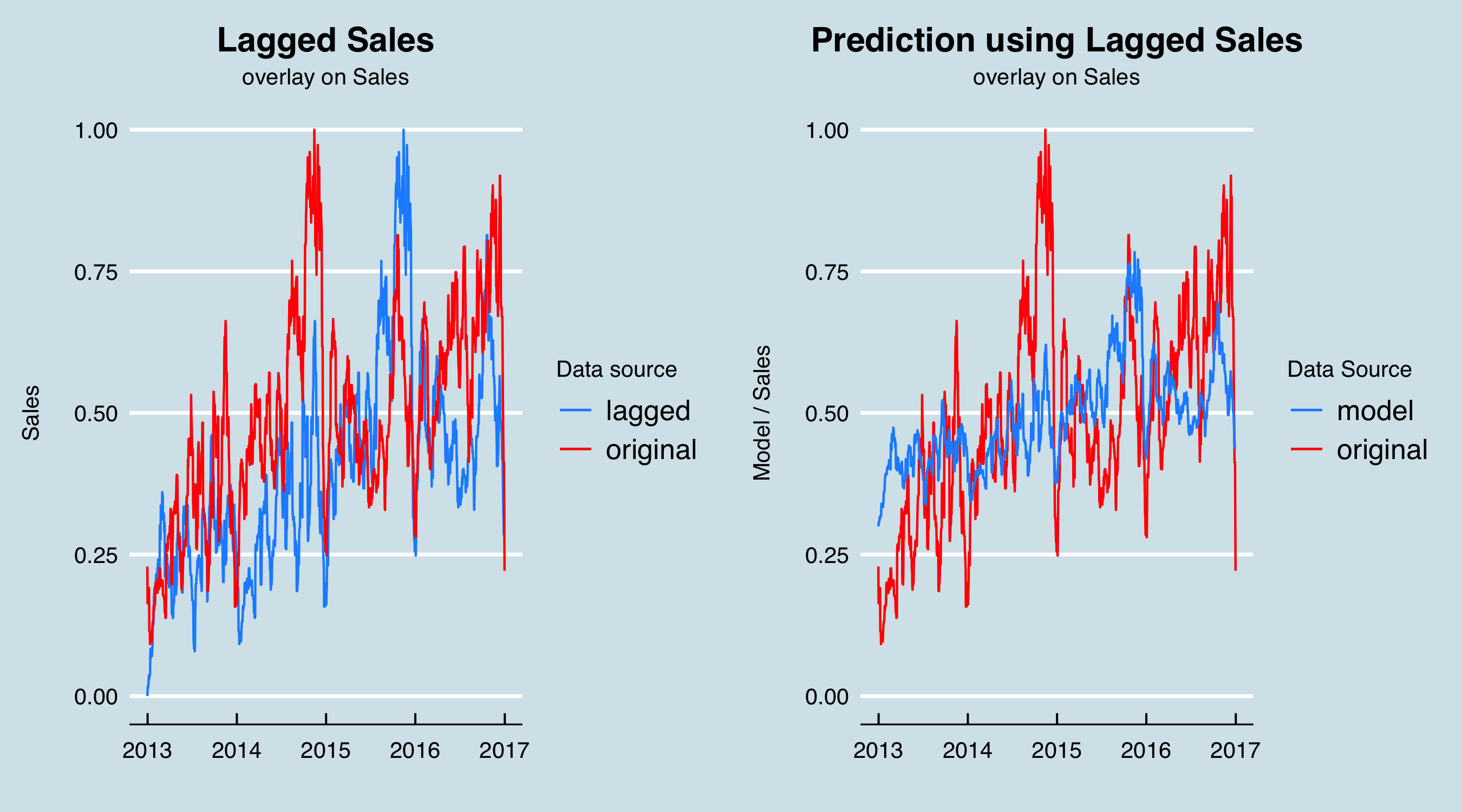
The residuals from this simple model are a good approximation of a normal distribution:
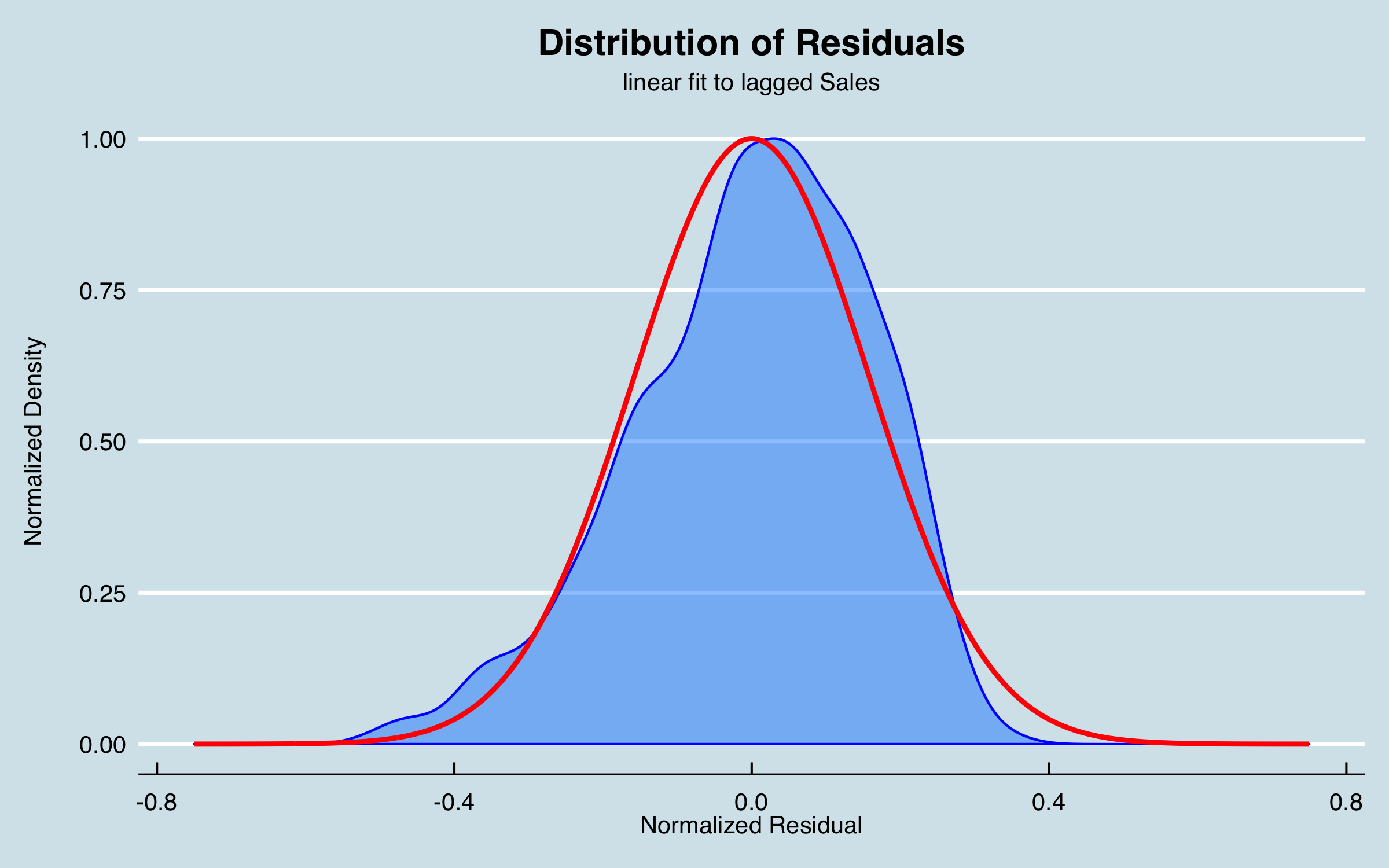
4.3 Alternative Data (External Factors)
The next part of Data Understanding is to consider external factors as mentioned at the outset. In my many discussions whit stakeholders, a large amount of sales in one area was associated with a particular industry, and that industry tended to ebb and flow based on the market pricing of the commodity produced. I obtained data from a government website for the historical pricing (via an API–easily done in R using the httr library and some json tools) which is as follows, plotted together with (normalized) sales. It’s notable that the downturn in the commodity price in 2014 seems to correspond roughly to a drop in sales. Here I have smoothed the sales data somewhat to aid interpretation.
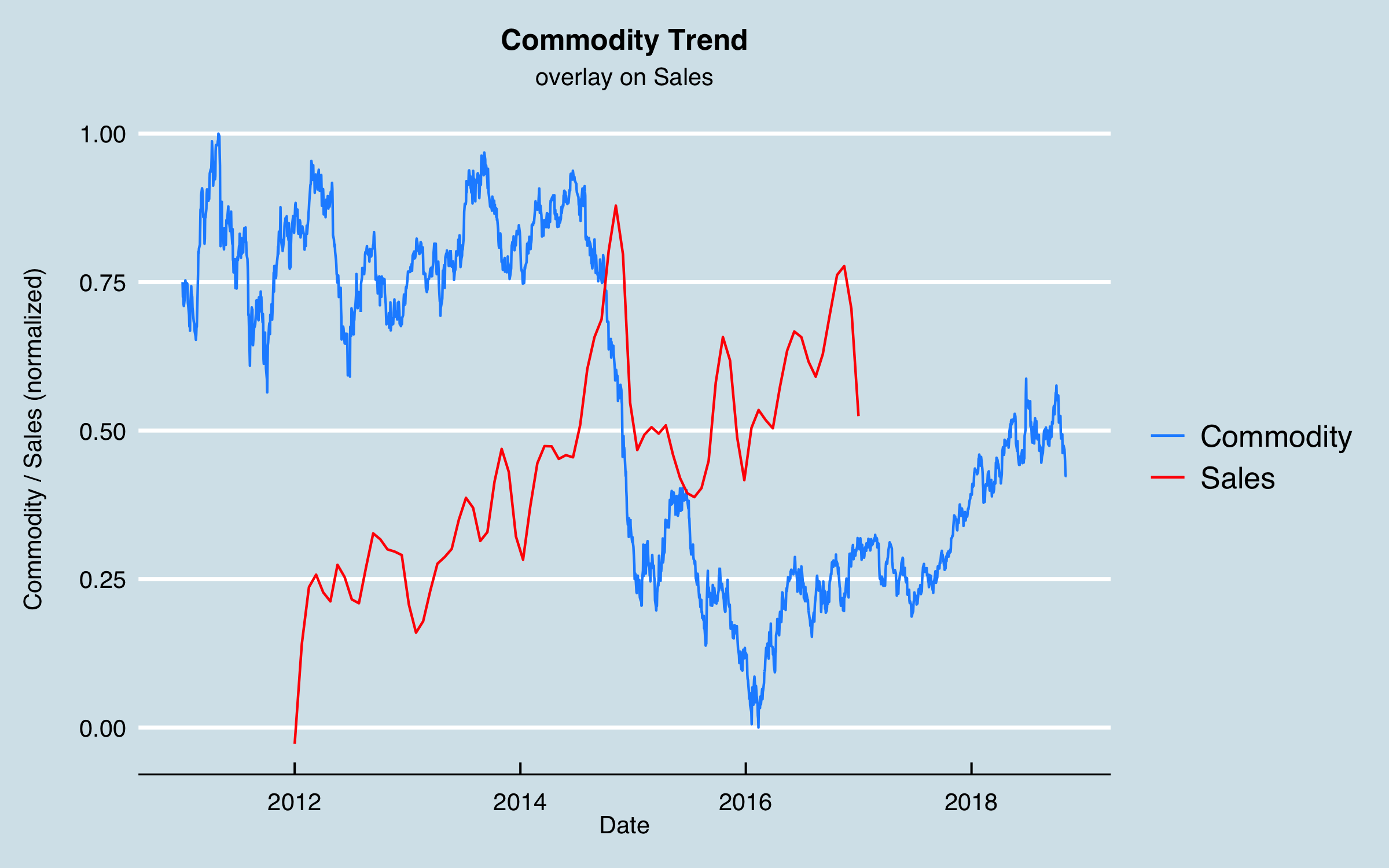
This is a case where something like cross correlation analysis won’t work, as there is a single large change in the data that occurs only once. As an alternative, I tested lagging the commodity data from 0 to 24 months and testing the residuals when I fit the sales data to a linear trend plus the commodity data.
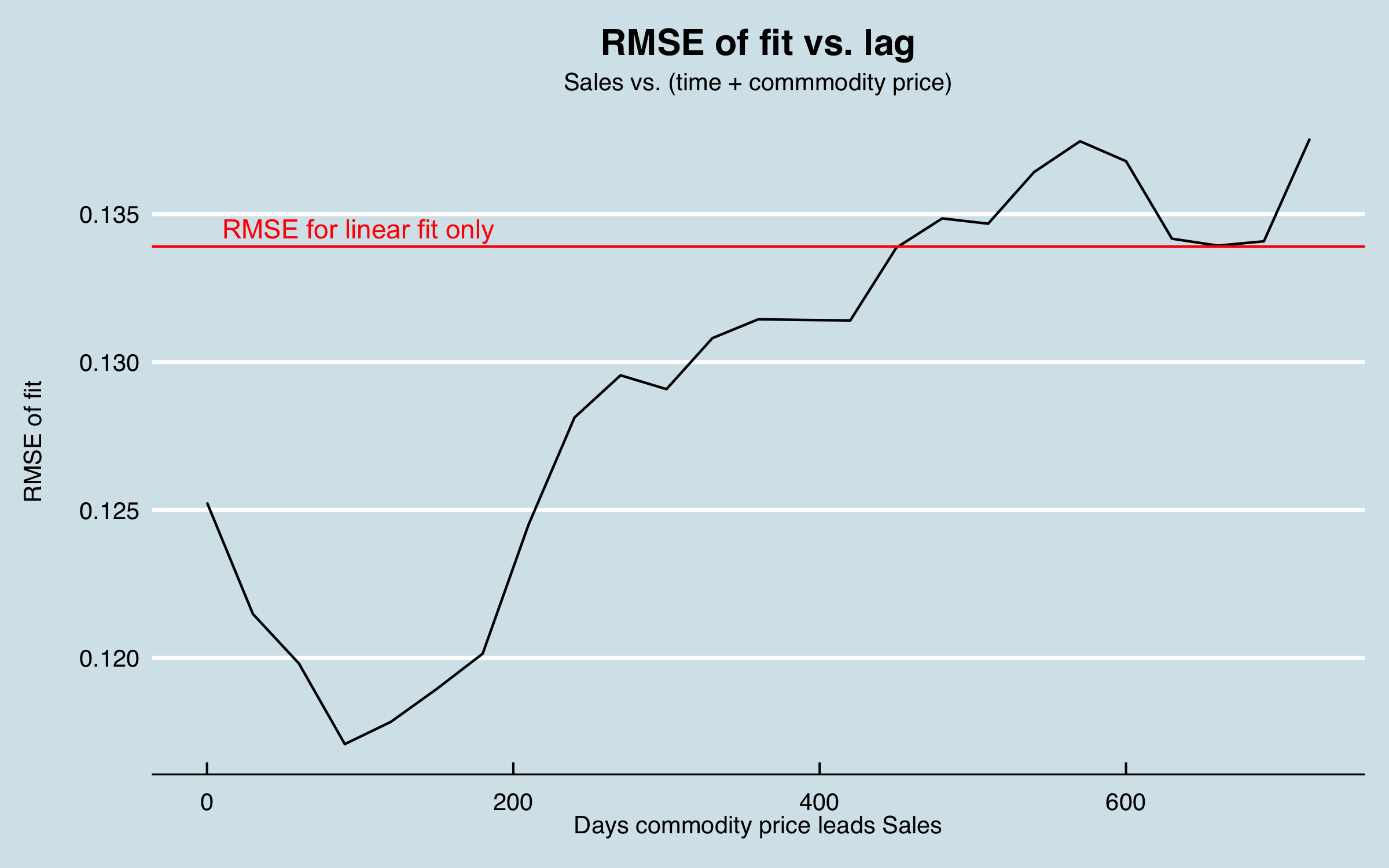
This analysis arrived at a time lag of 90 days. I can interpret this as related to the lag time from when the price of a commodity significantly increases and the time that production of the commodity increases to take advantage, with the order and fulfillment lag time included. Shifting the commodity data this amount and re-plotting gives:
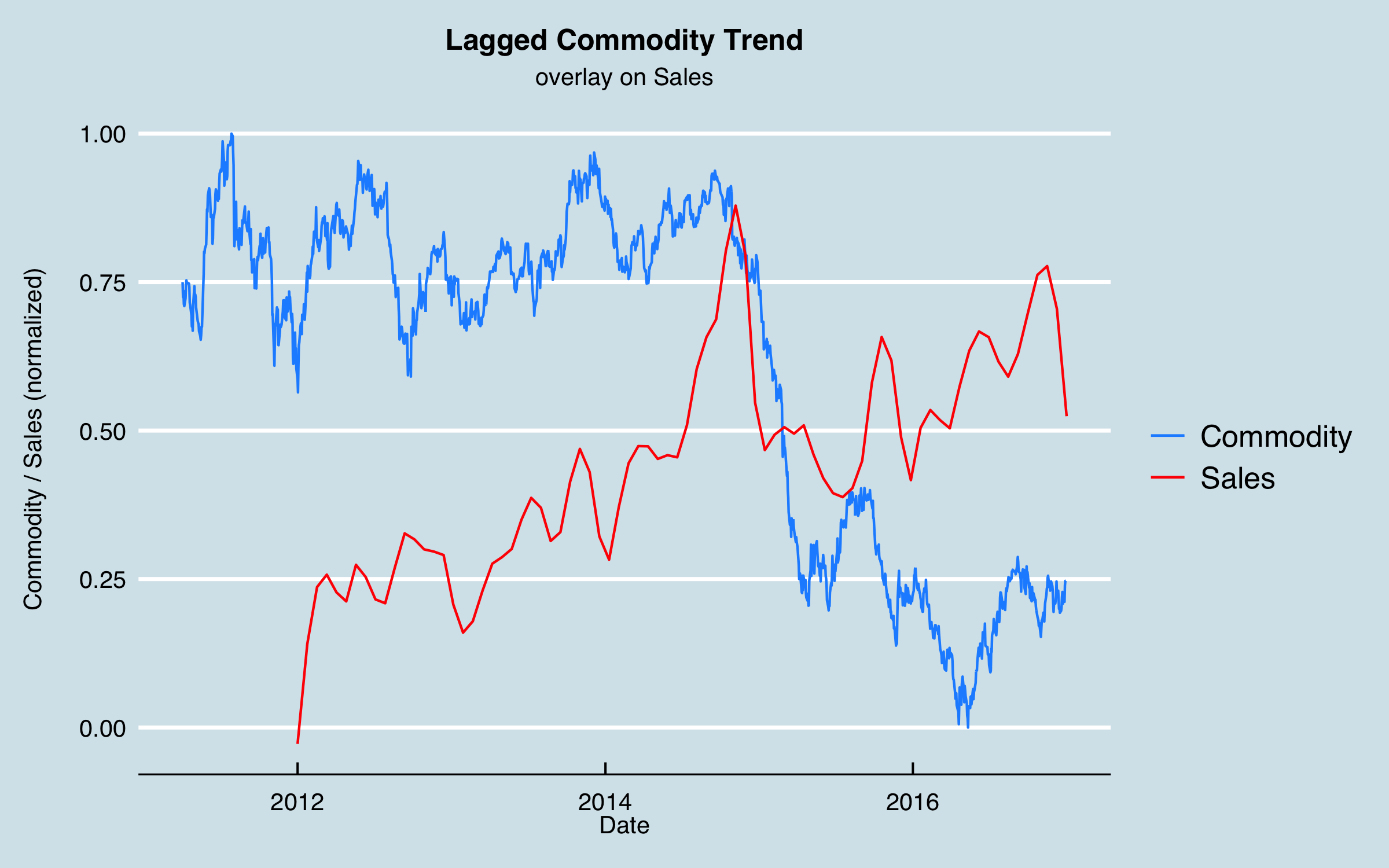
Obviously this isn’t the whole story, but as a sanity check, I compare fitting the sales data with a linear trend (fit vs. date only), fitting using the commodity data, lagged by 90 days, and using both. This shows that including the commodity data can significantly reduce the RMSE and generate residual errors that are more symmetric:
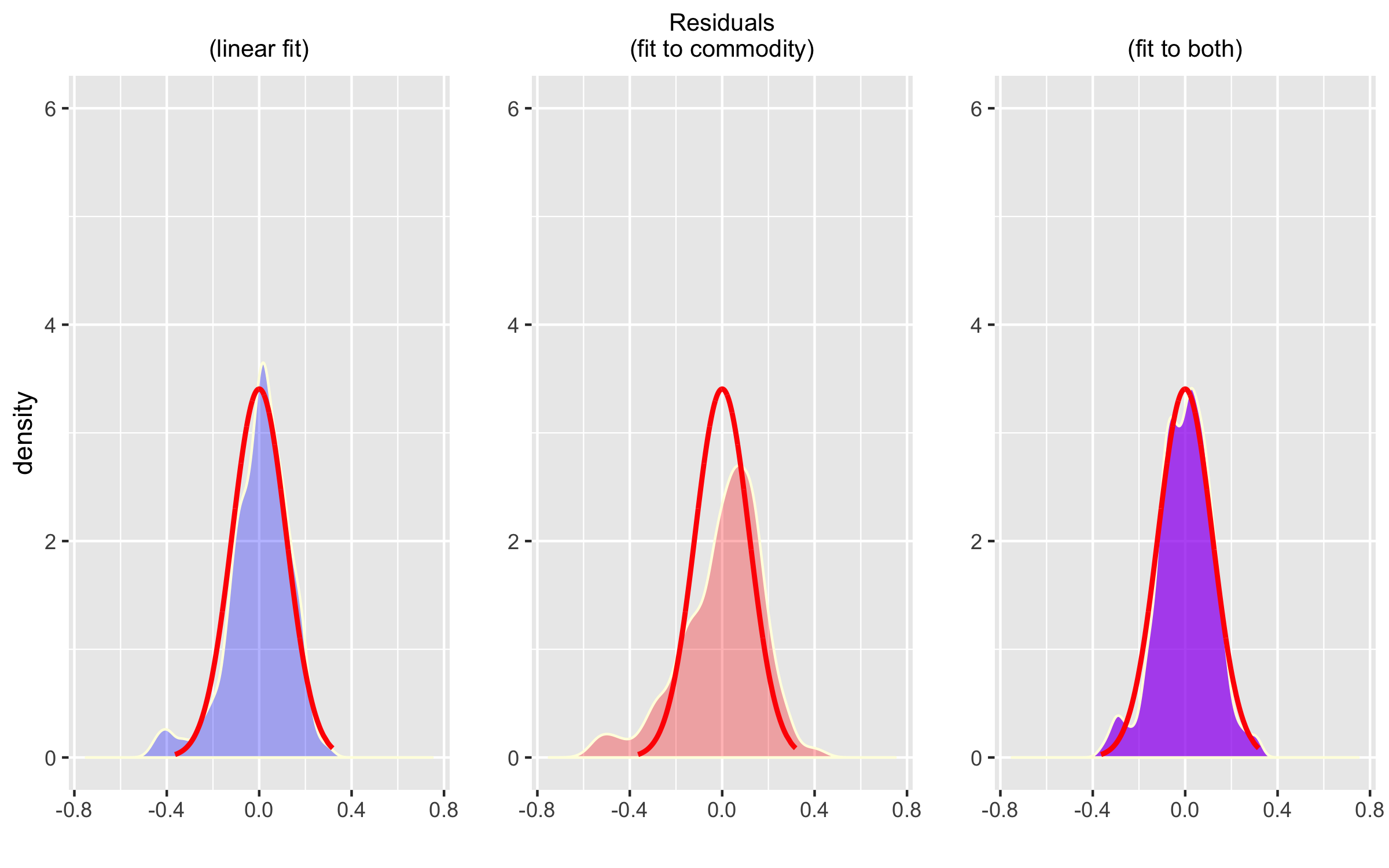
You might have noticed that if the best lag is 90 days, that is less than the desired forecast period. In this article, I’m cheating a bit as I have historical data covering the forecast period. To use this model in production, I would need to forecast the commodity out at least another 90 days. Alternatively, I have used an approach for some commodities to get futures pricing data via an API and use those with their maturation dates as a forecast. (You can see an example of that in action here.)
As mentioned earlier, I was motivated to look for other market or external factors that might explain some of the observed cyclical behaviors. Given that the customers were mainly industrial, I looked for a proxy to represent the level of industrial activity in the economy. I was able to obtain industrial energy consumption data by various sectors, again via a government API, which were normalized into a single index.
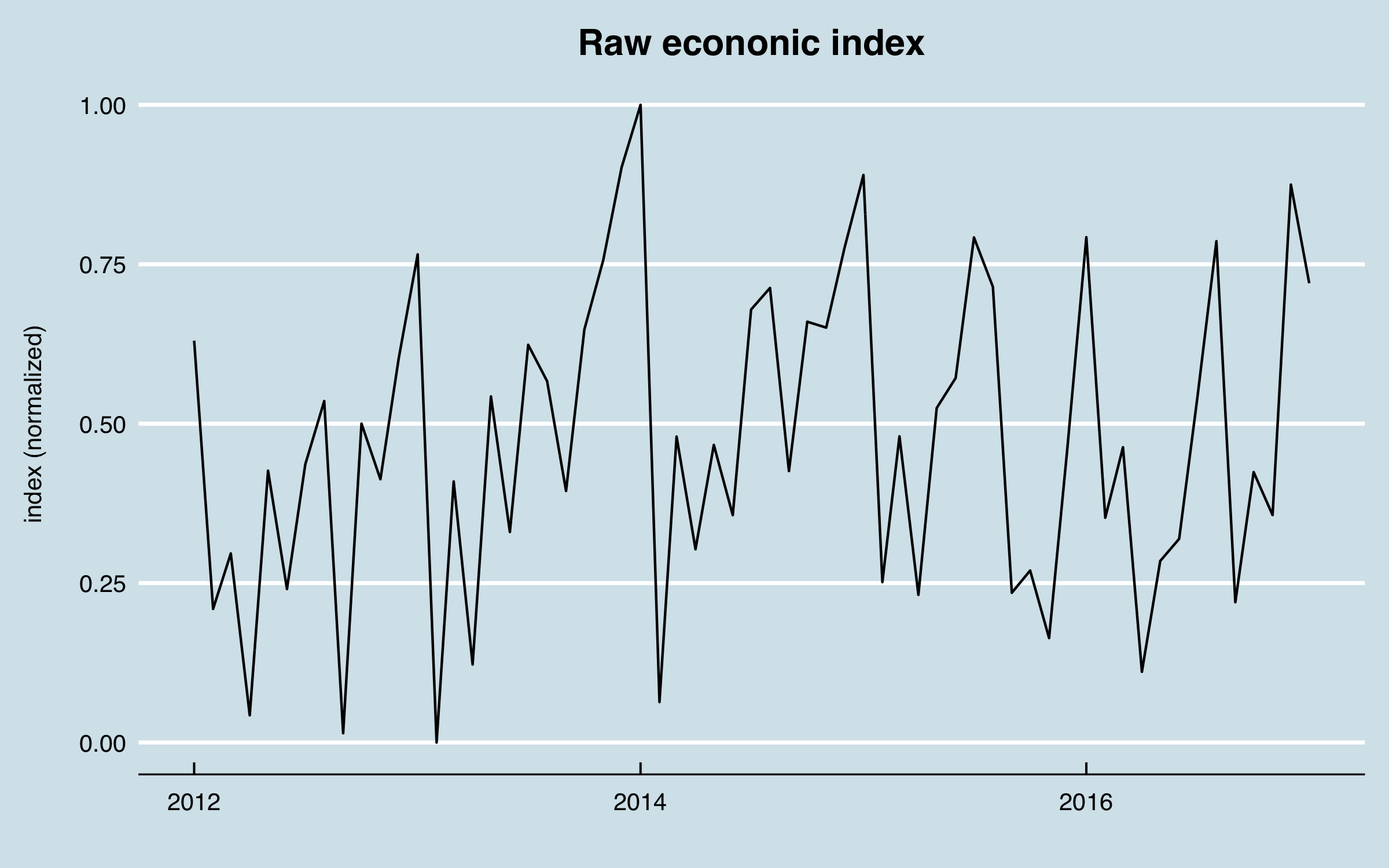
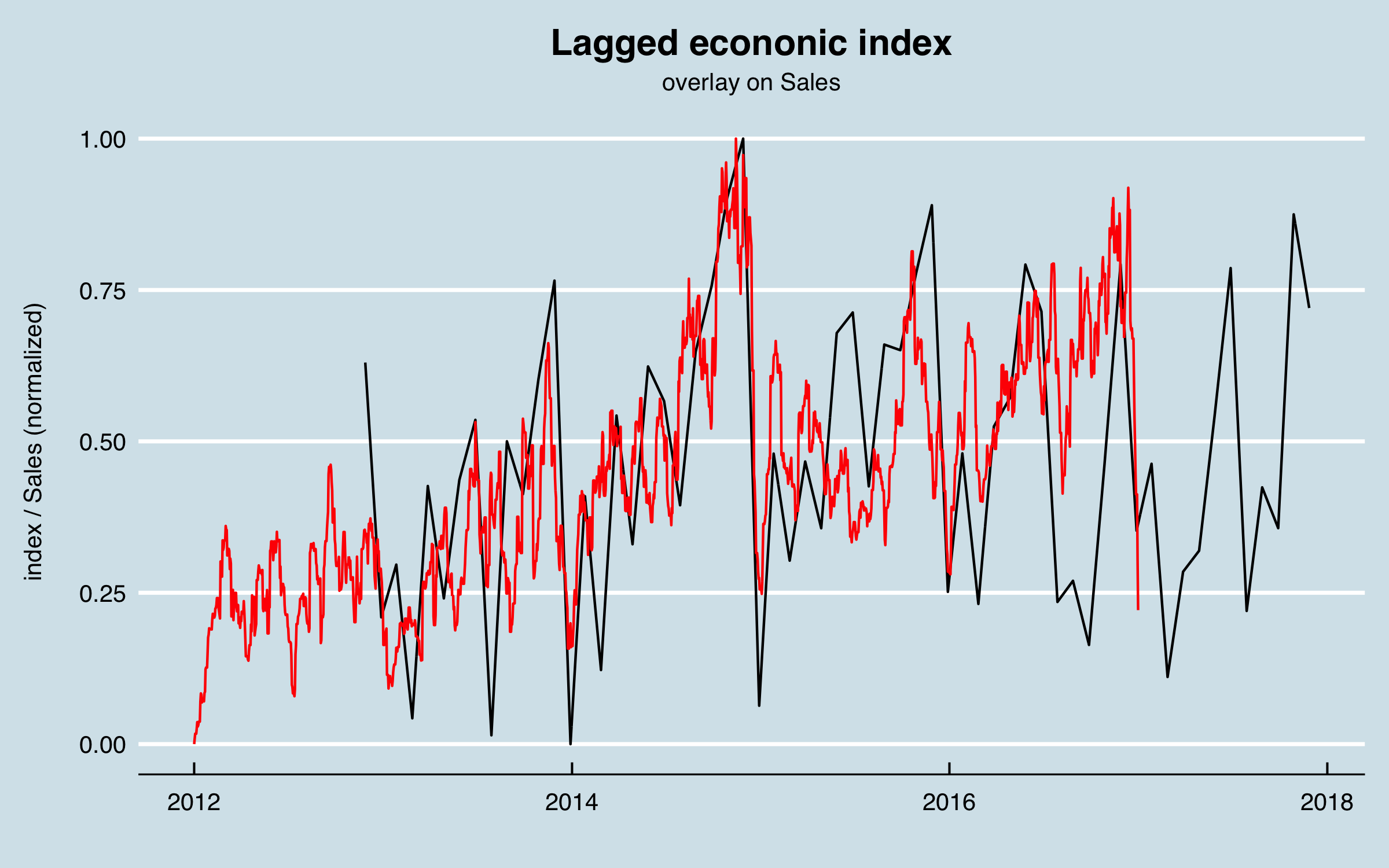
I used a correlation analysis to find the lag between these data and the sales data, arriving at 331 days. Here are the two series together with the economic data shifted 331 days. There is correlation of some of the biggest peaks as well as a relationship between the end-of-year dips and the index. Note that the scaling between the two series isn’t relevant as that will be accounted for in the regression model.
Because most of the sales in this case go into industrial settings, another possible external predictor are measures related to adding industrial capacity. A commonly used measure is Manufacturing Equipment Orders. There are historical data available for the US from the US Census Bureau. Here are the data plotted with the sales data, where the sales data have been aggregated to monthly to match the equipment order data, and the trend has been removed for clarity.
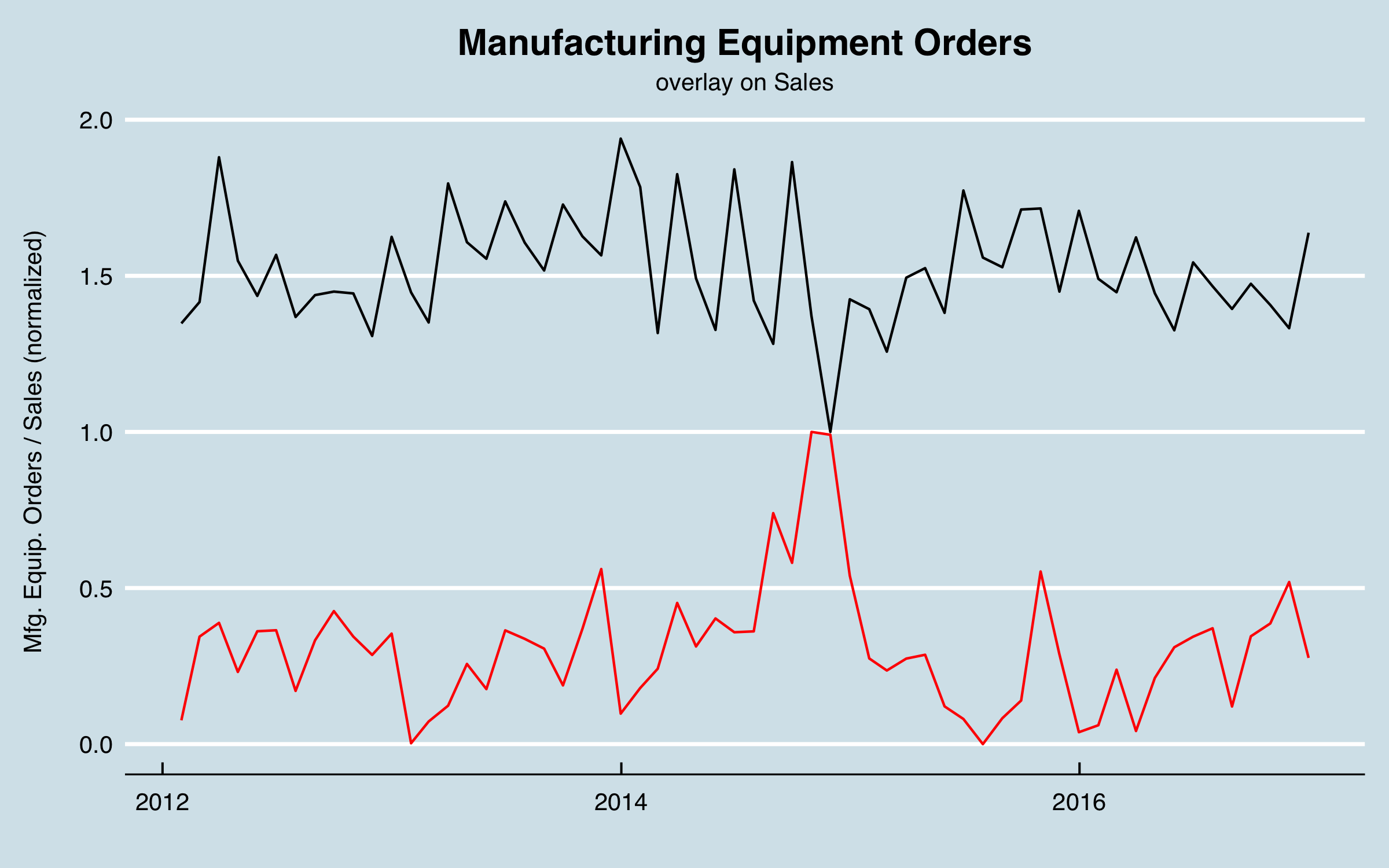
I ran a cross correlation analysis between the monthly series, as seen below. The strongest correlation occurs at 13 months, or 393 days.
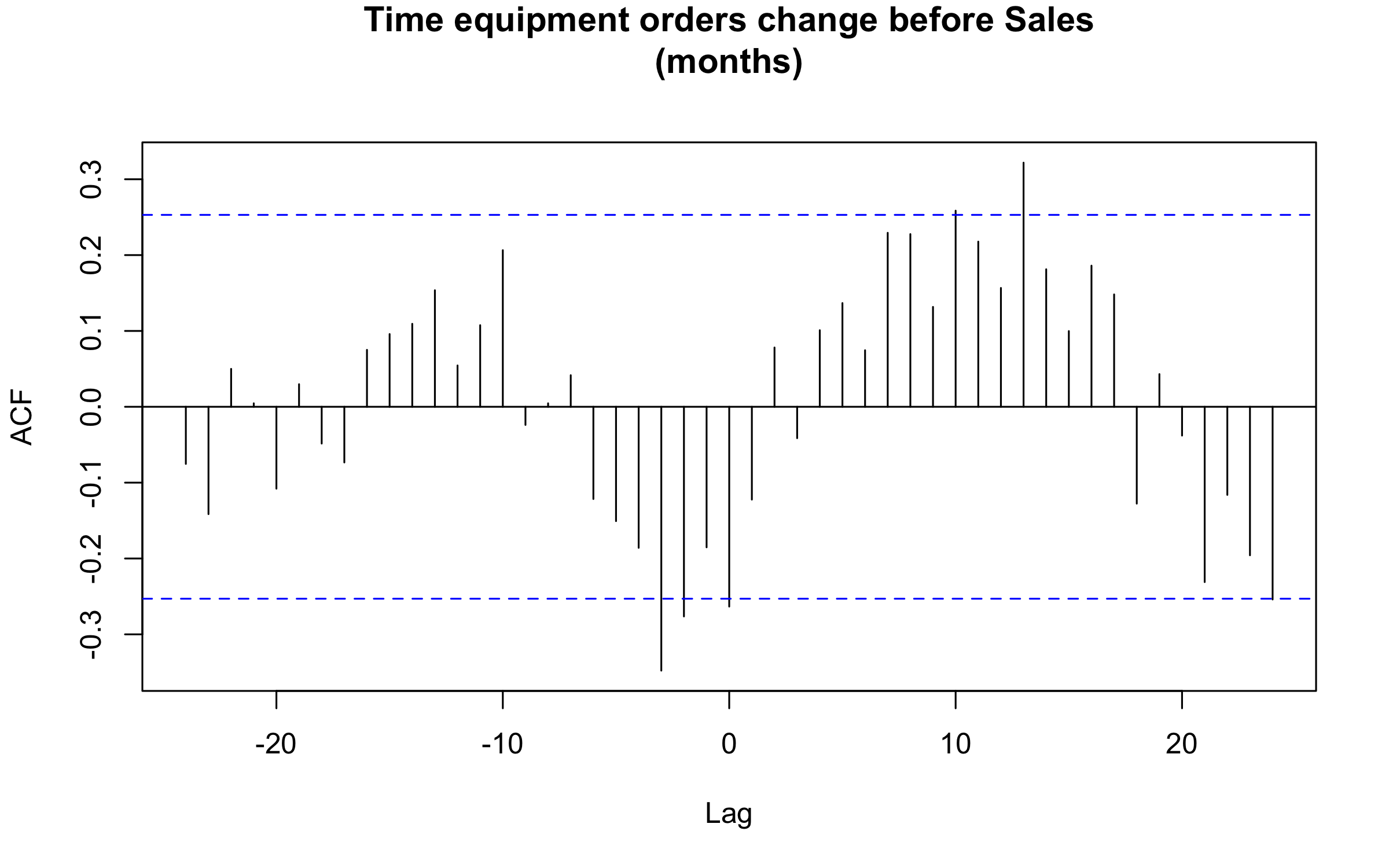
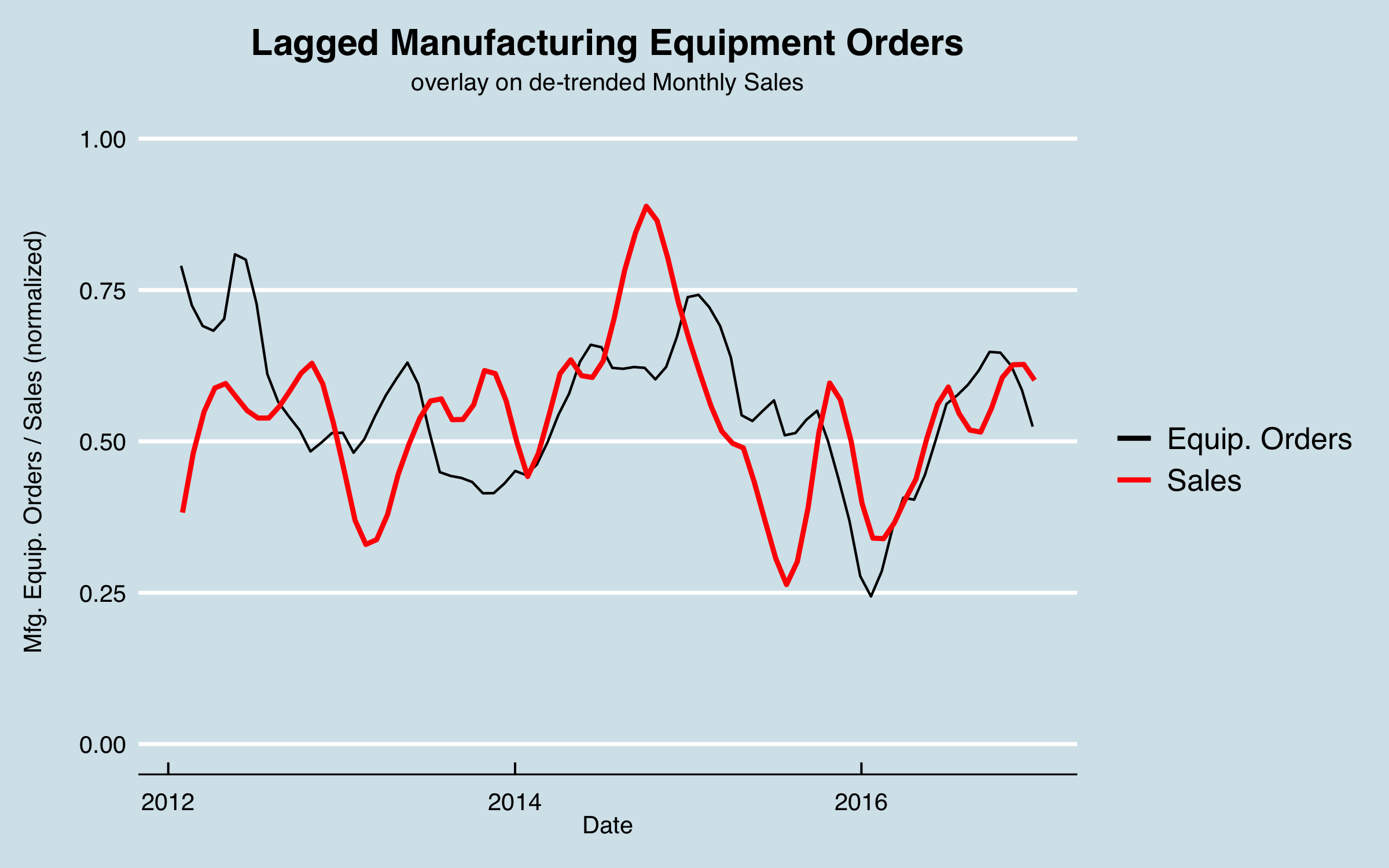
In this chart I shift the equipment orders by the lag found, and adjust for the difference in the means to aid in visualizing, as well as smoothing. As with the other factors, it’s not perfect correlation and not the whole story, but I can use this in the model to try to improve the overall predictive power.
4.4 Combining Data and Final Visualizations
The external data will be merged with the existing data using the appropriate lag times. In the cases where the external data are monthly or weekly, I use linear interpolation to create daily values to be able to combine the data. Note that there are possibly better interpolation approaches and that could be an area of improvement in the future.
As mentioned earlier, the sales areas were encoded as dummy variables and the sales by product group were broken out into columns for each group. I now look at those data as the last part of data understanding. Here are the columns so far:
## [1] "date" "year_day" "month_day"
## [4] "weekend" "holiday" "Key_Markets"
## [7] "North" "NorthEast" "South"
## [10] "Mountain" "Key_Accounts" "Other"
## [13] "SouthEast" "SouthWest" "Bookings_GP"
## [16] "Bookings_HP" "Bookings_NB" "Bookings_LR"
## [19] "Bookings_Other" "Bookings_Spec_1" "Bookings_Spec_2"
## [22] "Bookings_Spec_3" "Bookings_Repl" "Bookings_Kit"
## [25] "Pipeline_GP" "Pipeline_HP" "Pipeline_NB"
## [28] "Pipeline_LR" "Pipeline_Other" "Pipeline_Spec_1"
## [31] "Pipeline_Spec_2" "Pipeline_Spec_3" "Pipeline_Repl"
## [34] "Pipeline_Kit" "sin_512" "cos_512"
## [37] "sin_365" "cos_365" "sin_183"
## [40] "cos_183" "sin_91" "cos_91"
## [43] "sin_30" "cos_30" "tot_bookings_raw"
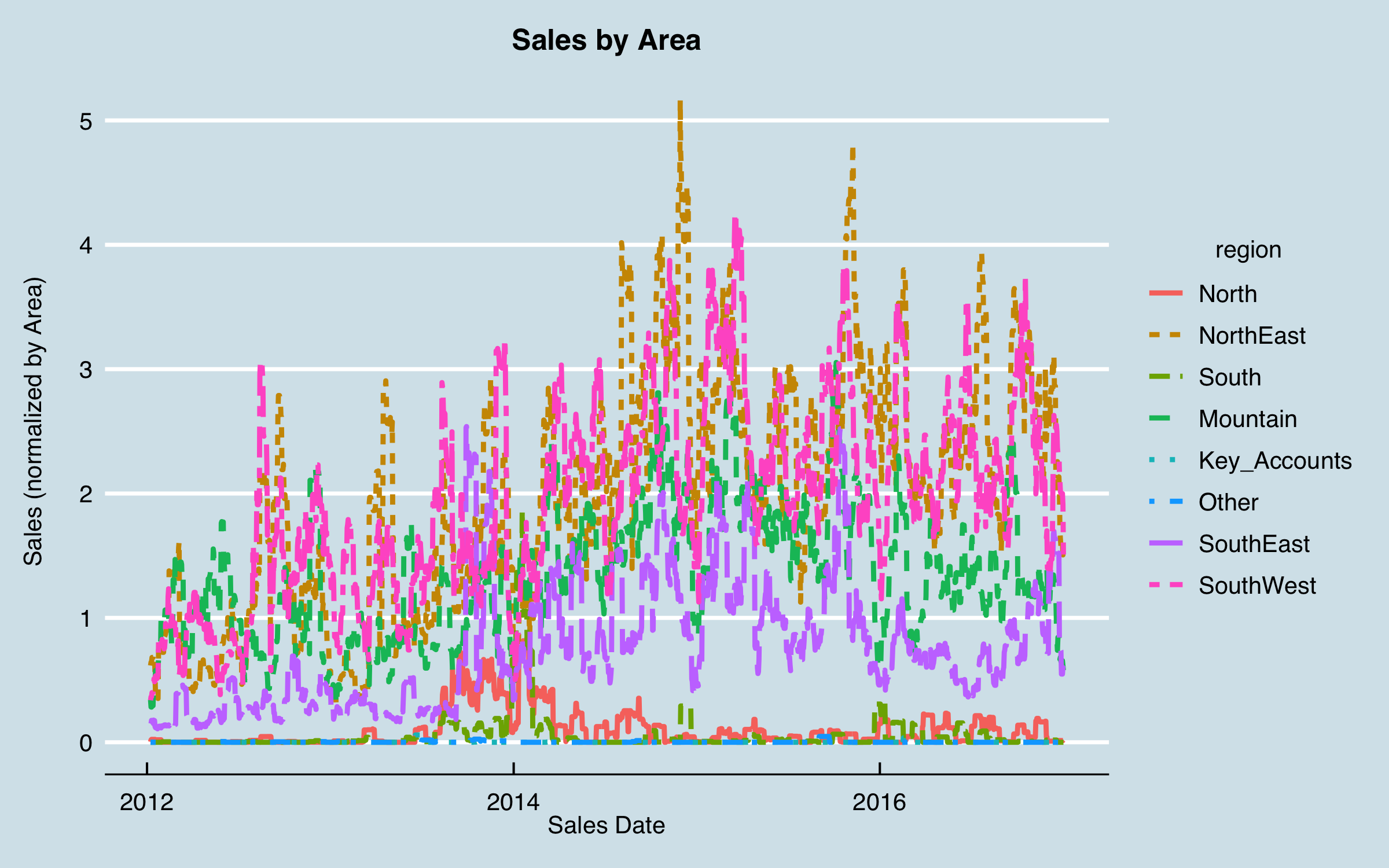
Clearly there are some issues when the sales data are grouped this way. In particular, there are several series that seem to have little or no recent data; those will present a problem in the model. I generated a summary by area to investigate those that have very unusual time history:
## # A tibble: 8 x 2
## area bookings
## <fct> <dbl>
## 1 North 184
## 2 NorthEast 3606
## 3 South 102
## 4 Mountain 2471
## 5 Key_Accounts 2
## 6 Other 4
## 7 SouthEast 1387
## 8 SouthWest 3549
It can be seen that for the purposes of this analysis, Key Accounts and Other are essentially irrelevant, so I won’t include them. Also, North and South seem to have low sales and almost nothing recently, so I exclude them as well, at least initially. (I am trying to predict the future, and here I have data to the end of 2016, so the small amount of business in those two areas in 2013-2014 won’t help predict into 2017 or beyond.) Note that I would also want to do more business understanding (more questions to the stakeholders) before finalizing the analysis, but for the purposes here I will press on to some modeling.
Regenerating the plot without these four areas gives:
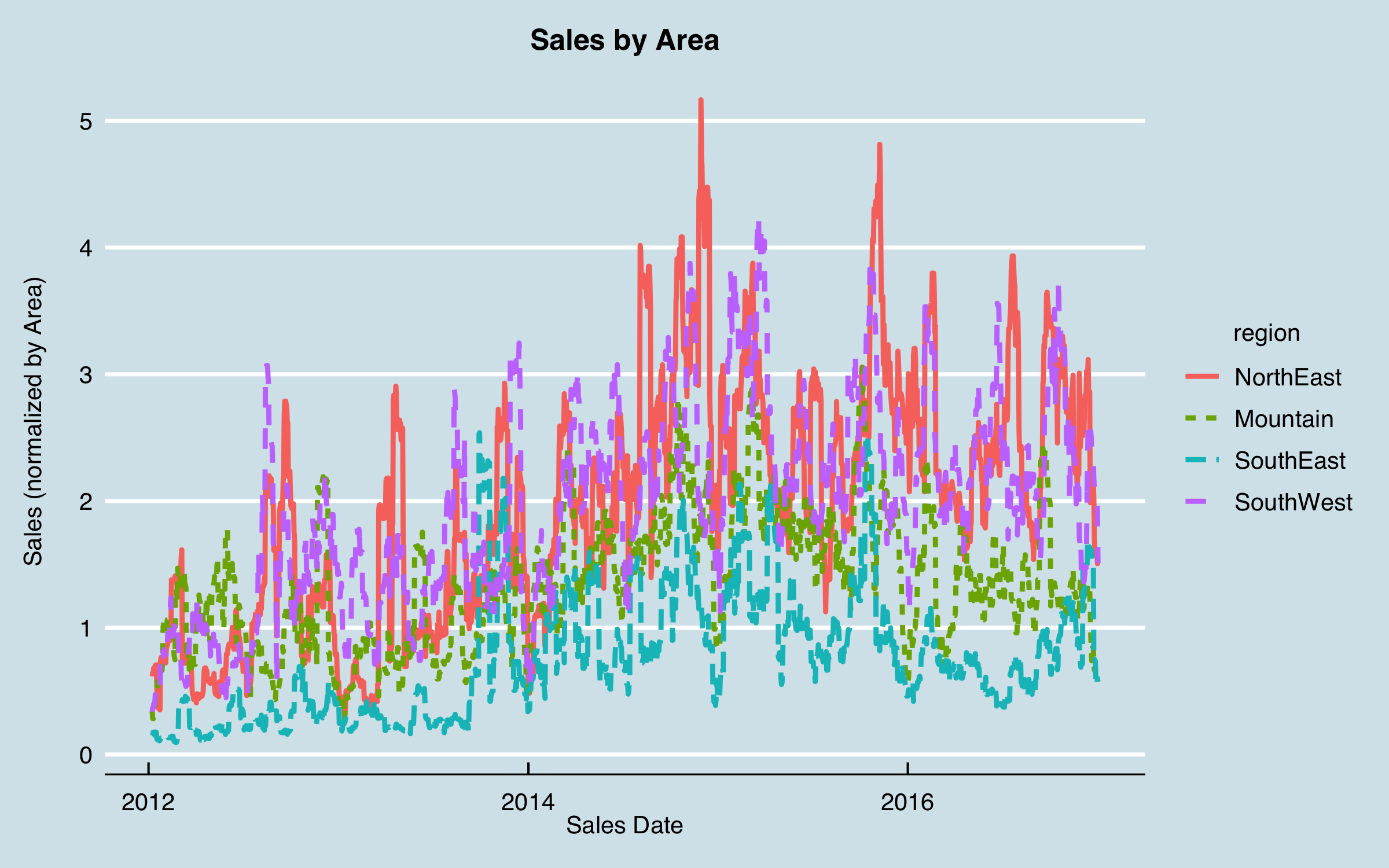
I can now see some indication of recurring patterns; plotting the aggregated data (total bookings) side by side shows some relationships:
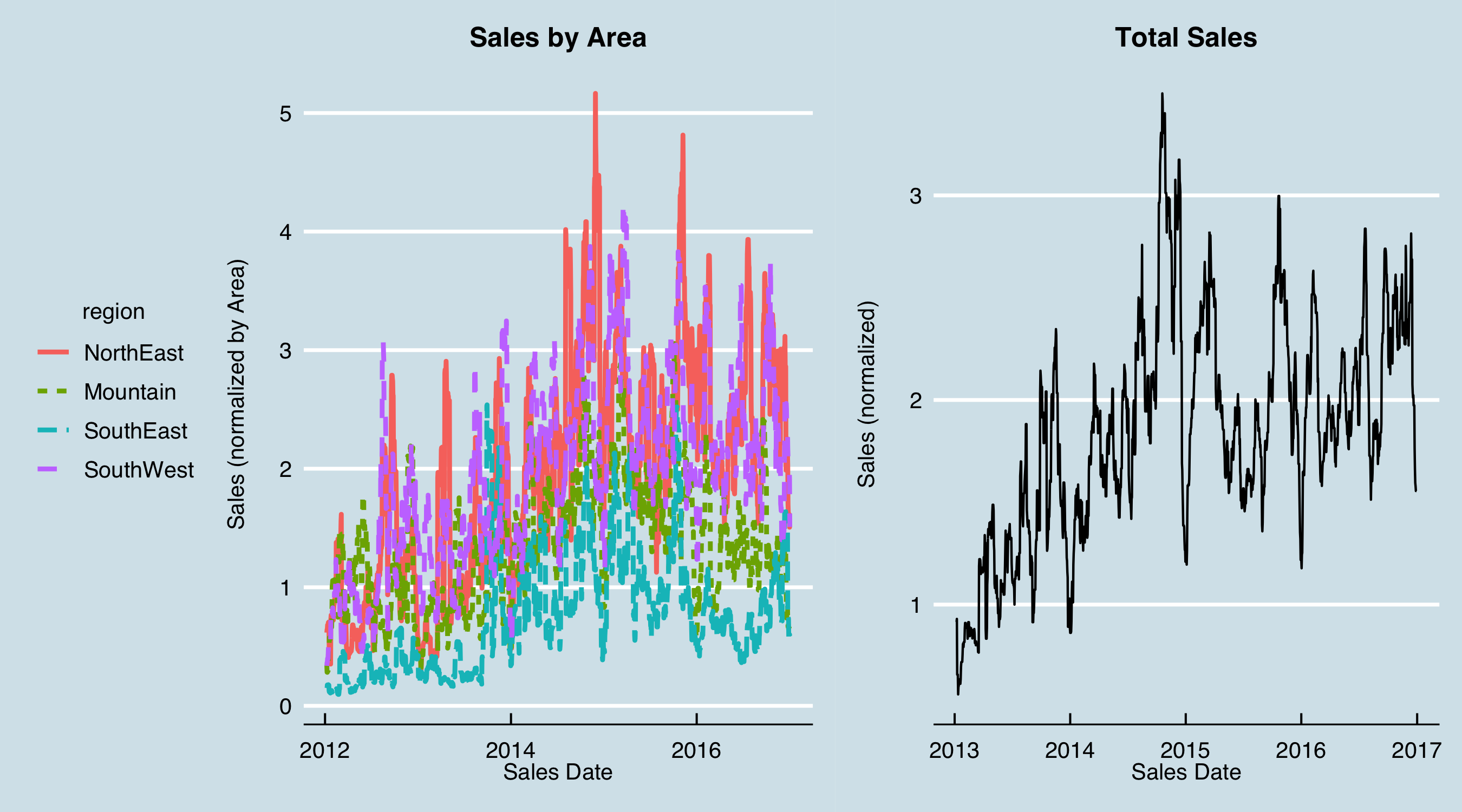
Note that in the right-hand chart, the dates are one year later than in the left hand; this is because earlier I lagged the historical sales data one year as part of initial analysis and understanding.
5. Modeling
I am now ready to begin modeling. The approach I like to take is to build a simple model as a baseline right away, then use that to compare more complicated methods. If I can’t achieve significant improvement over the baseline, it isn’t fruitful to use more complex models. Here, I will build a simple multiple-linear regression model using lm() in base R, then use caret to perform an optimization of a generalized linear model (ridge/lasso regression via package glmnet) to see if that improves the model. From that result I’ll move to a neural network with keras; first a linear network to illustrate reproducing the linear model, then a multilayer non-linear network to try to improve on that.
5.1 Linear Regression
Here is the baseline linear model, with factors removed that have large p values (> 0.5).
##
## Call:
## lm(formula = signif_form, data = baseline_train_data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.34413 -0.00977 -0.00450 0.00197 0.98341
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.944e-01 1.165e-02 -16.684 < 2e-16 ***
## year_day 2.128e-03 9.096e-04 2.339 0.019312 *
## month_day -6.434e-04 5.774e-04 -1.114 0.265155
## Key_Markets 3.469e-03 3.587e-04 9.670 < 2e-16 ***
## NorthEast 3.121e-02 3.961e-04 78.791 < 2e-16 ***
## Mountain 9.324e-03 4.027e-04 23.156 < 2e-16 ***
## SouthEast 9.897e-03 3.661e-04 27.038 < 2e-16 ***
## SouthWest 1.818e-02 4.093e-04 44.429 < 2e-16 ***
## Bookings_GP -4.348e-02 1.970e-03 -22.070 < 2e-16 ***
## Bookings_HP 1.226e-01 1.949e-03 62.889 < 2e-16 ***
## Bookings_NB -2.110e-02 3.139e-03 -6.724 1.78e-11 ***
## Bookings_LR 4.226e-01 2.071e-03 204.027 < 2e-16 ***
## Bookings_Other 1.119e-02 2.078e-03 5.385 7.26e-08 ***
## Bookings_Spec_1 1.081e-01 2.784e-03 38.820 < 2e-16 ***
## Bookings_Spec_2 -2.792e-02 2.564e-03 -10.888 < 2e-16 ***
## Bookings_Spec_3 1.157e-01 2.675e-03 43.258 < 2e-16 ***
## Bookings_Repl -4.788e-02 4.615e-03 -10.375 < 2e-16 ***
## Bookings_Kit -4.757e-02 3.504e-03 -13.576 < 2e-16 ***
## Pipeline_HP 3.594e-02 1.502e-03 23.923 < 2e-16 ***
## Pipeline_NB 1.006e-02 1.964e-03 5.123 3.02e-07 ***
## Pipeline_LR 1.657e-01 1.915e-03 86.524 < 2e-16 ***
## Pipeline_Other -4.909e-03 1.828e-03 -2.686 0.007239 **
## Pipeline_Spec_1 1.631e-02 1.495e-03 10.912 < 2e-16 ***
## Pipeline_Kit -1.030e-02 1.535e-03 -6.706 2.01e-11 ***
## sin_512 2.864e-04 3.071e-04 0.933 0.351032
## cos_512 -1.074e-03 3.134e-04 -3.426 0.000612 ***
## sin_365 5.869e-03 7.794e-04 7.530 5.13e-14 ***
## cos_365 2.413e-03 3.368e-04 7.165 7.82e-13 ***
## sin_183 3.279e-03 5.515e-04 5.946 2.75e-09 ***
## cos_183 -2.665e-03 3.135e-04 -8.500 < 2e-16 ***
## sin_91 2.728e-03 3.746e-04 7.282 3.32e-13 ***
## cos_91 -1.012e-03 3.920e-04 -2.581 0.009843 **
## sin_30 8.169e-04 4.194e-04 1.948 0.051443 .
## cos_30 -8.037e-04 3.764e-04 -2.136 0.032716 *
## Date 1.090e-05 7.319e-07 14.891 < 2e-16 ***
## commodity_price 1.216e-02 8.723e-04 13.946 < 2e-16 ***
## Orders 8.396e-03 9.659e-04 8.692 < 2e-16 ***
## index 1.333e-02 1.046e-03 12.740 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.03585 on 112372 degrees of freedom
## Multiple R-squared: 0.5151, Adjusted R-squared: 0.515
## F-statistic: 3226 on 37 and 112372 DF, p-value: < 2.2e-16
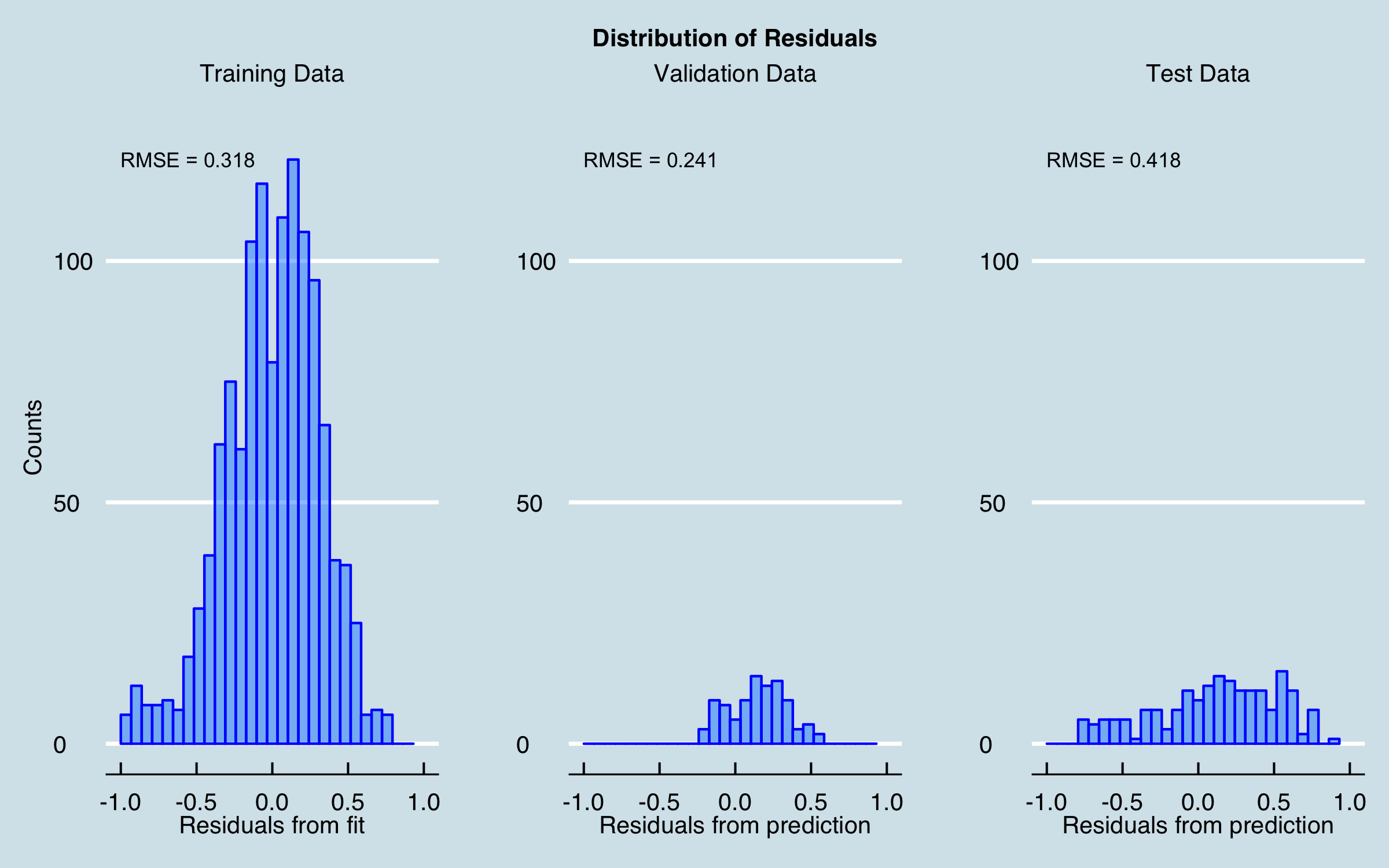
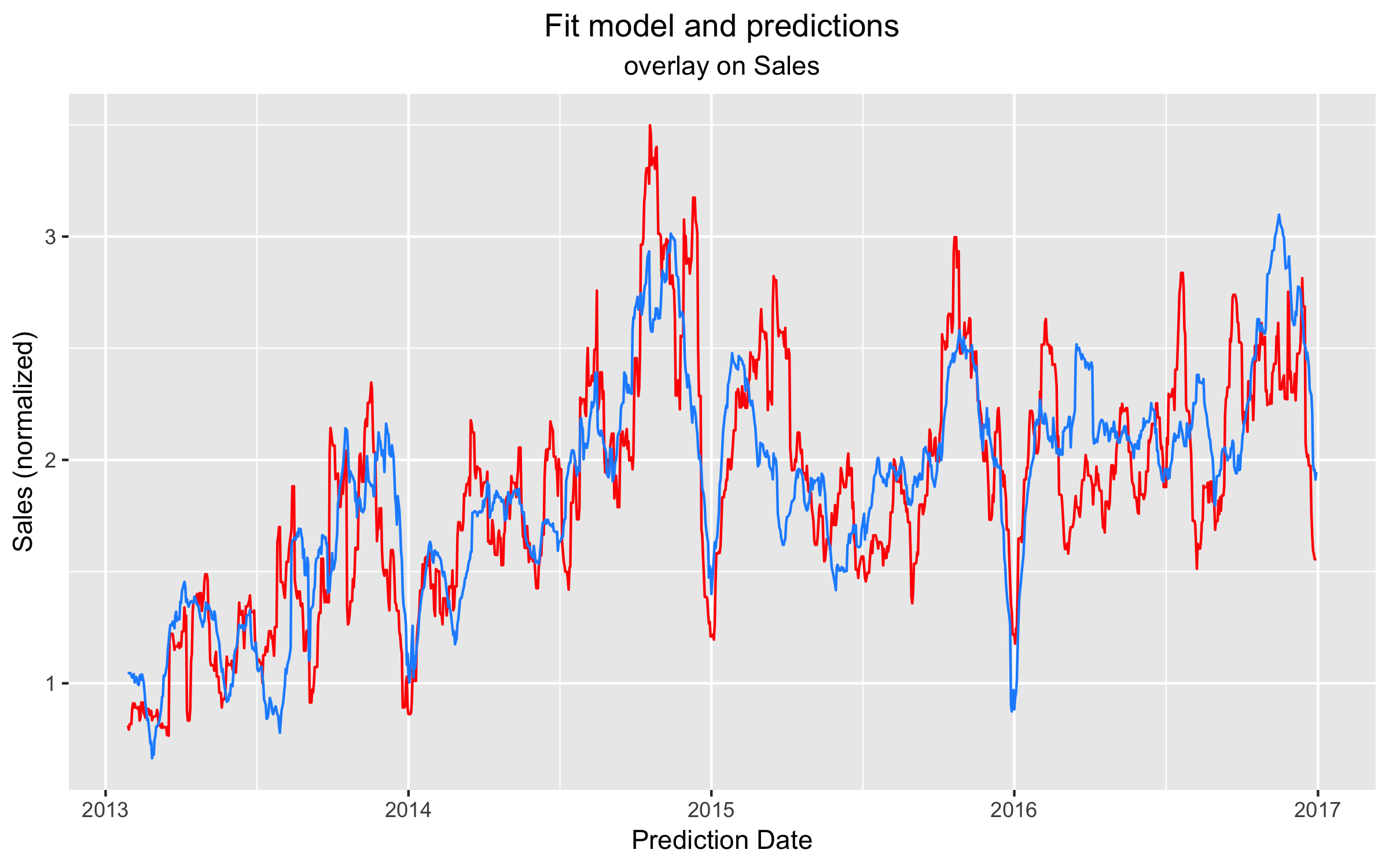
At this stage, the residuals from the fit are reasonably distributed, albeit with fairly large RMSE (and the R-squared isn’t great either!), and the residuals for the prediction intervals aren’t terrible. Plotting the prediction and actual sales together gives:
5.2 GLMNET
Now I will try to improve the model using the caret package to perform an optimization, applying 5-fold cross validation with 2 random repeats and a grid-search of the alpha and lambda values used with the glmnet method. The residuals from the optimized fit and predictions are nearly identical to the baseline results, as shown here.
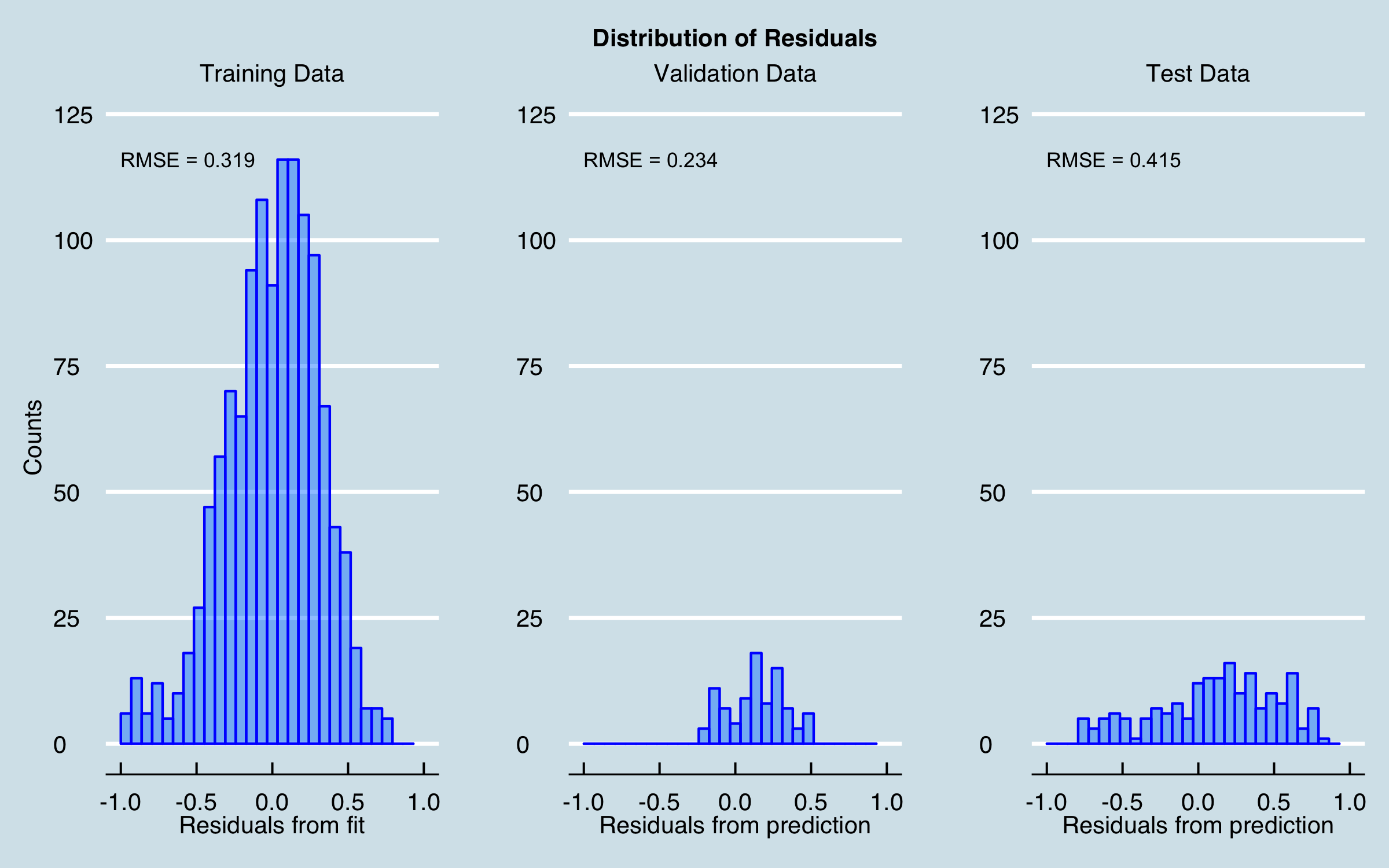
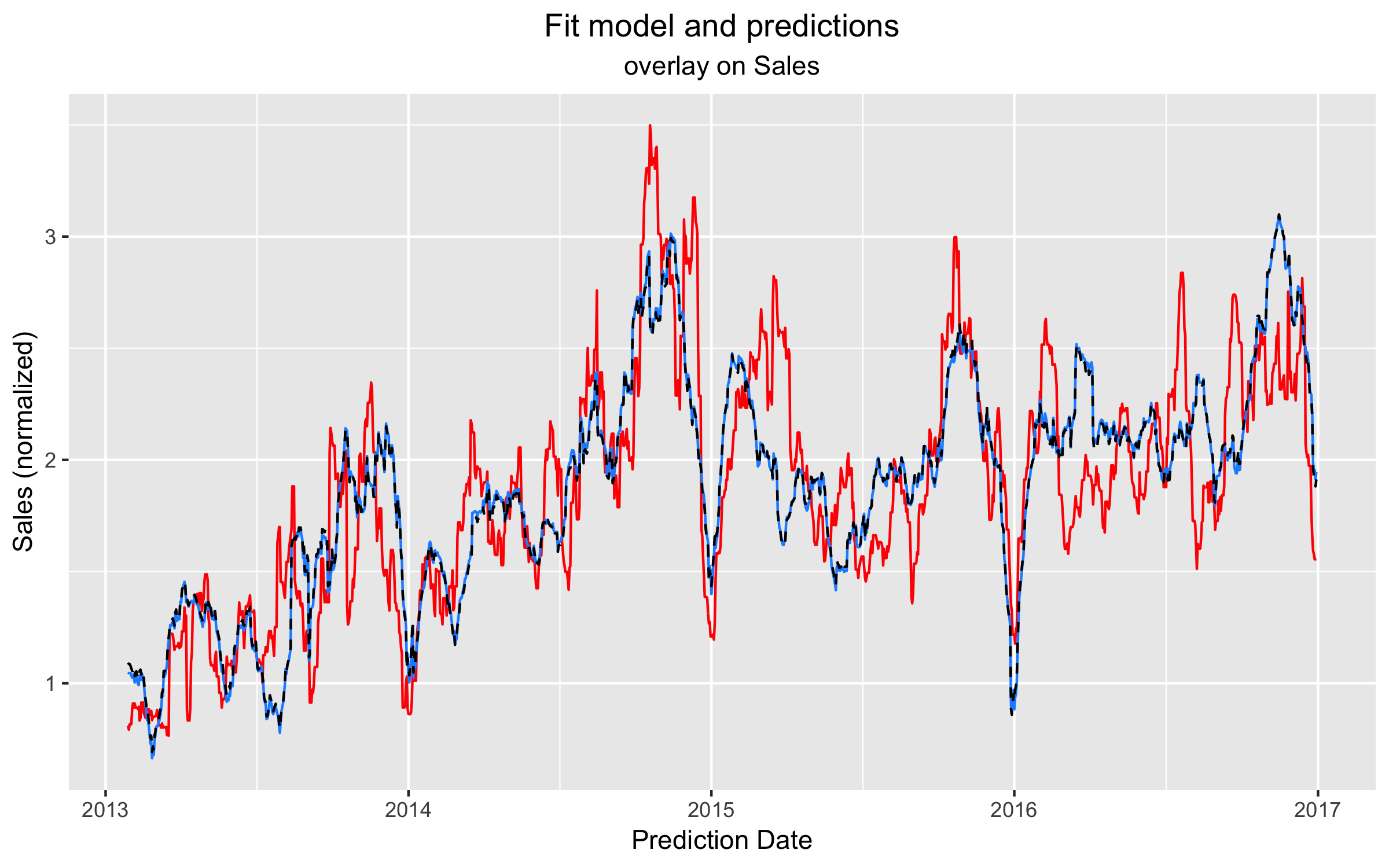
Here is the optimized model and predictions plotted (dashed black line) with the baseline model (blue) and actual sales (red). Unfortunately, no significant improvement is found.
5.3 Neural Network
Before using a full neural network, I want to illustrate that I can define a network with no hidden layers, and use all linear activation functions, and reproduce the linear regression results (although much less efficiently!). Using linear activations can be useful to debug networks during development as well. For this linear baseline and the fully connected multilayer network, I used Keras in R to build and train the models. The linear model looks like this:
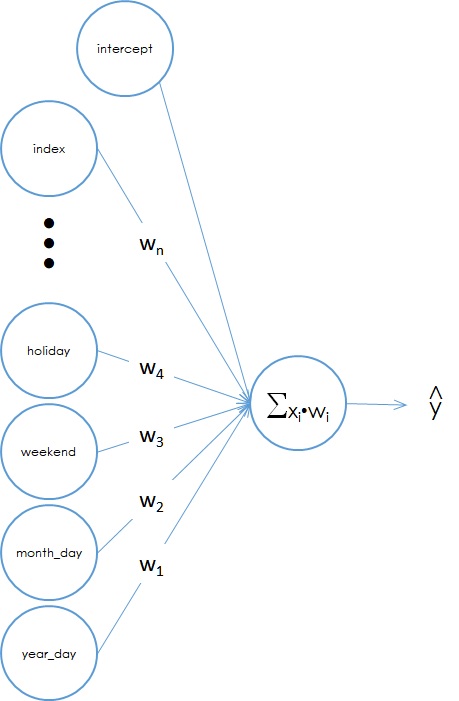
Figure 2. A linear "neural" network model.
On the left are the input data. Each variable has a weight which is equivalent to the regression coefficients found using linear regression. The input values are multiplied by the weights then a linear sum is done at the output. The y-intercept, or constant term, is the same as a “bias” node in a neural network.
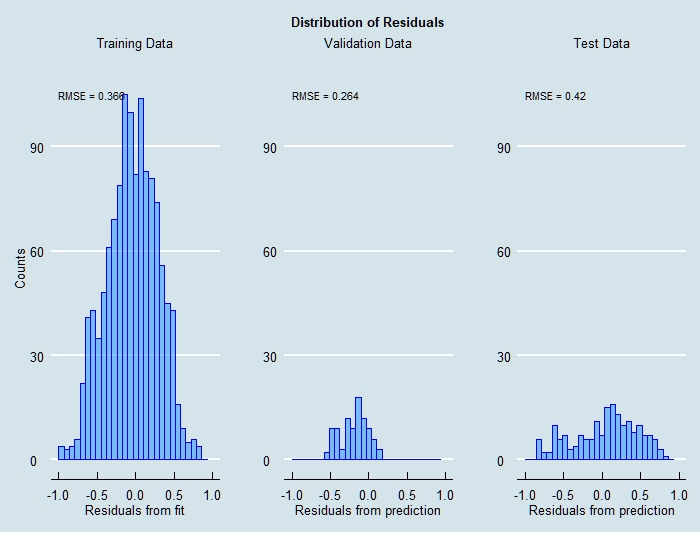
Training this model results in the residuals shown below. The residuals that result from this model are similar to those from the linear regression baseline. Given optimization of the learning rate, rate decay, and selection of the best optimizer, I could get arbitrarily close to the linear regression result.
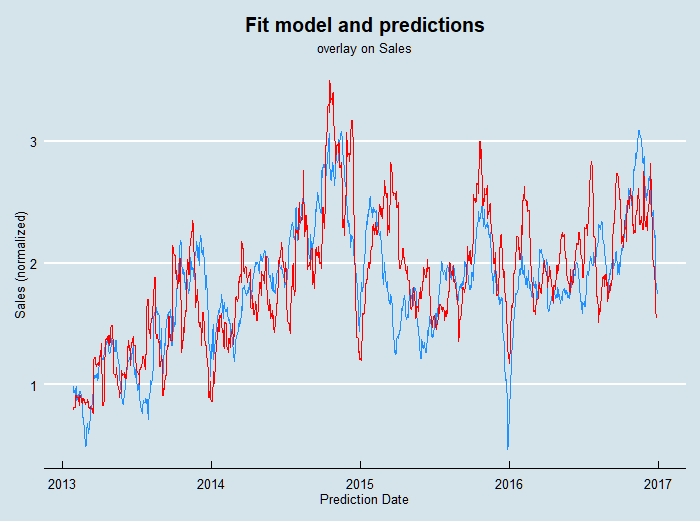
Here is a similar plot to before where the predictions across the entire data range are overlaid on the sales data.
Now I will optimize a multilayer neural network and improve on the results so far. The network architecture was chosen from experience and was not further optimized; the optimization was used to tune the learning rate and decay, choose the activation functions, and choose the best optimizer. The optimizer is the algorithm that tries to minimize the cost function by navigating the high-dimensional surface that the cost function represents. There are many optimizers available in Keras; in this case I settled on rmsprop, which has been shown in the literature to have good convergence properties.
For the activation functions, I initially tried RELU (rectified linear unit) as it is something of a “go to” in deep learning. However, this particular problem tended to suffer the problem of vanishing gradients. Gradient refers to the partial derivative of the cost function with respect to the model parameters; this slope or gradient is used to estimate updates to the parameters during training. Under certain conditions, the gradients at some nodes can become zero, which then stops any further updates of the parameters at that node; in other words the node can’t learn!
The solution was to use a variant of RELU called ELU (elastic linear unit) which ensures the gradient cannot go to zero. Using ELU in this model resulted in predictable training performance; the remaining task was to find the best learning rate and rate decay, the batch size, and the number of epochs to achieve good results. The model was fairly sensitive to learning rate and decay during training. However, it was found to have the property that it wasn’t very sensitive to batch size.
In deep learning, a lot has been written about batch size and suggesting to use smaller mini-batches to get good training. The batch size is the number of training examples passed through the network before a parameter update is calculated. An epoch is one pass through all the training examples. The smaller the batch size is, the longer an epoch takes to complete. I found that I could use large batch sizes (32768) which allowed running many more epochs in the same time. While some deep learning problems are prone to over-training–where the model memorizes the training data but actually gets worse on validation data the more training iterations are used–in this case that also was found not to be the case. Thus, I tried different lengths of training and observed the improvement in the validation error.
The Keras code for the model is as follows. There three hidden layers defined to be twice as wide as the data, plus an input layer and the linear output layer. The linear output is important as it allows us to scale results back to real values if needed.
width_factor <- 2
nn_model <-
keras_model_sequential() %>%
layer_dense(units = ncol(x_train),
activation = "elu",
input_shape = c(ncol(x_train)),
kernel_initializer =
initializer_random_normal()) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = width_factor * ncol(x_train),
activation = "elu",
kernel_initializer =
initializer_random_normal()) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = width_factor * ncol(x_train),
activation = "elu",
kernel_initializer =
initializer_random_normal()) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = width_factor * ncol(x_train),
activation = "elu",
kernel_initializer =
initializer_random_normal()) %>%
layer_dense(units = 1, activation = "linear")
The model looks like this:
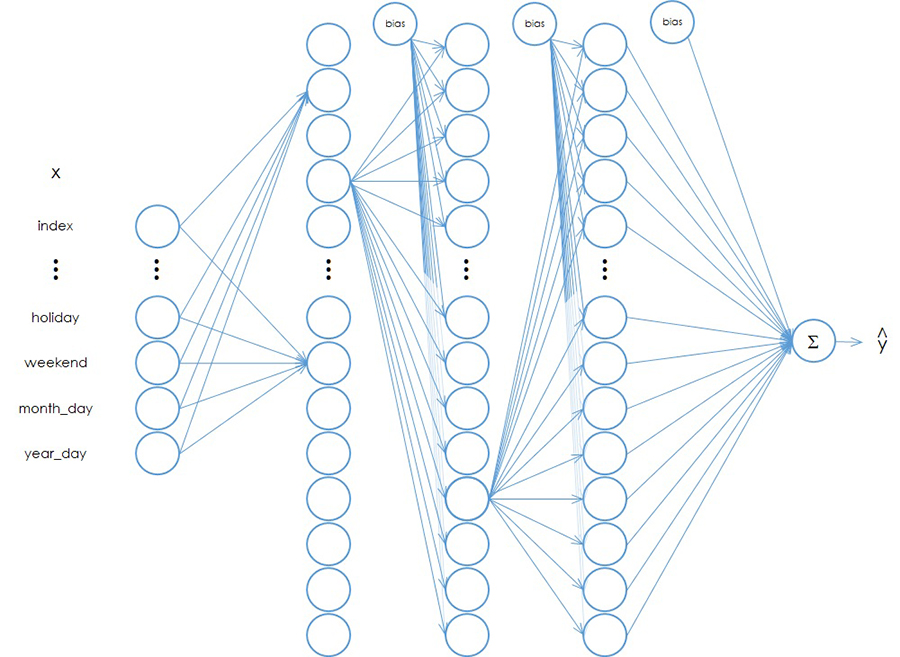
Figure 3. A multi-layer neural network model.
For clarity, all network connections are not shown, but every node in a given layer is connected to every node in the following layer. The output of a node is multiplied by a weight, for which there is a unique value for every arrow shown (and those not shown); those values are summed at each node, then the activation function is applied to generate the output heading to the next layer. In the final linear node the values are simply summed as before.
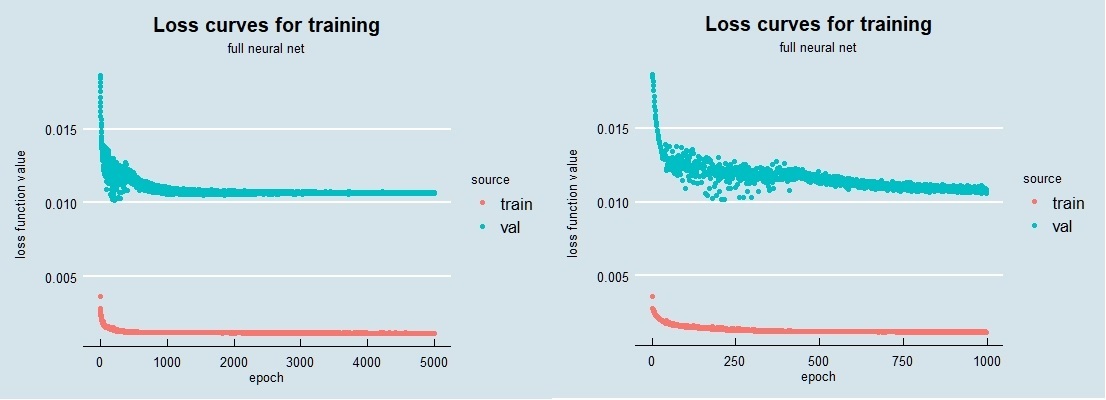
When I trained this network with the optimal parameters, the resulting loss curves look as follows. On the left are the full 5000 epochs used; on the right I zoom in on the first 1000. The change that occurs just before 500 epochs, where the validation loss is noisy before then becomes quieter and begins decreasing again, is likely due to the decay parameter. In the epochs around 250 the learning rate is probably a bit too high, which generates the noise. As the decay (reduction) of the learning rate continues, the training enters a regime where again the loss decreases smoothly. In my work I have seen this sort of training behavior a number of times; when you have time and resources it’s good to train a network longer than might initially be concluded, just to ensure you aren’t in a situation like this. It’s also very possible that I could have tweaked the learning rate and decay a bit to eliminate this.
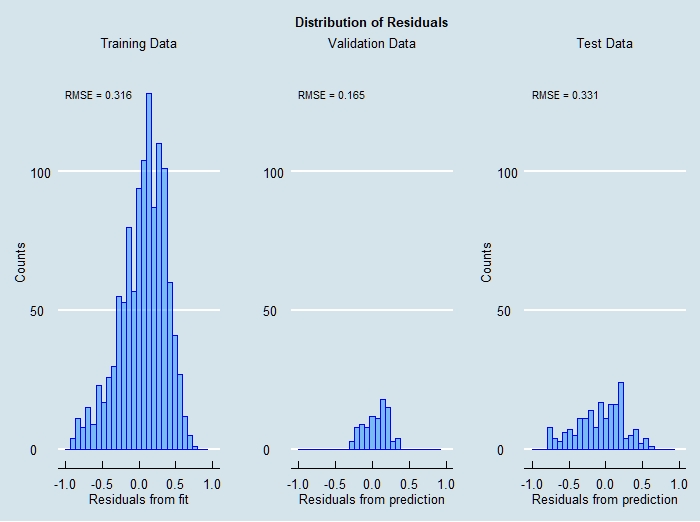
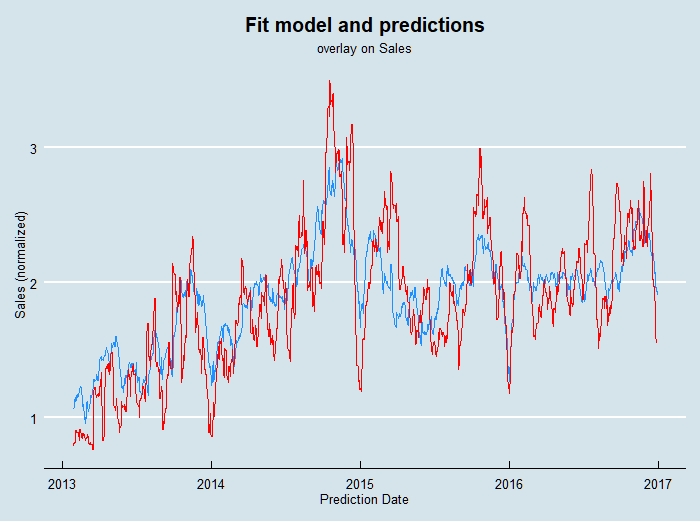
The final results of training this network then making predictions on the validation and test data are shown here:
5.4 Summary of Results
A summary of the results is given in Table 3, in terms of accuracy over the stated prediction intervals. A useful concept in looking at all of this work is “precisely wrong, directionally correct”. By that I mean that it is clear that on short time scales the models are not yet predicting all the behavior seen in the target data, although most of the large changes are modeled fairly well. This looks ugly compared to textbook cases but we live in a world of complex data. However, keep in mind a business operates on time scales appropriate to the business–in this case, due to material and manufacturing lead times, orders for material are placed significantly in advance, so the most important result is to predict well, on average, over periods of interest. The table shows that even the simple linear model does better than 10% in the periods targeted, and the neural network improves on that by multiple percentage points.
| Model |
Train Error |
Val Error |
Test Error |
| Linear Regression |
-0.7% |
7.5% |
5.1% |
| Optimal GLM |
-0.6% |
7.1% |
5.2% |
| Linear Network |
3.2% |
-9.4% |
5.2% |
| Neural Network |
3.0% |
2.4% |
-3.3% |
| Average LR/LN/NN |
1.8% |
0.2% |
2.3% |
Table 3. Summary of Results
Regarding the last entry in Table 3; this is a simple ensemble of the three different models (excluding the optimized regression which is essentially the same as the baseline model). I chart this along with sales below; as an initial approach, I would probably use this ensemble to make predictions.
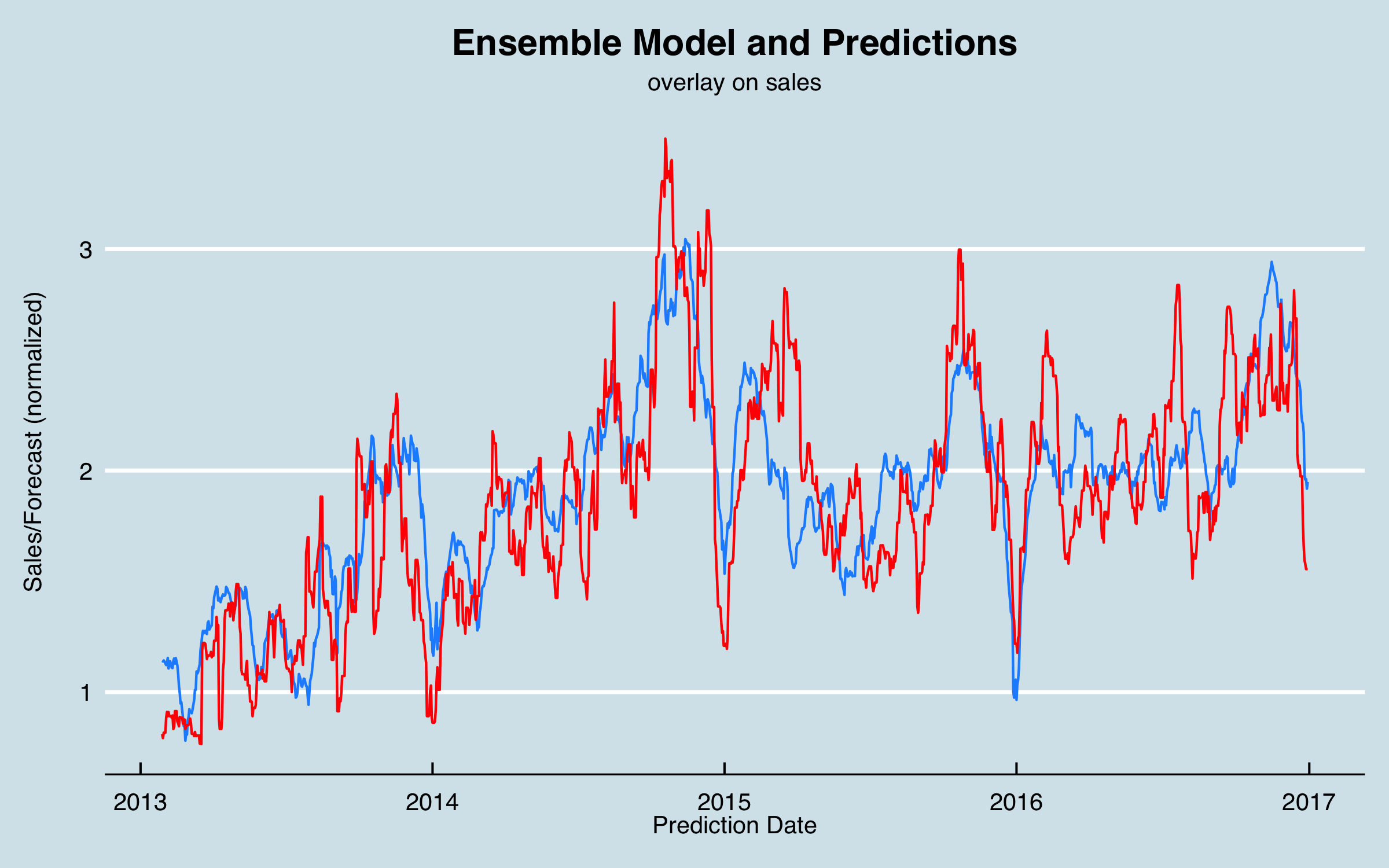
6. Conclusions and Further Work
In this article I have shown that regression models, including using neural networks for non-linear modeling, can be effective to model complex time-series data. Advantages of this approach include the ability to integrate business and external (market etc.) factors as well as historical data as predictors, the ability to integrate such data with specific lag times determined from the data or from business knowledge, and the fact that neural networks can account for interactions that are more difficult to model in linear regression. (On this last point; you will see suggestions of polynomial regression in articles and books; I provide the same warning as I did for using DFT (sines/cosines)–such methods can be very prone to overfitting and not generalizing well). Disadvantages include the need for much more business and data understanding than, say, modeling a univariate time series with ARIMA, as well as considerably more time and resources to complete the project.
There are many possible improvements to what I have shown here that could be investigated. It is clear there are processes in play that are not yet incorporated into the model. For example, there may be additional markets that could be incorporated as external data that drive some segments. In addition, I believe some of the large swings at end of year, and the apparent mid-year cycles are due to business practices–as half-year and end-of year targets approach, sales is pushed to book orders or pull in opportunities. There may be customer incentives in play to drive some of that. These factors can be integrated if a model of the actual business practices can be defined. Similarly, it is known that new product introductions affect sales, and a task for the future is to model that and include in the predictors.
Another area of work would be to investigate and improve modeling of components of the forecast, such as modeling individual product groups or sales areas. Although the model is built with that level of granularity, you may have noticed in the baseline model that some coefficients are negative. I think that is due to interactions or other factors unaccounted for, but it means that the model may not work well if used to predict one category. This could be tackled by modeling each desired segment or category separately then combining those models; obviously that would be a considerable additional effort!
In addition to more business understanding and data understanding, there are improvements likely available by better data preparation. If the alignment of the raw data with the categorizations were better, that would likely improve the predictive power of the models. Cleaning for some data discrepancies may also result in improvements. It is common in real business cases that data cleaning and preparation are never fully completed!
Regarding deployment, I have built interactive web applications based on such models using Shiny to allow clients to interact with the models and data–I plan to write an article on that subject in the future. One version of the model was provided in an Excel workbook as that fit the business needs.
I hope these discussions and results motivate you to try some alternative methods in your next business analytics challenge!
References