Big Data: Wrangling 4.6M Rows with dtplyr (the NEW data.table backend for dplyr)
Written by Matt Dancho
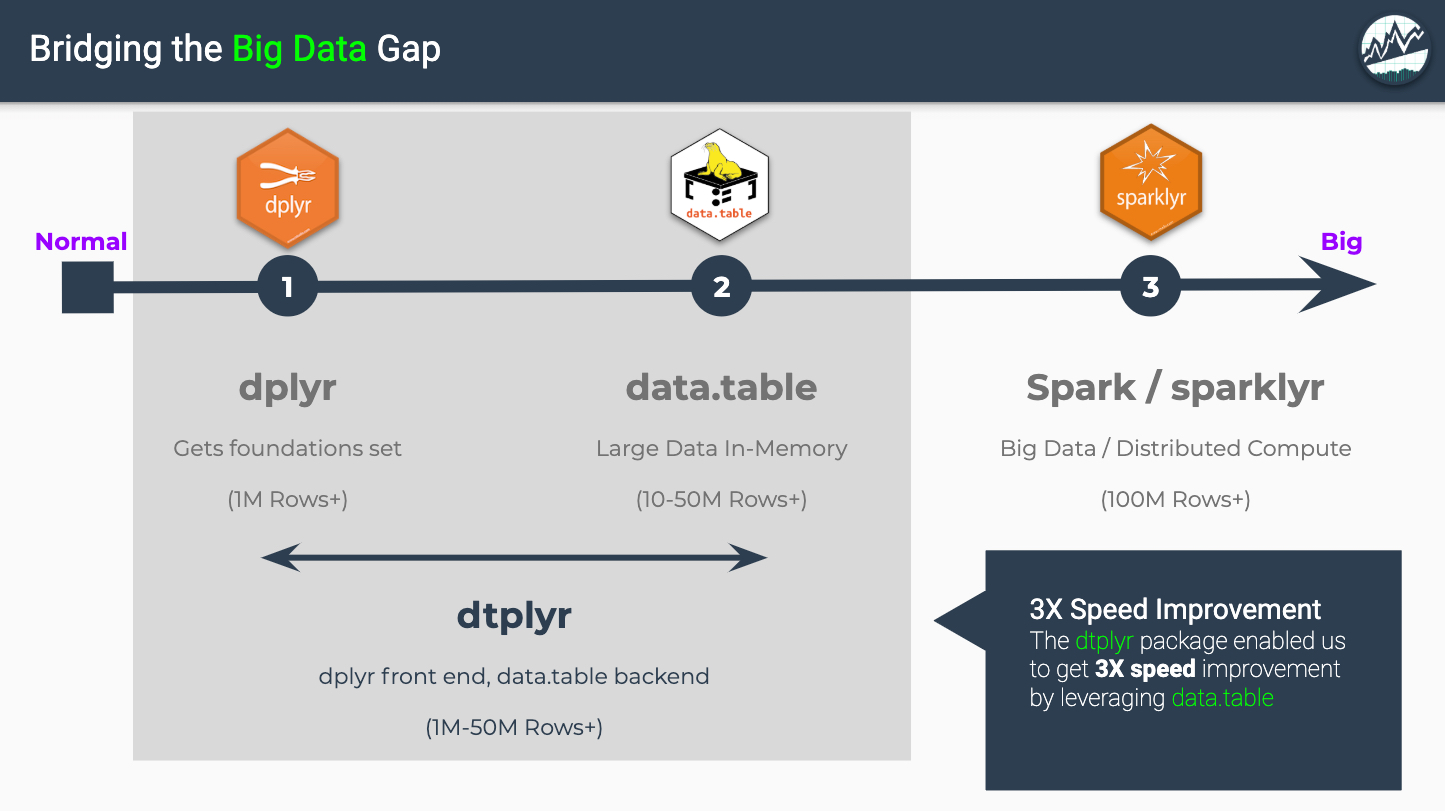
Wrangling Big Data is one of the best features of the R programming language, which boasts a Big Data Ecosystem that contains fast in-memory tools (e.g. data.table) and distributed computational tools (sparklyr). With the NEW dtplyr package, data scientists with dplyr experience gain the benefits of data.table backend. We saw a 3X speed boost for dplyr!
We’ll go over the pros and cons and what you need to know to get up and running using a real world example of Fannie Mae Loan Performance that when combined is 4.6M Rows by 55 Columns - Not super huge, but enough to show off the new and improved dtplyr interface to the data.table package. We’ll end with a Time Study showing a 3X Speed Boost and Learning Recommendations to get you expertise fast.
Like this article? Here are more just like it!
If you like this article, we have more just like it in our Machine Learning Section of the Business Science Learning Hub.
Table of Contents
-
The 30-Second Summary
-
Big Data Ecosystem
-
Enter dtplyr: Boost dplyr with data.table backend
-
Case Study - Wrangling 4.6M Rows of Financial Data
-
The 3X Speedup - Time Comparisons
-
Conclusions and Learning Recommendations
-
Additional Big Data Guidelines and Packages
-
Recognizing the Developers
1.0 The 30-Second Summary
We reviewed the latest advance in big data - The NEW dtplyr package, which is an interface to the high performance data.table library.
Pros
-
A 3X speed boost on the data joining and wrangling operations on a 4.6M ROw data set. The data wrangling operatiosn were performed in 6 seconds with dtplyr vs 18 seconds with dplyr.
-
Performs inplace operations (:=), which vastly accelerates big data computations (see grouped time series lead() operation in Section 3.7 tutorial)
-
Shows the data.table translation (this is really cool!)
Cons
-
For pure speed, you will need to learn all of data.table’s features including managing keys for fast lookups.
-
In most cases, data.table will be faster than dtplyr because of overhead in the dtplyr translation process. However, we saw the difference to be very minimal.
-
dtplyr is in experimental status currently - Tester’s wanted, file issues and requests here
What Should You Learn?
Just starting out? Our recommendation is to learn dplyr first, then learn data.table, using dtplyr to bridge the gap
-
Begin with dplyr, which has easy-to-learn syntax and works well for datasets of 1M Rows+.
-
Learn data.table as you become comfortable in R. data.table is great for pure speed on data sets 50M Rows+. It has a different “bracketed” syntax that is streamlined but more complex for beginners. However, it has features like fast keyed subsetting and optimization for rolling joins that are out of the scope of this article.
-
Use dtplyr as a translation tool to help bridge the gap between dplyr and data.table.
At a bare minimum - Learning dplyr is essential. Learn more about a system for learning dplyr in the Conclusions and Recommendations.
Before we get started, get the Cheat Sheet
The most powerful tool in my arsenal is NOT my knowledge of the key R packages, but it’s knowing where to find R packages and documentation.
The Ultimate R Cheat Sheet consolidates the documentation on every package I use frequently (including dplyr, data.table, and dtplyr).
Download the Ultimate R Cheat Sheet
If you tab through to page 3, you’ll see a section called “Speed and Scale”. You can quickly see options to help including data.table, dtplyr, furrr, sparklyr, and disk.frame. Enjoy.

Speed and Scale (page 3)
If you click the “CS” (stands for cheat sheet) next to data.table, you’ll automagically get the DataTable Cheat Sheet. (And you can do this for every R package).
Clicking 'CS' gets the data.table Transformation Cheat Sheet
2.0 Big Data Ecosystem
R has an amazing ecosystem of tools designed for wrangling Big Data. The 3 most popular tools are dplyr, data.table, and sparklyr. We’ve trained hundreds of students on big data, and our students most common Big Data question is, “Which tool to use and when?”

Big Data: Data Wrangling Tools By Dataset Size
Source: Business Science Learning Lab 13: Wrangling 4.6M Rows (375 MB) of Financial Data with data.table
The “Big Data: Data Wrangling Tools by Dataset Size” graphic comes from Business Science’s Learning Lab 13: Wrangling 4.6M Rows (375 MB) of Financial Data with data.table where we taught students how to use data.table using Fannie Mae’s Financial Data Set. The graphic provides rough guidelines on when to use which tools by dataset row size.
-
dplyr (website) - Used for in-memory calculations. Syntax design and execution emphasizes readability over performance. Very good in most situations.
-
data.table (website) - Used for higher in-memory performance. Modifies data inplace for huge speed gains. Easily wrangles data in the range of 10M-50M+ rows.
-
sparklyr (website) - Distribute work across nodes (clusters) and performs work in parallel. Best used on big data (100M+ Rows).
3.0 Enter dtplyr: Boost dplyr with data.table backend
We now have a 4th tool that boosts dplyr using data.table as its backend. The good news is that if you are already familiar with dplyr, you don’t need to learn much to get the gains of data.table!
dtplyr: Bridging the Big Data Gap
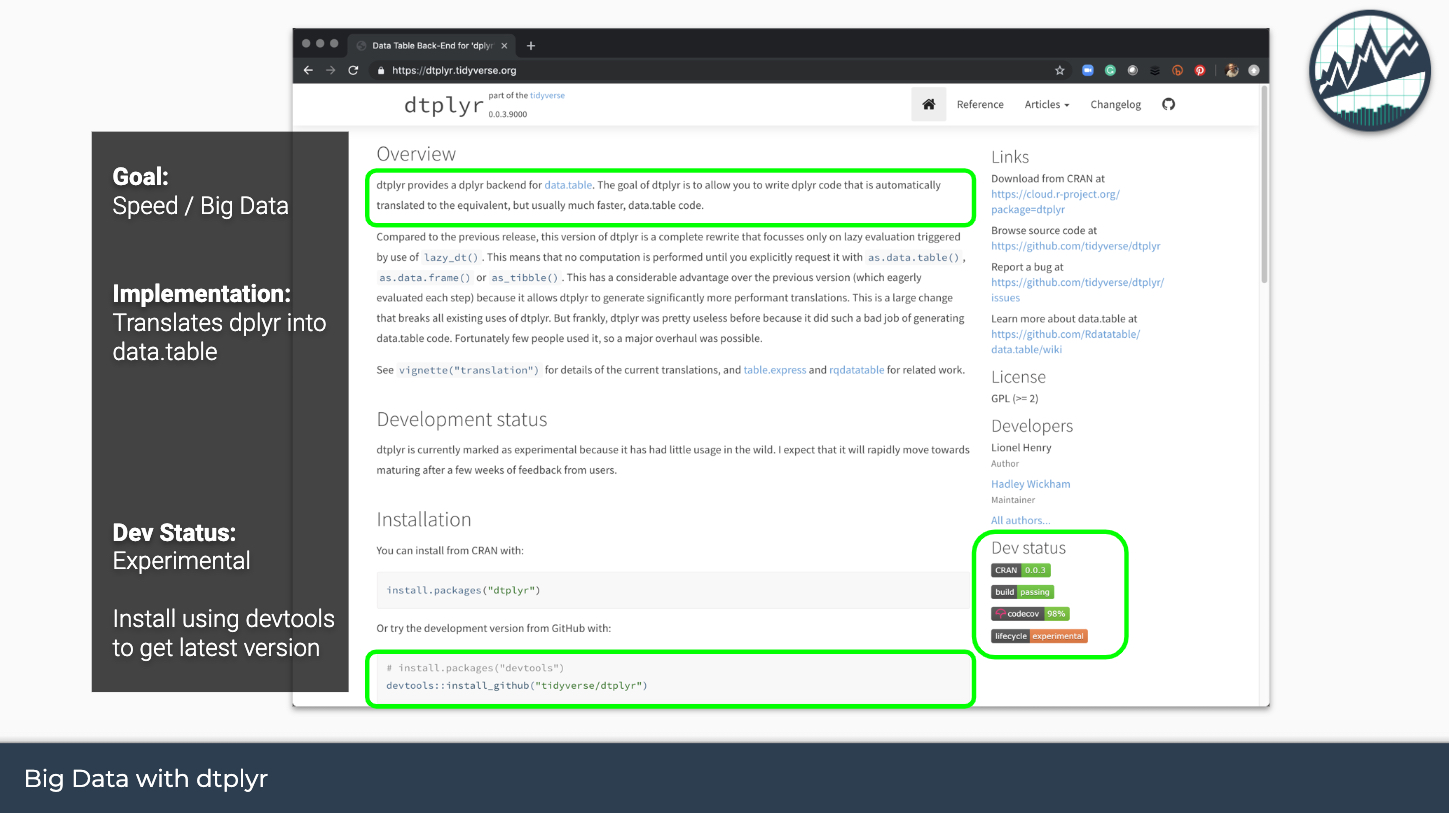
The dtplyr package is a new front-end that wraps the High Performance data.table R package. I say new, but dtplyr has actually been around for over 2 years. However, the implementation recently underwent a complete overhaul vastly improving the functionality. Let’s check out the goals the package from the dtplyr website: https://dtplyr.tidyverse.org/.
dtplyr for Big Data
Here’s what you need to know:
-
Goal: Increase speed of working with big data when using dplyr syntax
-
Implementation: The dtplyr package enables the user to write dplyr code. Internally the package translates the code to data.table syntax. When run, the user gains the faster performance of data.table while being able to write the more readable dplyr code.
-
Dev Status: The package is still experimental. This means that developers are still in the process of testing the package out, reporting bugs, and improving via feature requests.
4.0 Case Study - Wrangling 4.6M Rows (375MB) of Financial Data
Let’s try out the new and improved dtplyr + data.table combination on a large-ish data set.
4.1 Bad Loans Cost Millions (and Data Sets are MASSIVE)

Loan defaults cost organization millions. Further, the datasets are massive. This is a task where data.table and dtplyr will be needed as part of the preprocessing steps prior to building a Machine Learning Model.
4.2 Fannie Mae Data Set
The data used in the tutorial can be downloaded from Fannie Mae’s website. We will just be using the 2018 Q1 Acquisition and Performance data set.

A few quick points:
-
The 2018 Q1 Performance Data Set we will use is 4.6M rows, enough to send Excel to a grinding hault, crashing your computer in the process.
-
For dplyr, it’s actually do-able at 4.6M rows. However, if we were to do the full 25GB, we’d definitely want to use data.table to speed things up.
-
We’ll do a series of common data manipulation operations including joins and grouped time series calculation to determine which loans become delinquent in the next 3 months.
4.3 Install and Load Libraries
In this tutorial, we’ll use the latest Development Version of dtplyr installed using devtools. All other packages used can be used by installing with install.packages().
devtools::install_github("tidyverse/dtplyr")
Next, we’ll load the the following libraries with library():
data.table: High-performance data wranglingdtplyr: Interface between dplyr and data.tabletidyverse: Loads dplyr and several other useful R packagesvroom: Fast reading of delimited files (e.g. csv) with vroom()tictoc: Simple timing operationsknitr: Use the kable() function for nice HTML tables
# Load data.table & dtplyr interface
library(data.table)
library(dtplyr)
# Core Tidyverse - Loads dplyr
library(tidyverse)
# Fast reading of delimited files (e.g. csv)
library(vroom) # vroom()
# Timing operations
library(tictoc)
# Table Printing
library(knitr) # kable()
4.4 Read the Data
We’ll read the data. The column-types are going to be pre-specified to assist in the loading process. The vroom() function does the heavy lifting.
First, I’ll setup the paths to the two files I’ll be reading:
- Acquisitions_2018Q1.txt - Meta-data about each loan
- Performance_2018Q1.txt - Time series data set with loan performance characteristics over time
For me, the files are stored in a folder called 2019-08-15-dtplyr. Your paths may be different depending on where the files are stored.
# Paths to files
path_acq <- "2019-08-15-dtplyr/Acquisition_2018Q1.txt"
path_perf <- "2019-08-15-dtplyr/Performance_2018Q1.txt"
Read the Loan Acquisition Data
Note we specify the columns and types to improve the speed of reading the columns.
# Loan Acquisitions Data
col_types_acq <- list(
loan_id = col_factor(),
original_channel = col_factor(NULL),
seller_name = col_factor(NULL),
original_interest_rate = col_double(),
original_upb = col_integer(),
original_loan_term = col_integer(),
original_date = col_date("%m/%Y"),
first_pay_date = col_date("%m/%Y"),
original_ltv = col_double(),
original_cltv = col_double(),
number_of_borrowers = col_double(),
original_dti = col_double(),
original_borrower_credit_score = col_double(),
first_time_home_buyer = col_factor(NULL),
loan_purpose = col_factor(NULL),
property_type = col_factor(NULL),
number_of_units = col_integer(),
occupancy_status = col_factor(NULL),
property_state = col_factor(NULL),
zip = col_integer(),
primary_mortgage_insurance_percent = col_double(),
product_type = col_factor(NULL),
original_coborrower_credit_score = col_double(),
mortgage_insurance_type = col_double(),
relocation_mortgage_indicator = col_factor(NULL))
acquisition_data <- vroom(
file = path_acq,
delim = "|",
col_names = names(col_types_acq),
col_types = col_types_acq,
na = c("", "NA", "NULL"))
The loan acquisition data contains information about the owner of the loan.
acquisition_data %>% head() %>% kable()
| loan_id |
original_channel |
seller_name |
original_interest_rate |
original_upb |
original_loan_term |
original_date |
first_pay_date |
original_ltv |
original_cltv |
number_of_borrowers |
original_dti |
original_borrower_credit_score |
first_time_home_buyer |
loan_purpose |
property_type |
number_of_units |
occupancy_status |
property_state |
zip |
primary_mortgage_insurance_percent |
product_type |
original_coborrower_credit_score |
mortgage_insurance_type |
relocation_mortgage_indicator |
| 100001040173 |
R |
QUICKEN LOANS INC. |
4.250 |
453000 |
360 |
2018-01-01 |
2018-03-01 |
65 |
65 |
1 |
28 |
791 |
N |
C |
PU |
1 |
P |
OH |
430 |
NA |
FRM |
NA |
NA |
N |
| 100002370993 |
C |
WELLS FARGO BANK, N.A. |
4.250 |
266000 |
360 |
2018-01-01 |
2018-03-01 |
80 |
80 |
2 |
41 |
736 |
N |
R |
PU |
1 |
P |
IN |
467 |
NA |
FRM |
793 |
NA |
N |
| 100005405807 |
R |
PMTT4 |
3.990 |
233000 |
360 |
2017-12-01 |
2018-01-01 |
79 |
79 |
2 |
48 |
696 |
N |
R |
SF |
1 |
P |
CA |
936 |
NA |
FRM |
665 |
NA |
N |
| 100008071646 |
R |
OTHER |
4.250 |
184000 |
360 |
2018-01-01 |
2018-03-01 |
80 |
80 |
1 |
48 |
767 |
Y |
P |
PU |
1 |
P |
FL |
336 |
NA |
FRM |
NA |
NA |
N |
| 100010739040 |
R |
OTHER |
4.250 |
242000 |
360 |
2018-02-01 |
2018-04-01 |
49 |
49 |
1 |
22 |
727 |
N |
R |
SF |
1 |
P |
CA |
906 |
NA |
FRM |
NA |
NA |
N |
| 100012691523 |
R |
OTHER |
5.375 |
180000 |
360 |
2018-01-01 |
2018-03-01 |
80 |
80 |
1 |
14 |
690 |
N |
C |
PU |
1 |
P |
OK |
730 |
NA |
FRM |
NA |
NA |
N |
Get the size of the acquisitions data set: 426K rows by 25 columns. Not that bad, but this is meta-data for the loan. The dataset we are worried about is the next one.
dim(acquisition_data)
## [1] 426207 25
# Loan Performance Data
col_types_perf = list(
loan_id = col_factor(),
monthly_reporting_period = col_date("%m/%d/%Y"),
servicer_name = col_factor(NULL),
current_interest_rate = col_double(),
current_upb = col_double(),
loan_age = col_double(),
remaining_months_to_legal_maturity = col_double(),
adj_remaining_months_to_maturity = col_double(),
maturity_date = col_date("%m/%Y"),
msa = col_double(),
current_loan_delinquency_status = col_double(),
modification_flag = col_factor(NULL),
zero_balance_code = col_factor(NULL),
zero_balance_effective_date = col_date("%m/%Y"),
last_paid_installment_date = col_date("%m/%d/%Y"),
foreclosed_after = col_date("%m/%d/%Y"),
disposition_date = col_date("%m/%d/%Y"),
foreclosure_costs = col_double(),
prop_preservation_and_repair_costs = col_double(),
asset_recovery_costs = col_double(),
misc_holding_expenses = col_double(),
holding_taxes = col_double(),
net_sale_proceeds = col_double(),
credit_enhancement_proceeds = col_double(),
repurchase_make_whole_proceeds = col_double(),
other_foreclosure_proceeds = col_double(),
non_interest_bearing_upb = col_double(),
principal_forgiveness_upb = col_double(),
repurchase_make_whole_proceeds_flag = col_factor(NULL),
foreclosure_principal_write_off_amount = col_double(),
servicing_activity_indicator = col_factor(NULL))
performance_data <- vroom(
file = path_perf,
delim = "|",
col_names = names(col_types_perf),
col_types = col_types_perf,
na = c("", "NA", "NULL"))
Let’s inspect the data. We can see that this is a time series where each “Loan ID” and “Monthly Reporting Period” go together.
performance_data %>% head() %>% kable()
| loan_id |
monthly_reporting_period |
servicer_name |
current_interest_rate |
current_upb |
loan_age |
remaining_months_to_legal_maturity |
adj_remaining_months_to_maturity |
maturity_date |
msa |
current_loan_delinquency_status |
modification_flag |
zero_balance_code |
zero_balance_effective_date |
last_paid_installment_date |
foreclosed_after |
disposition_date |
foreclosure_costs |
prop_preservation_and_repair_costs |
asset_recovery_costs |
misc_holding_expenses |
holding_taxes |
net_sale_proceeds |
credit_enhancement_proceeds |
repurchase_make_whole_proceeds |
other_foreclosure_proceeds |
non_interest_bearing_upb |
principal_forgiveness_upb |
repurchase_make_whole_proceeds_flag |
foreclosure_principal_write_off_amount |
servicing_activity_indicator |
| 100001040173 |
2018-02-01 |
QUICKEN LOANS INC. |
4.25 |
NA |
0 |
360 |
360 |
2048-02-01 |
18140 |
0 |
N |
|
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
|
NA |
N |
| 100001040173 |
2018-03-01 |
|
4.25 |
NA |
1 |
359 |
359 |
2048-02-01 |
18140 |
0 |
N |
|
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
|
NA |
N |
| 100001040173 |
2018-04-01 |
|
4.25 |
NA |
2 |
358 |
358 |
2048-02-01 |
18140 |
0 |
N |
|
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
|
NA |
N |
| 100001040173 |
2018-05-01 |
|
4.25 |
NA |
3 |
357 |
357 |
2048-02-01 |
18140 |
0 |
N |
|
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
|
NA |
N |
| 100001040173 |
2018-06-01 |
|
4.25 |
NA |
4 |
356 |
356 |
2048-02-01 |
18140 |
0 |
N |
|
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
|
NA |
N |
| 100001040173 |
2018-07-01 |
|
4.25 |
NA |
5 |
355 |
355 |
2048-02-01 |
18140 |
0 |
N |
|
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
|
NA |
N |
Let’s check out the data size. We can see it’s 4.6M rows by 31 columns! Just a typical financial time series (seriously).
dim(performance_data)
## [1] 4645448 31
4.5 Convert to Tibbles to dtplyr Steps
Next, we’ll use the lazy_dt() function to convert the tibbles to dtplyr steps.
acquisition_data_dtplyr <- lazy_dt(acquisition_data)
performance_data_dtplyr <- lazy_dt(performance_data)
We can check the class() to see what we are working with.
class(acquisition_data_dtplyr)
## [1] "dtplyr_step_first" "dtplyr_step"
The returned object is the first step in a dtplyr sequence.
Key Point:
- We are going to set up operations using a sequence of steps.
- The operations will not be fully evaluated until we convert to a
data.table or tibble depending on our desired output.
4.6 Join the Data Sets
Our first data manipulation operation is a join. We are going to use the left_join() function from dplyr. Let’s see what happens.
combined_dtplyr <- performance_data_dtplyr %>%
left_join(acquisition_data_dtplyr)
The output of the joining operation is a new step sequence, this time a dtplyr_step_subset.
class(combined_dtplyr)
## [1] "dtplyr_step_subset" "dtplyr_step"
Next, let’s examine what happens when we print combined_dt to the console.
combined_dtplyr
## Source: local data table [?? x 55]
## Call: `_DT2`[`_DT1`, on = .(loan_id)]
##
## loan_id monthly_reporti… servicer_name current_interes… current_upb
## <fct> <date> <fct> <dbl> <dbl>
## 1 100001… 2018-02-01 QUICKEN LOAN… 4.25 NA
## 2 100001… 2018-03-01 "" 4.25 NA
## 3 100001… 2018-04-01 "" 4.25 NA
## 4 100001… 2018-05-01 "" 4.25 NA
## 5 100001… 2018-06-01 "" 4.25 NA
## 6 100001… 2018-07-01 "" 4.25 NA
## # … with 50 more variables: loan_age <dbl>,
## # remaining_months_to_legal_maturity <dbl>,
## # adj_remaining_months_to_maturity <dbl>, maturity_date <date>,
## # msa <dbl>, current_loan_delinquency_status <dbl>,
## # modification_flag <fct>, zero_balance_code <fct>,
## # zero_balance_effective_date <date>,
## # last_paid_installment_date <date>, foreclosed_after <date>,
## # disposition_date <date>, foreclosure_costs <dbl>,
## # prop_preservation_and_repair_costs <dbl>,
## # asset_recovery_costs <dbl>, misc_holding_expenses <dbl>,
## # holding_taxes <dbl>, net_sale_proceeds <dbl>,
## # credit_enhancement_proceeds <dbl>,
## # repurchase_make_whole_proceeds <dbl>,
## # other_foreclosure_proceeds <dbl>, non_interest_bearing_upb <dbl>,
## # principal_forgiveness_upb <dbl>,
## # repurchase_make_whole_proceeds_flag <fct>,
## # foreclosure_principal_write_off_amount <dbl>,
## # servicing_activity_indicator <fct>, original_channel <fct>,
## # seller_name <fct>, original_interest_rate <dbl>,
## # original_upb <int>, original_loan_term <int>,
## # original_date <date>, first_pay_date <date>, original_ltv <dbl>,
## # original_cltv <dbl>, number_of_borrowers <dbl>,
## # original_dti <dbl>, original_borrower_credit_score <dbl>,
## # first_time_home_buyer <fct>, loan_purpose <fct>,
## # property_type <fct>, number_of_units <int>,
## # occupancy_status <fct>, property_state <fct>, zip <int>,
## # primary_mortgage_insurance_percent <dbl>, product_type <fct>,
## # original_coborrower_credit_score <dbl>,
## # mortgage_insurance_type <dbl>,
## # relocation_mortgage_indicator <fct>
##
## # Use as.data.table()/as.data.frame()/as_tibble() to access results
Key Points:
-
The important piece is the data.table translation code, which we can see in the ouput: Call: _DT2[_DT1, on = .(loan_id)]
-
Note that we haven’t excecuted the data manipulation operation. dtplyr smartly gives us a glimpse of what the operation will look like though, which is really cool.
4.7 Wrangle the Data
We’ll do a sequence of data wrangling operations:
- Select specific columns we want to keep
- Arrange by
loan_id and monthly_reporting_period. This is needed to keep groups together and in the right time-stamp order.
- Group by
loan_id and mutate to calculate whether or not loans become delinquent in the next 3 months.
- Filter rows with
NA values from the newly created column (these aren’t needed)
- Reorder the columns to put the new calculated column first.
final_output_dtplyr <- combined_dtplyr %>%
select(loan_id, monthly_reporting_period,
current_loan_delinquency_status) %>%
arrange(loan_id, monthly_reporting_period) %>%
group_by(loan_id) %>%
mutate(gt_1mo_behind_in_3mo = lead(current_loan_delinquency_status, n = 3) >= 1) %>%
ungroup() %>%
filter(!is.na(gt_1mo_behind_in_3mo)) %>%
select(gt_1mo_behind_in_3mo, everything())
The final output is a dtplyr_step_group, which is just a sequence of steps.
class(final_output_dtplyr)
## [1] "dtplyr_step_group" "dtplyr_step"
If we print the final_output_dt object, we can see the data.table translation is pretty intense.
final_output_dtplyr
## Source: local data table [?? x 4]
## Call: `_DT2`[`_DT1`, .(loan_id, monthly_reporting_period, current_loan_delinquency_status),
## on = .(loan_id)][order(loan_id, monthly_reporting_period)][,
## `:=`(gt_1mo_behind_in_3mo = lead(current_loan_delinquency_status,
## n = 3) >= 1), keyby = .(loan_id)][!is.na(gt_1mo_behind_in_3mo),
## .(gt_1mo_behind_in_3mo, loan_id, monthly_reporting_period,
## current_loan_delinquency_status)]
##
## gt_1mo_behind_in_… loan_id monthly_reporting… current_loan_delinq…
## <lgl> <fct> <date> <dbl>
## 1 FALSE 10000104… 2018-02-01 0
## 2 FALSE 10000104… 2018-03-01 0
## 3 FALSE 10000104… 2018-04-01 0
## 4 FALSE 10000104… 2018-05-01 0
## 5 FALSE 10000104… 2018-06-01 0
## 6 FALSE 10000104… 2018-07-01 0
##
## # Use as.data.table()/as.data.frame()/as_tibble() to access results
Key Point:
- The most important piece is that
dtplyr correctly converted the grouped mutation to an inplace calculation, which is data.table speak for a super-fast calculation that makes no copies of the data. Here’s inplace calculation code from the dtplyr translation: [, :=(gt_1mo_behind_in_3mo = lead(current_loan_delinquency_status, n = 3) >= 1), keyby = .(loan_id)]
4.8 Collecting The Data
Note that up until now, nothing has been done to process the data - we’ve just created a recipe for data wrangling. We still need tell dtplyr to execute the data wrangling operations.
To implement all of the steps and convert the dtplyr sequence to a tibble, we just call as_tibble().
final_output_dtplyr %>% as_tibble()
## # A tibble: 3,352,231 x 4
## gt_1mo_behind_in_… loan_id monthly_reporting… current_loan_delinq…
## <lgl> <fct> <date> <dbl>
## 1 FALSE 1000010… 2018-02-01 0
## 2 FALSE 1000010… 2018-03-01 0
## 3 FALSE 1000010… 2018-04-01 0
## 4 FALSE 1000010… 2018-05-01 0
## 5 FALSE 1000010… 2018-06-01 0
## 6 FALSE 1000010… 2018-07-01 0
## 7 FALSE 1000010… 2018-08-01 0
## 8 FALSE 1000010… 2018-09-01 0
## 9 FALSE 1000023… 2018-03-01 0
## 10 FALSE 1000023… 2018-04-01 0
## # … with 3,352,221 more rows
Key Point:
- Calling the
as_tibble() function tells dtplyr to execute the data.table wrangling operations.
5.0 The 3X Speedup - Time Comparisons
Finally, let’s check the performance of the dplyr vs dtplyr vs data.table. We can seed a nice 3X speed boost!
5.1 Time using dplyr
tic()
performance_data %>%
left_join(acquisition_data) %>%
select(loan_id, monthly_reporting_period,
current_loan_delinquency_status) %>%
arrange(loan_id, monthly_reporting_period) %>%
group_by(loan_id) %>%
mutate(gt_1mo_behind_in_3mo = lead(current_loan_delinquency_status, n = 3) >= 1) %>%
ungroup() %>%
filter(!is.na(gt_1mo_behind_in_3mo)) %>%
select(gt_1mo_behind_in_3mo, everything())
toc()
## 15.905 sec elapsed
5.2 Time using dtplyr
tic()
performance_data_dtplyr %>%
left_join(acquisition_data_dtplyr) %>%
select(loan_id, monthly_reporting_period,
current_loan_delinquency_status) %>%
arrange(loan_id, monthly_reporting_period) %>%
group_by(loan_id) %>%
mutate(gt_1mo_behind_in_3mo = lead(current_loan_delinquency_status, n = 3) >= 1) %>%
ungroup() %>%
filter(!is.na(gt_1mo_behind_in_3mo)) %>%
select(gt_1mo_behind_in_3mo, everything()) %>%
as_tibble()
toc()
## 4.821 sec elapsed
5.3 Time using data.table
DT1 <- as.data.table(performance_data)
DT2 <- as.data.table(acquisition_data)
tic()
DT2[DT1, .(loan_id, monthly_reporting_period, current_loan_delinquency_status), on = .(loan_id)] %>%
.[order(loan_id, monthly_reporting_period)] %>%
.[, gt_1mo_behind_in_3mo := lead(current_loan_delinquency_status, n = 3) >= 1, keyby = .(loan_id)] %>%
.[!is.na(gt_1mo_behind_in_3mo), .(gt_1mo_behind_in_3mo, loan_id, monthly_reporting_period, current_loan_delinquency_status)]
toc()
## 4.627 sec elapsed
6.0 Conclusions and Learning Recommendations
For Big Data wrangling, the dtplyr package represents a huge opportunity for data scientists to leverage the speed of data.table with the readability of dplyr. We saw an impressive 3X Speedup going from dplyr to using dtplyr for wrangling a 4.6M row data set. This just scratches the surface of the potential, and I’m looking forward to seeing dtplyr mature, which will help bridge the gap between the two groups of data scientists using dplyr and data.table.
For new data scientists coming from other tools like Excel, my hope is that you see the awesome potential of learning R for data analysis and data science. The Big Data capabilities represent a massive opportunity for you to bring your organization data science at scale.
You just need to learn how to go from normal data to Big Data.
My recommendation is to start by learning dplyr - The popular data manipulation library that makes reading and writing R code very easy to understand.
Once you get to an intermediate level, learn data.table. This is where you gain the benefits of scaling data science to Big Data. The data.table package has a steeper learning curve, but learning it will help you leverage its full performance and scalability.
If you need to learn dplyr as fast as possible - I recommend beginning with our Data Science Foundations DS4B 101-R Course. The 101 Course is available as part of the R-Track System, a complete learning system designed to transform you from beginner to advanced in under 6-months. You will learn everything you need to become an expert data scientist.
7.0 Additional Big Data Guidelines
I find that students have an easier time picking a tool based on dataset row size (e.g. I have 10M rows, what should I use?). With that said, there are 2 factors that will influence whhich tools you need to use:
-
Are you performing Grouped and Iterative Operations? Performance even on normal data sets can become an issue if you have a lot of groups or if the calculation is iterative. A particular source of pain in the financial realm are rolling (window) calculations, which are both grouped and iterative within groups. In these situation, use high-performance C++ functions (e.g. Rolling functions from the roll package or RcppRoll package).
-
Do you have sufficient RAM? Once you begin working with gig’s of data, then you start to run out of memory (RAM). In these situations, you will need to work in chunks and parellelizing operations. You can do this with distributed sparklyr, which will perform some operations in parallel and distribute across nodes.
8.0 Recognizing the Developers
I’d like to take a quick moment to thank the developers of data.table and dplyr. Without these two packages, Business Science probably would not exist. Thank you.