Introducing correlationfunnel v0.1.0 - Speed Up Exploratory Data Analysis by 100X
Written by Matt Dancho
I’m pleased to announce the introduction of correlationfunnel version 0.1.0, which officially hit CRAN yesterday. The correlationfunnel package is a tool that enables efficient exploration of data, understanding relationships, and get to business insights as fast as possible. I’ve taught correlationfunnel to my 500+ students enrolled in the Advanced Machine Learning course (DS4B 201-R) at Business Science University. The results have been great so far. Students are using it as the EDA step prior to Machine Learning to ensure that features have relationship before they spend significant time tuning ML models on bad data. It’s helped me get to business insights 100X faster, which has been a massive productivity boost. And, it’s a great communication tool that has helped explain business insights to executives and project stakeholders! Win-win-win.
Why do I teach the correlationfunnel? Why is it an 80/20 tool that I use in every analysis? Why is it so great for communication?
It’s because of the Correlation Funnel Visualization. The correlation funnel succinctly explains relationships to the target feature. Plus, every executive and business leader understands correlation. So it makes it super easy to explain results.
Here’s the correlation funnel that we’ll make in the 2-Minute Case Study - Bank Marketing Campaign. It’s examining a Marketing Campaign for a Bank (provided by the UCI Machine Learning Repository). Without knowing much about the data, we can see that the most important features (those with highest absolute correlation) go to the top. This is the crux of business insights - We know know which features are important, without spending significant time on machine learning. Further, we can make educated guesses about the story within the data (great for communicating with stakeholders).
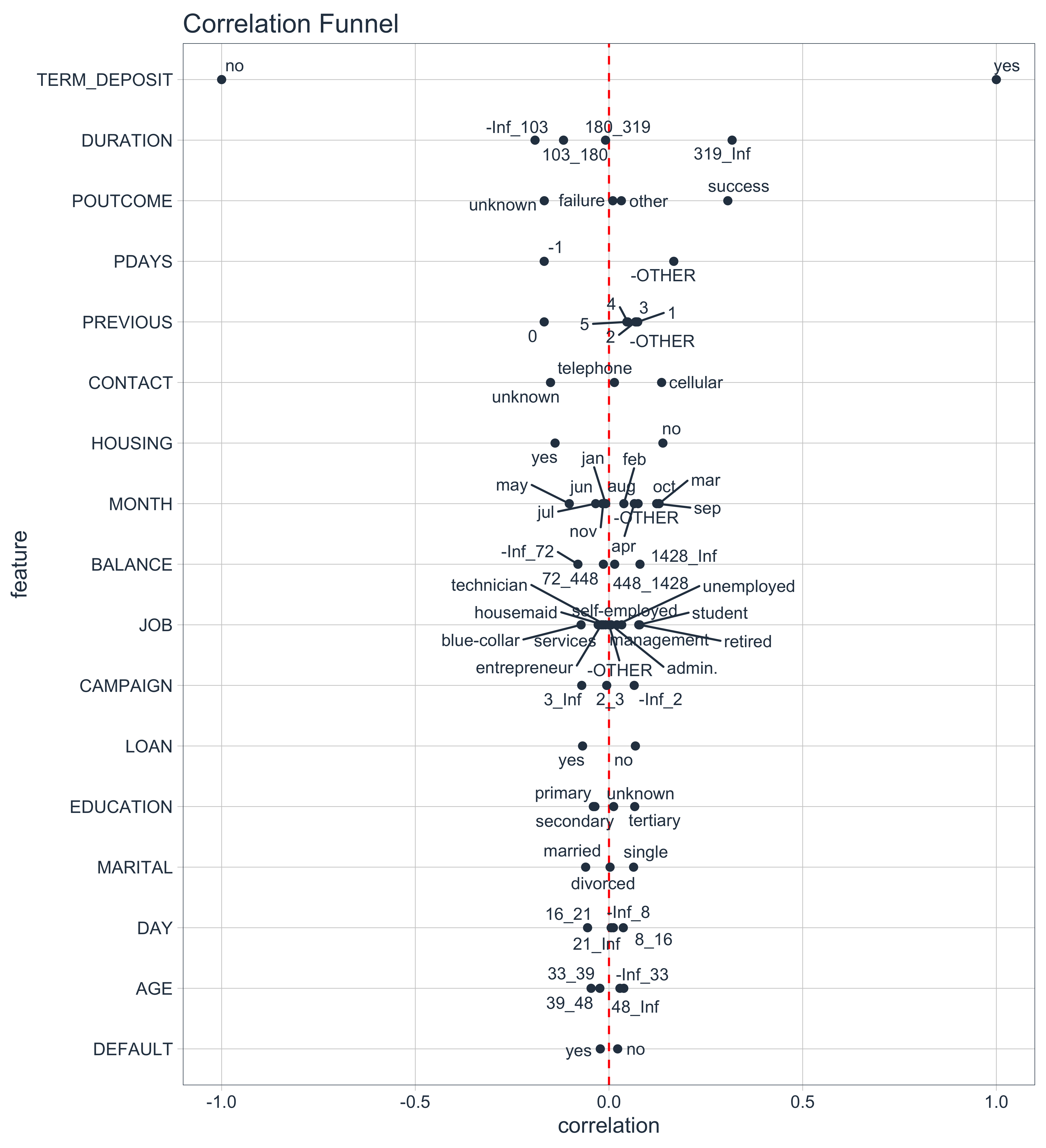
Correlation Funnel Visualization - Important Features go to the Top
Table of Contents
-
Two-Minute Case Study - Bank Marketing Campaign
-
Other Great EDA Packages
-
What do you think of Correlation Funnel?
-
Help Others Learn R - Share this article
-
New Expert Shiny Course - Coming Soon!
1. Bank Marketing Campaign Case Study - 2 Minute Example
The following case study showcases the power of fast exploratory correlation analysis with correlationfunnel. The goal of the analysis is to determine which features relate to the bank’s marketing campaign goal of having customers opt into a TERM DEPOSIT (financial product).
We will see that using 3 functions, we can quickly:
-
Transform the data into a binary format with binarize()
-
Perform correlation analysis using correlate()
-
Visualize the highest correlation features using plot_correlation_funnel()
Result:
Rather than spend hours looking at individual plots of campaign features and comparing them to which customers opted in to the TERM DEPOSIT product, in seconds we can discover which groups of customers have enrolled, drastically speeding up EDA.
Getting Started
First, install correlationfunnel with:
install.packages("correlationfunnel")
Next, load the following libraries.
library(correlationfunnel)
library(dplyr)
Next, collect data to analyze. We’ll use Marketing Campaign Data for a Bank that was popularized by the UCI Machine Learning Repository. We can load the data with data("marketing_campaign_tbl").
# Use ?marketing_campagin_tbl to get a description of the marketing campaign features
data("marketing_campaign_tbl")
marketing_campaign_tbl %>% glimpse()
## Observations: 45,211
## Variables: 18
## $ ID <chr> "2836", "2837", "2838", "2839", "2840", "2841"…
## $ AGE <dbl> 58, 44, 33, 47, 33, 35, 28, 42, 58, 43, 41, 29…
## $ JOB <chr> "management", "technician", "entrepreneur", "b…
## $ MARITAL <chr> "married", "single", "married", "married", "si…
## $ EDUCATION <chr> "tertiary", "secondary", "secondary", "unknown…
## $ DEFAULT <chr> "no", "no", "no", "no", "no", "no", "no", "yes…
## $ BALANCE <dbl> 2143, 29, 2, 1506, 1, 231, 447, 2, 121, 593, 2…
## $ HOUSING <chr> "yes", "yes", "yes", "yes", "no", "yes", "yes"…
## $ LOAN <chr> "no", "no", "yes", "no", "no", "no", "yes", "n…
## $ CONTACT <chr> "unknown", "unknown", "unknown", "unknown", "u…
## $ DAY <dbl> 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5…
## $ MONTH <chr> "may", "may", "may", "may", "may", "may", "may…
## $ DURATION <dbl> 261, 151, 76, 92, 198, 139, 217, 380, 50, 55, …
## $ CAMPAIGN <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ PDAYS <dbl> -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1…
## $ PREVIOUS <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ POUTCOME <chr> "unknown", "unknown", "unknown", "unknown", "u…
## $ TERM_DEPOSIT <chr> "no", "no", "no", "no", "no", "no", "no", "no"…
Response & Predictor Relationships
Modeling and Machine Learning problems often involve a response (Enrolled in TERM_DEPOSIT, yes/no) and many predictors (AGE, JOB, MARITAL, etc). Our job is to determine which predictors are related to the response. We can do this through Binary Correlation Analysis.
Binary Correlation Analysis
Binary Correlation Analysis is the process of converting continuous (numeric) and categorical (character/factor) data to binary features. We can then perform a correlation analysis to see if there is predictive value between the features and the response (target). Refer to Methodology, Key Considerations, and FAQs Documentation for more information on the methodology.
The first step is converting the continuous and categorical data into binary (0/1) format. We de-select any non-predictive features. The binarize() function then converts the features into binary features.
-
Numeric Features: Are binned into ranges or if few unique levels are binned by their value, and then converted to binary features via one-hot encoding
-
Categorical Features: Are binned by one-hot encoding
The result is a data frame that has only binary data with columns representing the bins that the observations fall into. There are now 74 columns that are binary (0/1). Note that the output was trimmed to the first 10 rows using slice().
marketing_campaign_binarized_tbl <- marketing_campaign_tbl %>%
select(-ID) %>%
binarize(n_bins = 4, thresh_infreq = 0.01)
marketing_campaign_binarized_tbl %>%
slice(1:10) %>%
knitr::kable()
| AGE__-Inf_33 |
AGE__33_39 |
AGE__39_48 |
AGE__48_Inf |
JOB__admin. |
JOB__blue-collar |
JOB__entrepreneur |
JOB__housemaid |
JOB__management |
JOB__retired |
JOB__self-employed |
JOB__services |
JOB__student |
JOB__technician |
JOB__unemployed |
JOB__-OTHER |
MARITAL__divorced |
MARITAL__married |
MARITAL__single |
EDUCATION__primary |
EDUCATION__secondary |
EDUCATION__tertiary |
EDUCATION__unknown |
DEFAULT__no |
DEFAULT__yes |
BALANCE__-Inf_72 |
BALANCE__72_448 |
BALANCE__448_1428 |
BALANCE__1428_Inf |
HOUSING__no |
HOUSING__yes |
LOAN__no |
LOAN__yes |
CONTACT__cellular |
CONTACT__telephone |
CONTACT__unknown |
DAY__-Inf_8 |
DAY__8_16 |
DAY__16_21 |
DAY__21_Inf |
MONTH__apr |
MONTH__aug |
MONTH__feb |
MONTH__jan |
MONTH__jul |
MONTH__jun |
MONTH__mar |
MONTH__may |
MONTH__nov |
MONTH__oct |
MONTH__sep |
MONTH__-OTHER |
DURATION__-Inf_103 |
DURATION__103_180 |
DURATION__180_319 |
DURATION__319_Inf |
CAMPAIGN__-Inf_2 |
CAMPAIGN__2_3 |
CAMPAIGN__3_Inf |
PDAYS__-1 |
PDAYS__-OTHER |
PREVIOUS__0 |
PREVIOUS__1 |
PREVIOUS__2 |
PREVIOUS__3 |
PREVIOUS__4 |
PREVIOUS__5 |
PREVIOUS__-OTHER |
POUTCOME__failure |
POUTCOME__other |
POUTCOME__success |
POUTCOME__unknown |
TERM_DEPOSIT__no |
TERM_DEPOSIT__yes |
| 0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
| 0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
| 1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
| 0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
| 1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
| 0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
| 1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
| 0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
| 0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
| 0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
The second step is to perform a correlation analysis between the response (target = TERM_DEPOSIT_yes) and the rest of the features. This returns a specially formatted tibble with the feature, the bin, and the bin’s correlation to the target. The format is exactly what we need for the next step - Producing the Correlation Funnel
marketing_campaign_correlated_tbl <- marketing_campaign_binarized_tbl %>%
correlate(target = TERM_DEPOSIT__yes)
marketing_campaign_correlated_tbl
## # A tibble: 74 x 3
## feature bin correlation
## <fct> <chr> <dbl>
## 1 TERM_DEPOSIT no -1.000
## 2 TERM_DEPOSIT yes 1.000
## 3 DURATION 319_Inf 0.318
## 4 POUTCOME success 0.307
## 5 DURATION -Inf_103 -0.191
## 6 PDAYS -OTHER 0.167
## 7 PDAYS -1 -0.167
## 8 PREVIOUS 0 -0.167
## 9 POUTCOME unknown -0.167
## 10 CONTACT unknown -0.151
## # … with 64 more rows
Step 3: Visualize the Correlation Funnel
A Correlation Funnel is an tornado plot that lists the highest correlation features (based on absolute magnitude) at the top of the and the lowest correlation features at the bottom. The resulting visualization looks like a Funnel.
To produce the Correlation Funnel, use plot_correlation_funnel(). Try setting interactive = TRUE to get an interactive plot that can be zoomed in on.
marketing_campaign_correlated_tbl %>%
plot_correlation_funnel(interactive = FALSE)
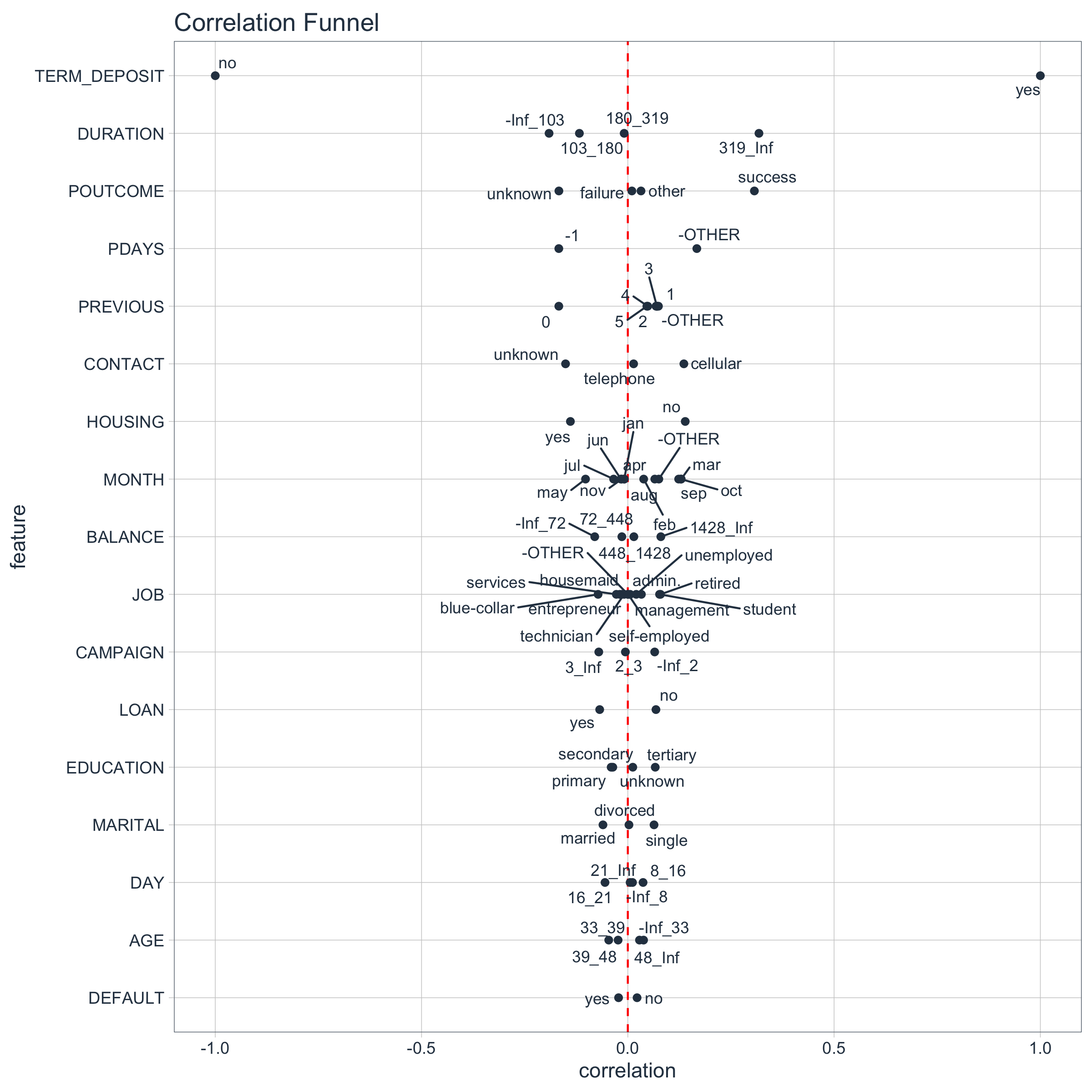
Examining the Results
The most important features are towards the top. We can investigate these.
marketing_campaign_correlated_tbl %>%
filter(feature %in% c("DURATION", "POUTCOME", "PDAYS",
"PREVIOUS", "CONTACT", "HOUSING")) %>%
plot_correlation_funnel(interactive = FALSE, limits = c(-0.4, 0.4))
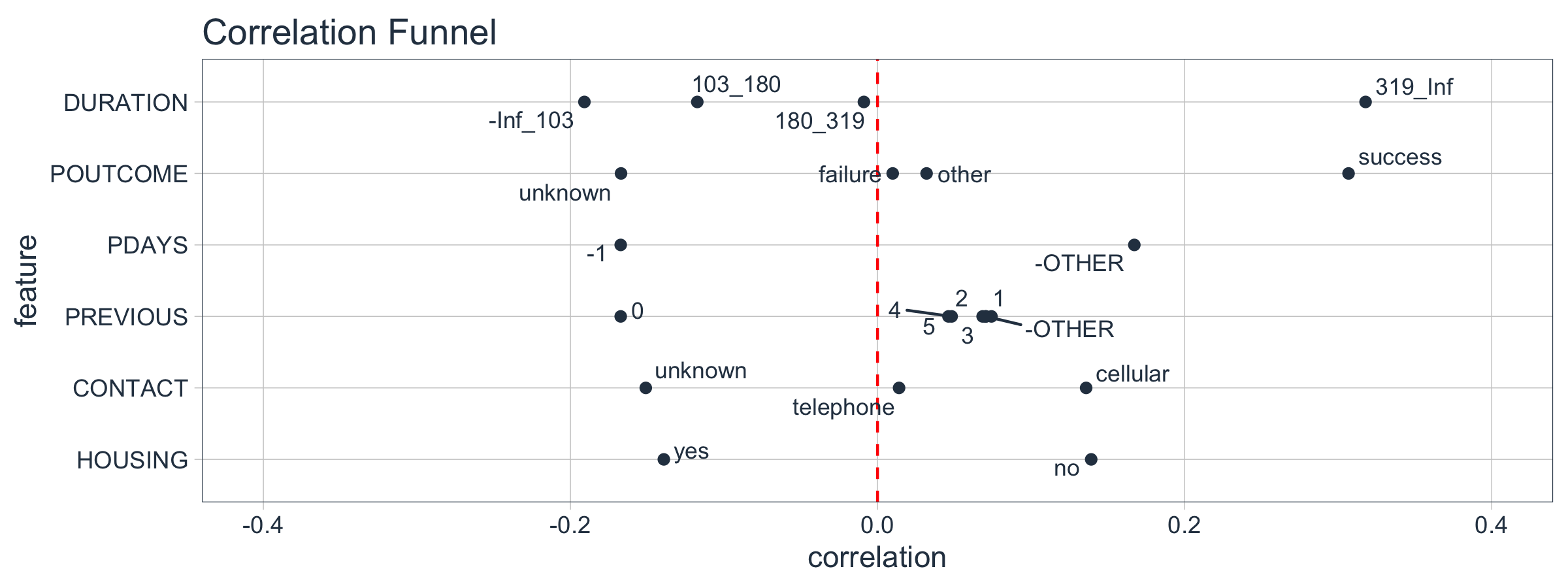
We can see that the following prospect groups have a much greater correlation with enrollment in the TERM DEPOSIT product:
-
When the “DURATION”, the amount of time a prospect is engaged in marketing campaign material, is 319 seconds or longer.
-
When “POUTCOME”, whether or not a prospect has previously enrolled in a product, is “success”.
-
When “CONTACT”, the medium used to contact the person, is “cellular”
-
When “HOUSING”, whether or not the contact has a HOME LOAN is “no”
2. My EDA Workflow R
The main addition of correlationfunnel to the EDA ecosystem in R is to quickly expose feature relationships.
There are other EDA packages, but none implement the binarization process as a preprocessing step before correlation. This is critical to extracting insights especially in nonlinear continuous data.
Correlation funnel requires semi-processed data meaning
- Missing (
NA) values have been treated
- Date or date-time features have been feature engineered into categorical variables
- Data is in a “clean” format (numeric data and categorical data are ready to be correlated to a Yes/No response)
Because of this, I use other packages to understand data (e.g. missing values) and correct data (preprocessing).
EDA Packages I Use Before I Use Correlation Funnel to identify processing steps
-
GGally - The ggpairs() function is one of my all-time favorites for visualizing many features quickly. I teach GGally in DS4B 201-R, Advanced Machine Learning and Business Consulting, part of the 3-Course R-Track for Business.
-
skimr - The skim() function is my go-to for console statistics on each of my variables. It’s like str() combined with summary() on steroids. I teach skimr in DS4B 201-R, Advanced Machine Learning and Business Consulting, part of the 3-Course R-Track for Business.
-
Data Explorer - Automates Exploration and Data Treatment. Amazing for investigating features quickly and efficiently including by data type, missing data, feature engineering, and identifying relationships.
Packages I use to implement preprocessing
- recipes - This is one of the most important R packages in my exploratory and machine learning workflow. It’s use to create preprocessing pipelines - A series of steps to correct data and prepare for machine learning, correlation analysis, etc. I teach
recipes in DS4B 201-R, Advanced Machine Learning and Business Consulting, part of the 3-Course R-Track for Business.
Other Great EDA Packages (Notable Mentions)
-
VisDat - Similar in concept to Data Explorer. Utilities for visualizing missing data
-
naniar - For understanding missing data.
-
UpSetR - For generating upset plots
Let me know what to do you think of correlationfunnel in the comments. I’m interested in getting your feedback on how it works on different data sets. I’ve tried it on a ton, but that doesn’t mean that it’s perfect. Let me know your results - good or bad.
4. Help Others Learn R - Share this article if you like it!
Post the article on LinkedIn. Tag Matt Dancho (@Matt Dancho), and I’ll respond!
5. New Expert Shiny Course - Coming Soon!
Expert Shiny Apps! Build these two apps: