How To Learn R, Part 1: Learn From A Master Data Scientist's Code
Written by Matt Dancho
The R programming language is a powerful tool used in data science for business (DS4B), but R can be unnecessarily challenging to learn. We believe you can learn R quickly by taking an 80/20 approach to learning the most in-demand functions and packages. In this article, we seek to ultimately understand what techniques are most critical to a beginners success through analyzing a master data scientist’s code base. Half of this article covers the web scraping procedure (using rvest and purrr) we used to collect our data (if new to R, you can skip this). The second half covers the insights gained from analyzing a master’s code base. In the next article in our series, we’ll develop a strategic learning plan built on our knowledge of the master. Last, there’s a bonus at the end of the article that shows how you can analyze your own code base using the new fs package. Enjoy.
Previous articles in the DS4B series:
Analyzing A Leader Through Their Code
It’s no secret that the R Programming Community has a number of leaders. It’s one of the draws that separates R from the rest of the pack! The leaders have earned their leadership position by making an impact through high-end data science and unselfishly giving back to the community. We can all learn from what they do. The key is dissecting their code bases to understand the tools and techniques they use.
What we’ve done is made a first step in figuring out why these individuals are successful through analyzing their most frequently used tools. We started with one standout, a true master of data science…
David Robinson (Our Master Data Scientist)

We examined David Robinson, Chief Data Scientist at DataCamp (previously StackOverflow) (aka DRob), analyzing his code base by dissecting the functions and packages he uses regularly!
Variance Explained Blog (Where We Got The Data)
DRob actively maintains an excellent blog called Variance Explained. He has 58 articles currently, most with code. We used the rvest package to collect the code contained in each post. We started with one blog post involving mixture models of baseball statistics. We then extended it to all 58 articles to increase our confidence in what tools he frequently uses.
80/20 Analysis For Learning R (What We Did With The Data)
We made several graphs that tell us interesting things about what R functions and packages DRob regularly uses. We then performed an 80/20 analysis on his code base. We output all of the high-usage functions and packages DRob regularly uses at the end of the article. This will be used in our next article developing a strategy to learn R efficiently.
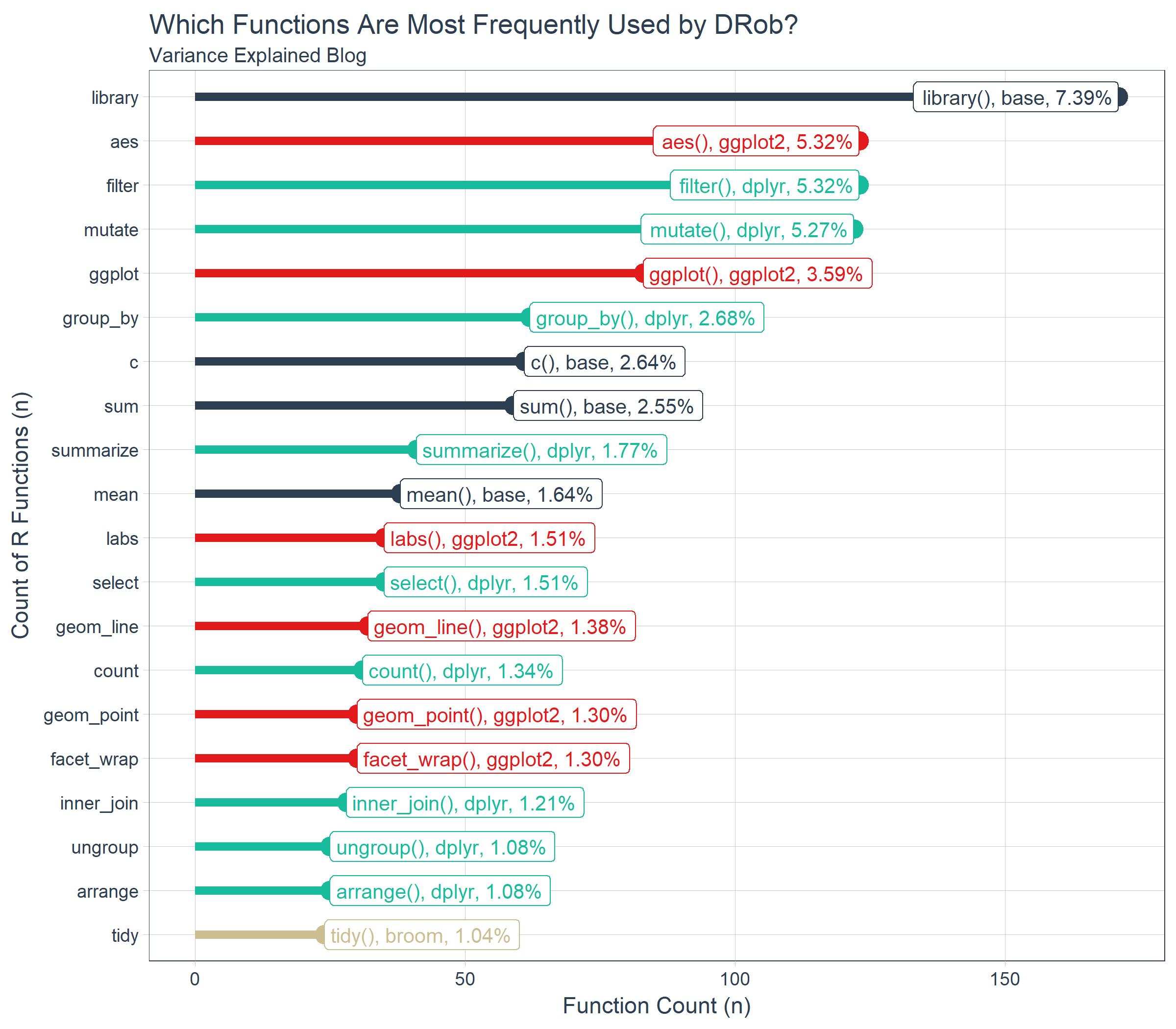
Our first graph helps us answer which functions DRob routinely uses. Here are his top 20 functions.
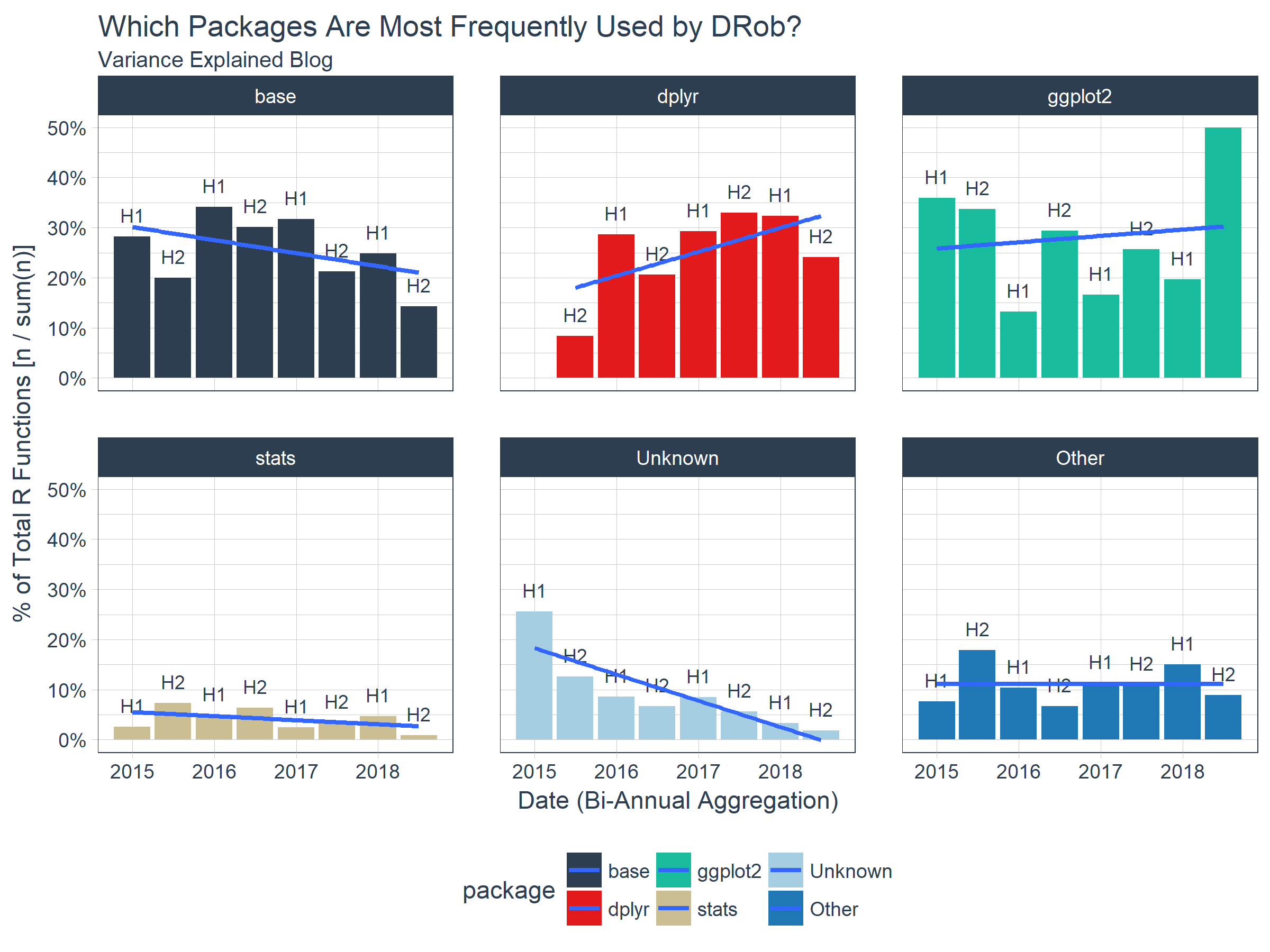
Our second graph helps us understand which packages are most frequently used based on the number of times functions within those packages appear in his code.
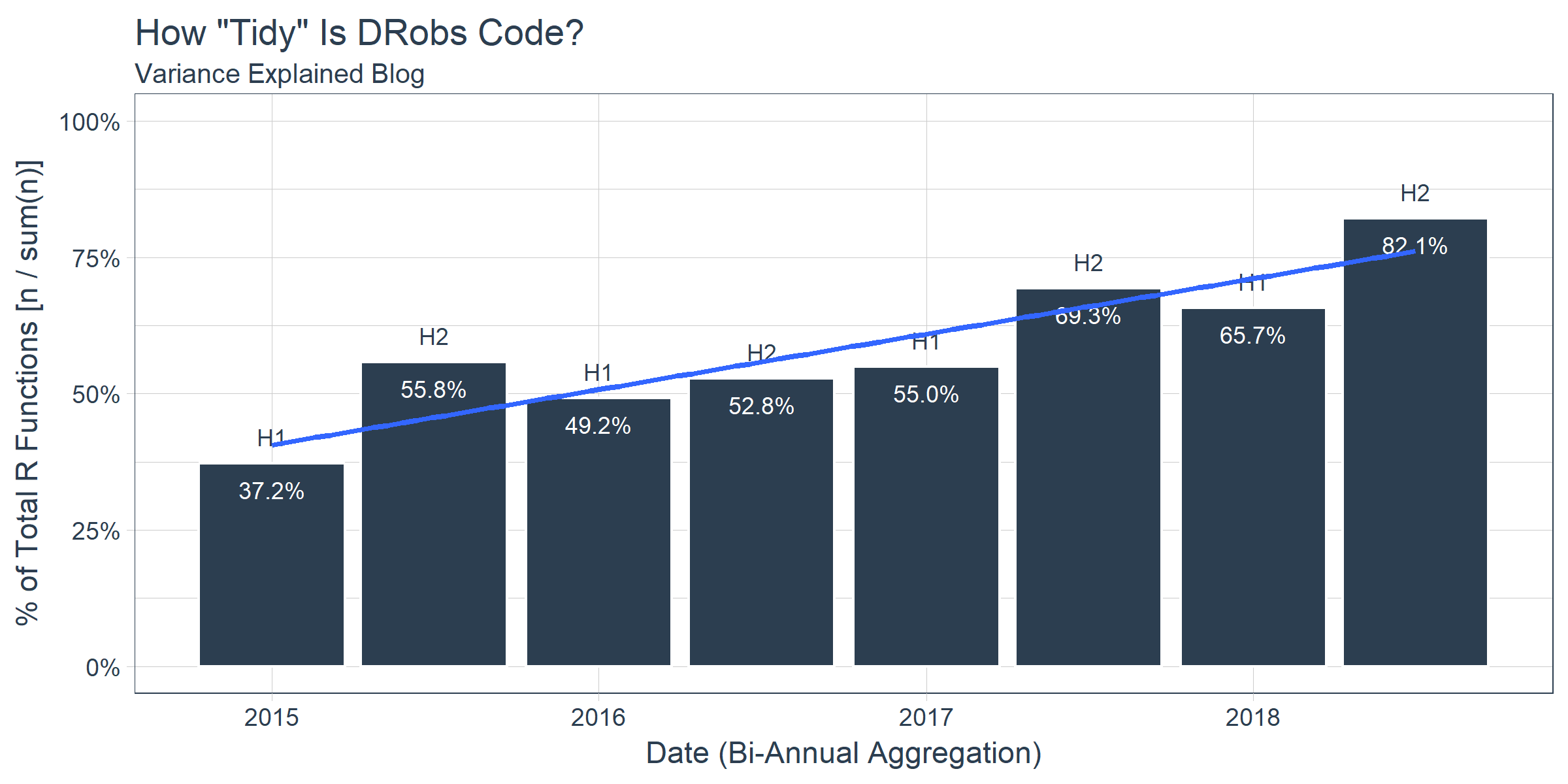
We noticed a theme that DRob is frequently using packages in the “tidyverse” (e.g. dplyr, ggplot2, etc). The third chart shows how “tidy” his code is by measuring the percentage of tidyverse functions vs non-tidyverse functions.
And, finally, we listed out the top 88 functions in our 80/20 analysis. These are the functions he used 80% of the time. Check out the 80/20 list of most frequently used functions below!
Bonus: How to Learn R by Analyzing Your Code
We show as a bonus how you can apply the custom scripts developed in this article to do an analysis on your code with the new fs package (short for file system). We briefly analyze our code base for the HR 201: Predicting Employee Attrition course that is under development for our Business Science University Virtual Workshop on predicting employee turnover and developing Shiny web applications. The Virtual Workshop is coming soon!
Our Hypothesis
Learning R can be unnecessarily challenging if one focuses on learning everything immediately rather than applying a strategic approach. Our hypothesis is composed of two theories:
- You do not need to learn everything to become effective (refer to 80/20 Rule)
- You can learn a lot by analyzing others’ code bases (refer to Learning from a Master Data Scientist)
Our quest is to prove these theories.
80/20 Rule
Trying to solve every aspect of a challenge is overwhelming and often not the best use of your time. The 80/20 Rule can often help in these situations. Generally speaking, the 80/20 Rule posits that roughly 20% of activities or tasks produce 80% of the results you want. The challenge of learning the R language falls perfectly into this model. The key is figuring out which areas are the highest value for your time.
How to Learn R From A Master Data Scientist
To make an optimal strategy, we need data on what tools are being used to perform high-end data science. But, where can we get data? From a data scientist that regularly performs high-end data science publicly via the internet. A true master at the dark art of data science!
Why we chose David Robinson (aka DRob):
I met DRob at the EARL Boston conference last November. He had just given a stellar presentation on StackOverflow trends concluding that R was growing rapidly. What stuck out about his presentation was his ability to analyze a question or problem - This is a key skill in DS4B!
Many data scientists such as top Kaggle competitors focus on how to create a high end predictions (which is important) but it’s not representative of most real-world situations. It’s really unique to see a data scientist effectively using problem solving and critical thinking in combination with data science to learn about the problem. DRob did this very well.
I had checked out his blog before, but never picked up on the fact that he’s really doing data science that can be applied to business (although he’s mainly applying to other areas such as sports and politics). DRob has written a number of articles on his blog, Variance Explained. Some of my favorites are his articles on statistics applications in baseball. His approaches are novel leaning on Bayesian A/B testing, hierarchical modeling, mixture models, and many other tools that are very useful in business analysis. Further, he employs problem solving and critical thinking, which are the same skills that are needed in DS4B.
Analysis: Learning R From A Master
If we treat DRob’s code on his Variance Explained blog as a text analysis, we can find the most frequently used packages and functions that cover the majority of code he produces. We can then use an 80/20 approach to determine which functions and packages are most used and therefore most important to master. We’ll split this analysis into two parts:
Libraries
If you wish to follow along, please load the following libraries.
library(tidyverse)
library(tidyquant)
library(tibbletime)
library(rvest)
library(broom)
Part 1: Web Scraping the Variance Explained Blog
CAUTION: Technical details ahead. Those new to R may wish to skip this section and get right to the results.
This part of the analysis is a how-to in web scraping. We expose the process to collect the data, which use the rvest package and a number of custom functions to parse the text. We split this part into two steps:
Step 1: Setup Code Parsing and Utility Functions
This is a text analysis. As such, we are going to need to parse some text to extract function names, to determine which packages functions belong to, and to analyze the text with counts and percents. To do so, we create a few helper functions:
Count To Percent
Function: Utility function to quickly convert counts to percentages. Works well with dplyr::count().
count_to_pct <- function(data, ..., col = n) {
grouping_vars_expr <- quos(...)
col_expr <- enquo(col)
data %>%
group_by(!!! grouping_vars_expr) %>%
mutate(pct = (!! col_expr) / sum(!! col_expr)) %>%
ungroup()
}
Usage: Use dplyr::count() to retrieve counts by grouping variables. Then use count_to_pct() to quickly get percentages within groups. Exclude groups if overall percentages are desired. Note this example uses the mpg data set from ggplot2 package.
mpg %>%
count(manufacturer) %>%
count_to_pct() %>%
top_n(5) %>%
arrange(desc(n))
## # A tibble: 5 x 3
## manufacturer n pct
## <chr> <int> <dbl>
## 1 dodge 37 0.158
## 2 toyota 34 0.145
## 3 volkswagen 27 0.115
## 4 ford 25 0.107
## 5 chevrolet 19 0.0812
Parse Function Names
Function: Takes in text and returns function names.
parse_function_names <- function(text, stop_words = c("")) {
parser <- function(text, stop_words) {
ret <- text %>%
str_c(collapse = " ") %>%
str_split("\\(") %>%
set_names("text") %>%
as.tibble() %>%
slice(-n()) %>%
mutate(str_split = map(text, str_split, " ")) %>%
select(-text) %>%
unnest() %>%
mutate(function_name = map_chr(str_split, ~ purrr::pluck(last(.x)))) %>%
select(function_name) %>%
separate(function_name, into = c("discard", "function_name"),
sep = "(:::|::|\n)", fill = "left") %>%
select(-discard) %>%
mutate(function_name = str_replace_all(function_name,
pattern = "[^[:alnum:]_\\.]", "")) %>%
filter(!(function_name %in% stop_words))
return(ret)
}
safe_parser <- possibly(parser, otherwise = NA)
safe_parser(text, stop_words)
}
Usage: Parses the function name preceding “(“. Returns a tibble.
test_text <- "my_mean <- mean(1:10) some text base::sum(my_mean) "
parse_function_names(test_text)
## # A tibble: 2 x 1
## function_name
## <chr>
## 1 mean
## 2 sum
Find Functions In Package
Function: Takes in a library or package name and returns all functions in the library or package.
find_functions_in_package <- function(package) {
pkg_text <- paste0("package:", package)
safe_ls <- possibly(ls, otherwise = NA)
package_functions <- safe_ls(pkg_text)
if (is.na(package_functions[[1]])) return(package_functions)
ret <- package_functions %>%
as.tibble() %>%
rename(function_name = value)
return(ret)
}
Usage: Takes in a package that is loaded via library(package_name) (the package must be loaded for this to work properly). Returns a tibble of all functions in a package.
find_functions_in_package("dplyr") %>% glimpse()
## Observations: 237
## Variables: 1
## $ function_name <chr> "%>%", "add_count", "add_count_", "add_row"...
Find Loaded Packages
Function: Detects which packages are loaded in the R system.
find_loaded_packages <- function() {
ret <- search() %>%
list() %>%
set_names("search") %>%
as.tibble() %>%
separate(search, into = c("discard", "keep"), sep = ":", fill = "right") %>%
select(keep) %>%
filter(!is.na(keep)) %>%
rename(package = keep) %>%
arrange(package)
return(ret)
}
Usage: Returns a tibble of loaded packages. Used in conjunction with map_loaded_package_functions() to build a corpus of functions and associated packages, which is needed to determine which package the target function comes from.
find_loaded_packages() %>% glimpse()
## Observations: 28
## Variables: 1
## $ package <chr> "base", "bindrcpp", "broom", "datasets", "dplyr",...
Map Loaded Package Functions
Function: Maps the function names to the respective package.
map_loaded_package_functions <- function(data, col) {
col_expr <- enquo(col)
data %>%
mutate(function_name = map(!! col_expr, find_functions_in_package)) %>%
mutate(is_logical = map_dbl(function_name, is.logical)) %>%
filter(is_logical != 1) %>%
select(-is_logical) %>%
unnest()
}
Usage: Used in conjunction with find_loaded_packages(). Builds a corpus of package and function combinations for every package that is loaded. Returns a tibble of packages and associated functions.
find_loaded_packages() %>%
map_loaded_package_functions(package) %>%
glimpse()
## Observations: 4,518
## Variables: 2
## $ package <chr> "base", "base", "base", "base", "base", "ba...
## $ function_name <chr> "-", "-.Date", "-.POSIXt", "!", "!.hexmode"...
Step 2: Web Scraping Variance Explained
Now that we have the parsing and utility functions setup, we can begin the web scraping process to return the code on the Variance Explained blog. The first action is to setup our process for pulling the functions and packages for a single post. Once that process is defined, we can scale our web scraping to ALL posts!
Web Scrape A Single Blog Post
DRob has a number of posts that include code-throughs (walkthroughs using code). The code is contained within the HTML as a node named <code>. This makes it very easy to extract using the rvest package.
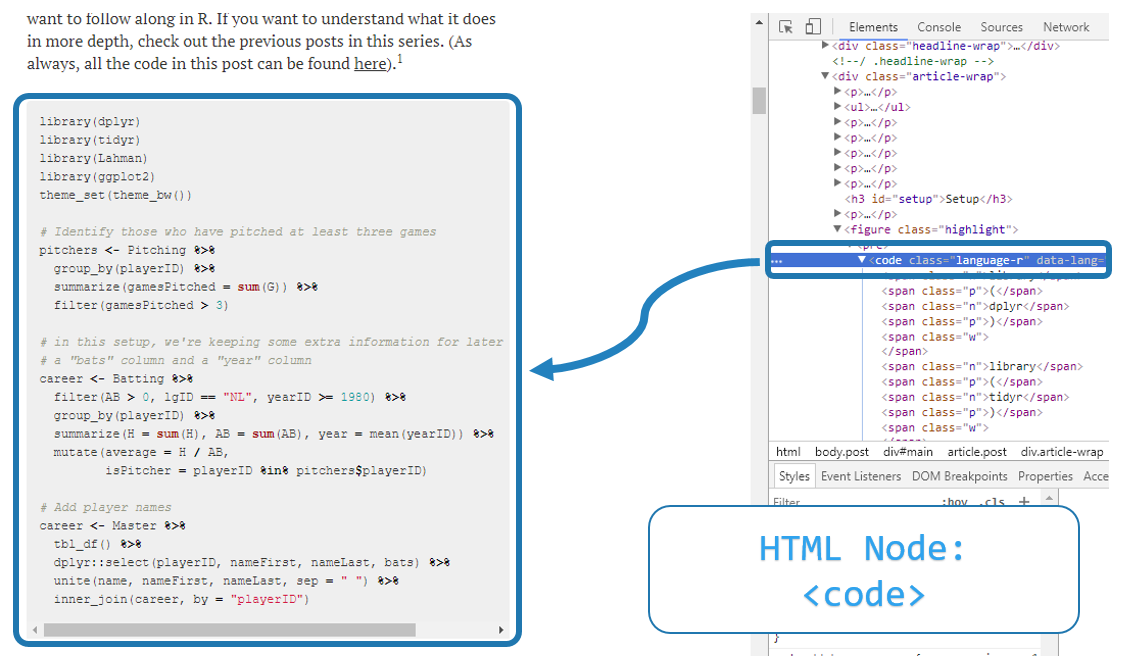
Source: Understanding Mixture Models and Expectation-Maximization (Using Baseball Statistics), Variance Explained
We can get the functions and packages used using the following code. It takes four steps:
- Get a
path for one of the articles. In our case, we chose DRob’s article on analyzing baseball stats with mixture models.
- Create a corpus of all packages that are loaded in our R session. We will use this to determine which package the function that DRob uses comes from.
- Use
rvest functions read_html() to read the HTML from the page. Then collect all nodes containing <code>. Then extract the text within those nodes using html_text().
- Run the text through our custom
parse_function_names() function. This returns parsed function names. We still need the packages, which we can get by using left_join() with our loaded_functions_tbl.
The final output is all of the functions and most of the package names for the functions that are used in this article! We use the glimpse() function to keep the output minimal.
# Assign one of the blog urls to a variable called path
path <- "http://varianceexplained.org/r/mixture-models-baseball/"
# Get the loaded functions (joined in last step)
loaded_functions_tbl <- find_loaded_packages() %>%
map_loaded_package_functions(package)
# Read in HTML as text for all code attributes on the page
html_code_text <- read_html(path) %>%
html_nodes("code") %>%
html_text()
# Parse function names and join with loaded functions
# Note that stats::filter and dplyr::filter conflict
# We replace any missing packages with "Unknown"
mixture_models_code_tbl <- html_code_text %>%
parse_function_names() %>%
left_join(loaded_functions_tbl) %>%
filter(!(function_name == "filter" & !(package == "dplyr"))) %>%
mutate(package = case_when(is.na(package) ~ "Unknown", TRUE ~ package))
mixture_models_code_tbl %>% glimpse()
## Observations: 131
## Variables: 2
## $ function_name <chr> "library", "library", "library", "library",...
## $ package <chr> "base", "base", "base", "base", "ggplot2", ...
From the output, we see that DRob used 131 functions in this particular article.
Next, we can then do a quick analysis to see what functions DRob used most frequently in this article. We can see that dplyr comes up quite frequently. The most popular function used is mutate(), which is used in this article about 11% of the time.
mixture_models_code_tbl %>%
count(package, function_name) %>%
count_to_pct() %>%
arrange(desc(n)) %>%
top_n(5) %>%
knitr::kable()
| package |
function_name |
n |
pct |
| dplyr |
mutate |
14 |
0.1068702 |
| base |
sum |
9 |
0.0687023 |
| dplyr |
group_by |
9 |
0.0687023 |
| dplyr |
filter |
7 |
0.0534351 |
| dplyr |
ungroup |
6 |
0.0458015 |
| tidyr |
crossing |
6 |
0.0458015 |
This is just one sample. We need more data to increase our confidence in which packages and functions are important. Next, let’s scale the web scraping to ALL of DRob’s blog posts on Variance Explained.
Web Scrape All Blog Posts
Scaling to all blog posts is fairly easy with the purrr package. We need to do two things:
-
Web scrape all of the titles, dates, and paths for each of DRob’s articles using rvest.
-
Scale the analysis using purrr in combination with a custom function, build_function_names_tbl_from_url_path(), that we will create.
Web scraping the titles, dates, and paths (href) are again easy with the rvest package. On the Variance Explained Posts page, we can again examine the HTML to find that the structure contains:
- Titles are stored in the
article a nodes as text
- Dates are stored in the
article p.datetime nodes as text
- Paths (href) are stored in the
article a nodes as href attributes
Source: All Posts, Variance Explained
We can extract this information using three web scrapings (one for title, dates, and hrefs), and then binding each together using bind_cols(). We output the first six posts in a table using the head() function.
# Get the path to all of the posts
posts_path <- "http://varianceexplained.org/posts/"
# Extract the post titles
titles_vec <- read_html(posts_path) %>%
html_node("#main") %>%
html_nodes("article") %>%
html_nodes("a") %>%
html_text(trim = TRUE)
# Extract the post dates
dates_vec <- read_html(posts_path) %>%
html_node("#main") %>%
html_nodes("article") %>%
html_nodes("p.dateline") %>%
html_text(trim = TRUE) %>%
mdy()
# Extract the post hrefs
hrefs_vec <- read_html(posts_path) %>%
html_node("#main") %>%
html_nodes("article") %>%
html_nodes("a") %>%
html_attr("href")
# Bind the data together in a tibble
variance_explained_tbl <- bind_cols(
title = titles_vec,
date = dates_vec,
href = hrefs_vec)
# First six posts shown
variance_explained_tbl %>%
head() %>%
knitr::kable()
| title |
date |
href |
| What digits should you bet on in Super Bowl squares? |
2018-02-04 |
http://varianceexplained.org/r/super-bowl-squares/ |
| Exploring handwritten digit classification: a tidy analysis of the MNIST dataset |
2018-01-22 |
http://varianceexplained.org/r/digit-eda/ |
| What’s the difference between data science, machine learning, and artificial intelligence? |
2018-01-09 |
http://varianceexplained.org/r/ds-ml-ai/ |
| Advice to aspiring data scientists: start a blog |
2017-11-14 |
http://varianceexplained.org/r/start-blog/ |
| Announcing “Introduction to the Tidyverse”, my new DataCamp course |
2017-11-09 |
http://varianceexplained.org/r/intro-tidyverse/ |
| Don’t teach students the hard way first |
2017-09-21 |
http://varianceexplained.org/r/teach-hard-way/ |
We now have all 58 of DRob’s posts (title, date, and href) and are now ready to scale! To simplify the process, we’ll create a custom function, build_function_names_tbl_from_url_path(), that combines several rvest operations from the previous section, Web Scrape A Single Blog Post.
build_function_names_tbl_from_url_path <- function(path, loaded_functions_tbl) {
builder <- function(path, loaded_functions_tbl) {
read_html(path) %>%
html_nodes("code") %>%
html_text() %>%
parse_function_names() %>%
left_join(loaded_functions_tbl) %>%
filter(
!(function_name == "filter" & !(package == "dplyr"))
) %>%
mutate(package = ifelse(is.na(package), "Unknown", package))
}
safe_builder <- possibly(builder, otherwise = NA)
safe_builder(path, loaded_functions_tbl)
}
We can test the function to see how it takes a path and a tibble of loaded_functions_tbl and returns the functions and packages.
path <- "http://varianceexplained.org/r/mixture-models-baseball/"
build_function_names_tbl_from_url_path(path, loaded_functions_tbl) %>%
glimpse()
## Observations: 131
## Variables: 2
## $ function_name <chr> "library", "library", "library", "library",...
## $ package <chr> "base", "base", "base", "base", "ggplot2", ...
Next, we can scale this to all posts using map() functions from the purrr package. Several of the posts have no code and therefore return nested NA values. We filter them out by mapping is.logical. We unnest() the function_name column to reveal the nested function names and packages.
variance_explained_tbl <- bind_cols(
title = titles_vec,
date = dates_vec,
href = hrefs_vec) %>%
mutate(
function_name = map(href, build_function_names_tbl_from_url_path, loaded_functions_tbl),
is_logical = map_dbl(function_name, is.logical)
) %>%
filter(is_logical == 0) %>%
select(-is_logical) %>%
unnest()
variance_explained_tbl %>% glimpse()
## Observations: 2,314
## Variables: 5
## $ title <chr> "What digits should you bet on in Super Bow...
## $ date <date> 2018-02-04, 2018-02-04, 2018-02-04, 2018-0...
## $ href <chr> "http://varianceexplained.org/r/super-bowl-...
## $ function_name <chr> "library", "theme_set", "theme_light", "dir...
## $ package <chr> "base", "ggplot2", "ggplot2", "base", "purr...
Awesome - We now have all of the function names and most of the packages that DRob used ALL of his code on Variance Explained! Notice that the sample size has increased to 2314 functions extracted. This is a much larger sample size than before with the single Mixture Models post, which had 131 functions extracted.
Part 2: Learning From DRob’s Code
The question we need to answer is “What Code Does An R Master Use To Perform Data Science?” We can break this down into separate questions of interest:
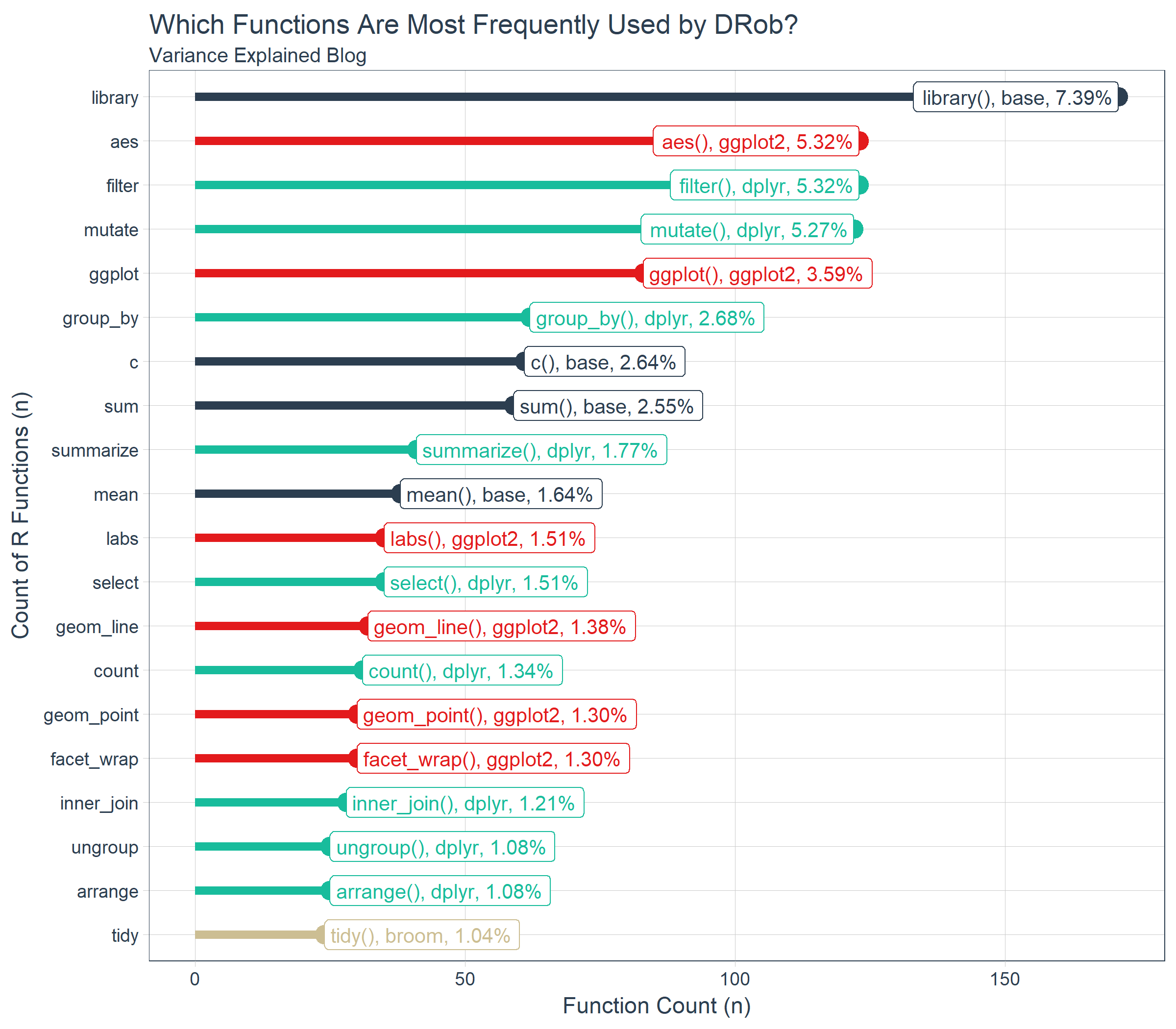
Which Functions Are Most Frequently Used by DRob?
We can answer this question with by counting our package and function name frequencies, sorting, and taking the top 20, which gives us a subset of the most frequently used functions.
ve_functions_top_20_tbl <- variance_explained_tbl %>%
count(package, function_name) %>%
count_to_pct() %>%
arrange(desc(n)) %>%
top_n(20) %>%
mutate(function_name = as_factor(function_name) %>% fct_reorder(n)) %>%
arrange(desc(function_name)) %>%
mutate(package = as_factor(package))
ve_functions_top_20_tbl %>% glimpse()
## Observations: 20
## Variables: 4
## $ package <fct> base, ggplot2, dplyr, dplyr, ggplot2, dplyr...
## $ function_name <fct> library, aes, filter, mutate, ggplot, group...
## $ n <int> 171, 123, 123, 122, 83, 62, 61, 59, 41, 38,...
## $ pct <dbl> 0.07389801, 0.05315471, 0.05315471, 0.05272...
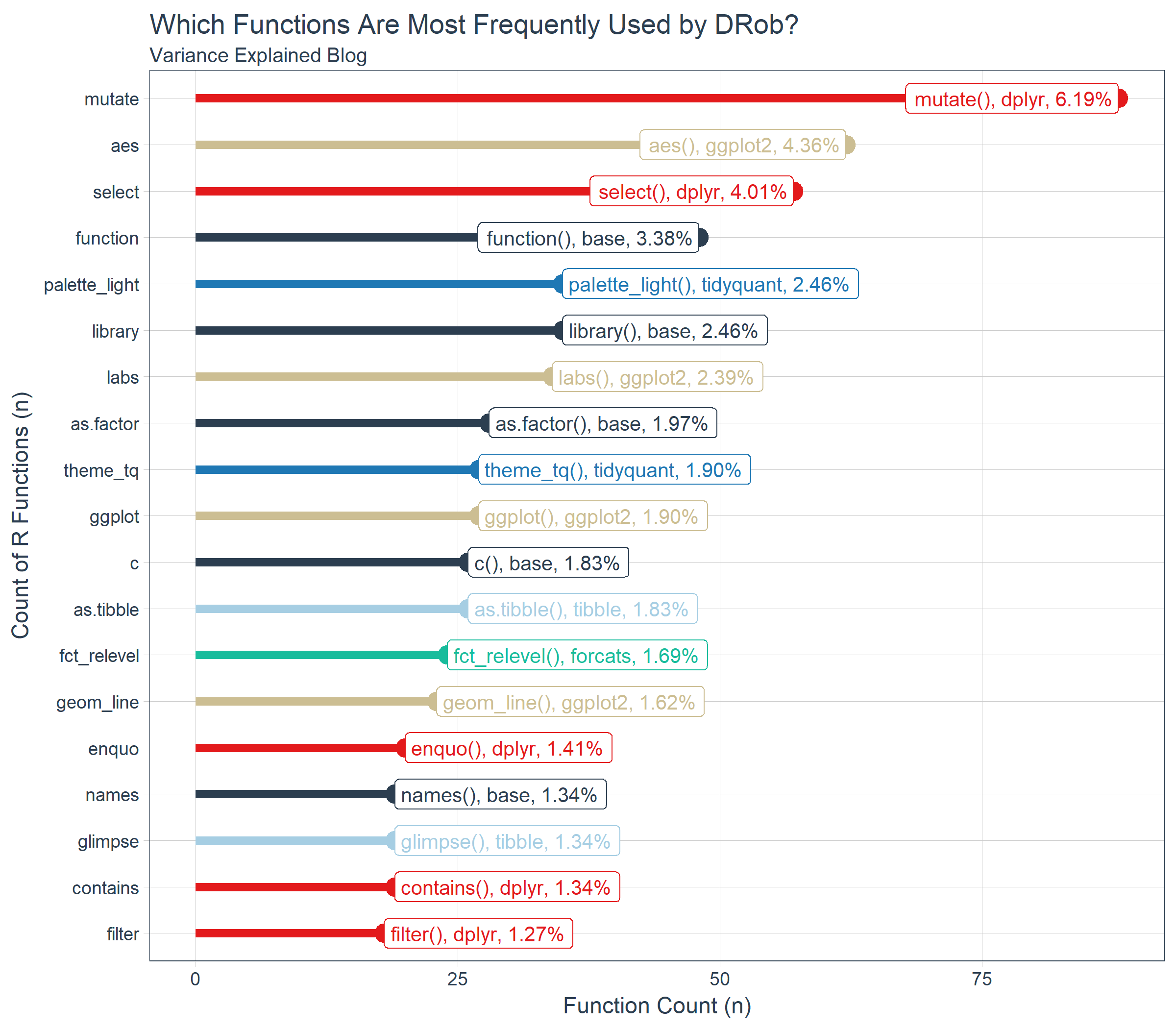
We can visualize this data using ggplot2. We chose a lollipop style chart that extends lengthwise for the top 20, which shows off the number and percentage of total for each of the top 20 functions. We can see that base::library(), ggplot2::aes(), dplyr::filter(), and dplyr::mutate() are very frequently used by DRob. In fact, these four functions comprise 23.3% of his total functions. Unfortunately, aes() can’t be used alone (see below for how it’s used with the ggplot() function). However, with knowledge of library() and the combination of filter() and mutate() from dplyr, a learner can understand 18% of DRob’s code!
ve_functions_top_20_tbl %>%
ggplot(aes(x = n, y = function_name, color = package)) +
geom_segment(aes(xend = 0, yend = function_name), size = 2) +
geom_point(size = 4) +
geom_label(aes(label = paste0(function_name, "(), ", package, ", ", scales::percent(pct))),
hjust = "inward", size = 3.5) +
expand_limits(x = 0) +
labs(
title = "Which Functions Are Most Frequently Used by DRob?",
subtitle = "Variance Explained Blog",
x = "Function Count (n)", y = "Count of R Functions (n)") +
scale_color_tq() +
theme_tq() +
theme(legend.position = "none")
Which Packages Are Most Frequently Used by DRob?
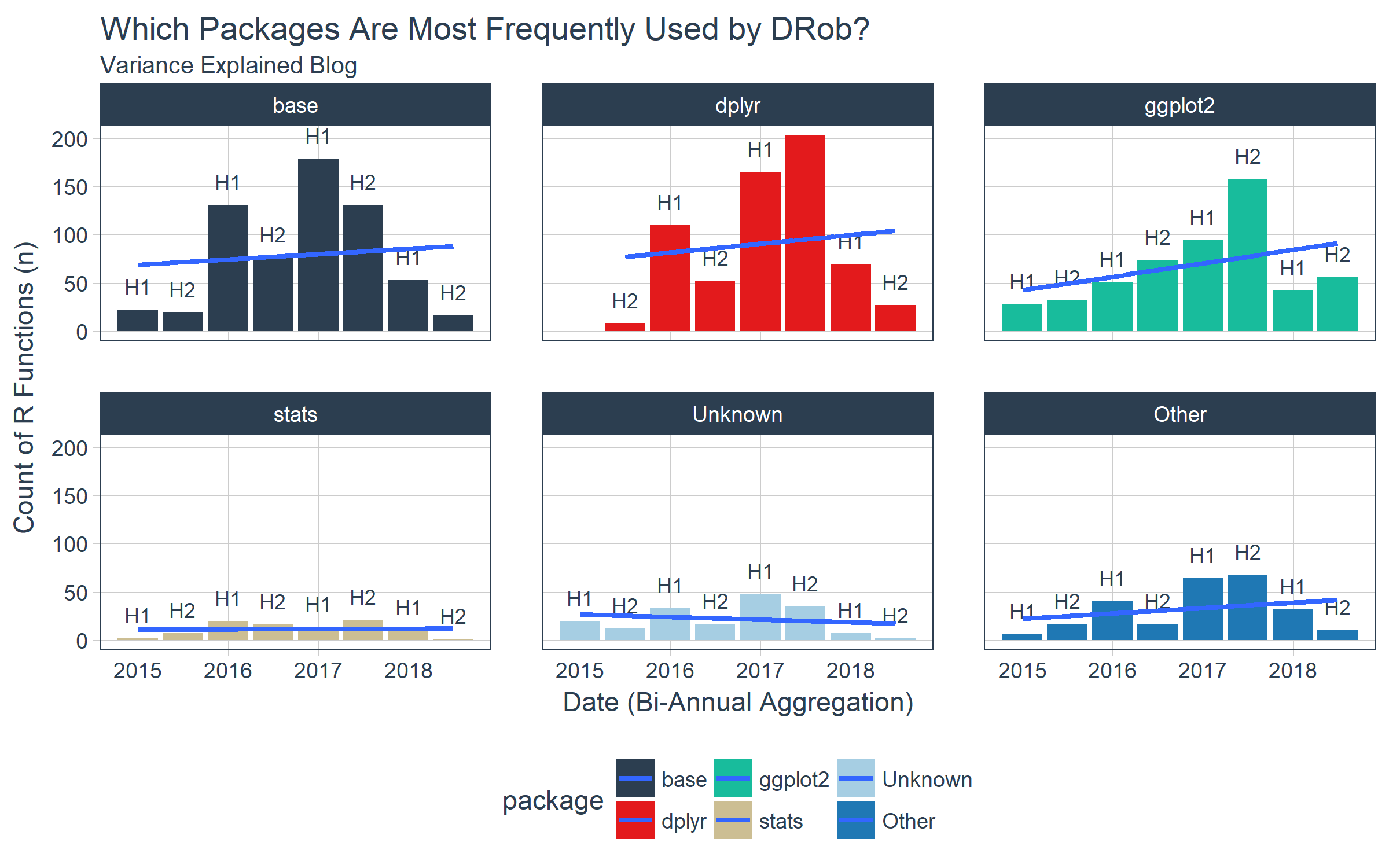
We can answer this question a number of ways, and we elect to make a time-based analysis to expose underlying trends within packages over time. The idea is that some packages may be used more frequently for specific reasons, and we aim to uncover the true trend of the packages which is not constant. We’ll use the tibbletime package to help out with the time-based analysis by aggregating (or grouping) the data by six-month intervals. Note that we lump (using fct_lump()) all packages into six categories based on the top 5 packages and an extra column called “Other”. a label is made by pasting “H” with semester(date) to return the which half of the year the data is aggregated.
ve_package_frequency_tbl <- variance_explained_tbl %>%
select(date, package, function_name) %>%
mutate(package = as.factor(package) %>% fct_lump(n = 5, other_level = "Other")) %>%
arrange(date) %>%
as_tbl_time(index = date) %>%
collapse_by(period = "6 m", clean = TRUE) %>%
count(date, package) %>%
count_to_pct(date) %>%
mutate(biannual = paste0("H", semester(date)))
ve_package_frequency_tbl %>% glimpse()
## Observations: 47
## Variables: 5
## $ date <date> 2015-01-01, 2015-01-01, 2015-01-01, 2015-01-01,...
## $ package <fct> base, ggplot2, stats, Unknown, Other, base, dply...
## $ n <int> 22, 28, 2, 20, 6, 19, 8, 32, 7, 12, 17, 131, 110...
## $ pct <dbl> 0.28205128, 0.35897436, 0.02564103, 0.25641026, ...
## $ biannual <chr> "H1", "H1", "H1", "H1", "H1", "H2", "H2", "H2", ...
Next, we can visualize with ggplot2. The total functions (column n in ve_package_frequency_tbl) used are misleading since in some half years DRob posts less than in others. We can normalize by switching to percentage of total functions by half year.
ve_package_frequency_tbl %>%
ggplot(aes(date, n, fill = package)) +
geom_bar(stat = "identity") +
geom_text(aes(x = date, y = n, label = biannual),
vjust = -1, color = palette_light()[[1]], size = 3) +
geom_smooth(method = "lm", se = FALSE) +
facet_wrap(~ package, ncol = 3) +
scale_fill_tq() +
theme_tq() +
labs(
title = "Which Packages Are Most Frequently Used by DRob?",
subtitle = "Variance Explained Blog",
x = "Date (Bi-Annual Aggregation)", y = "Count of R Functions (n)"
)
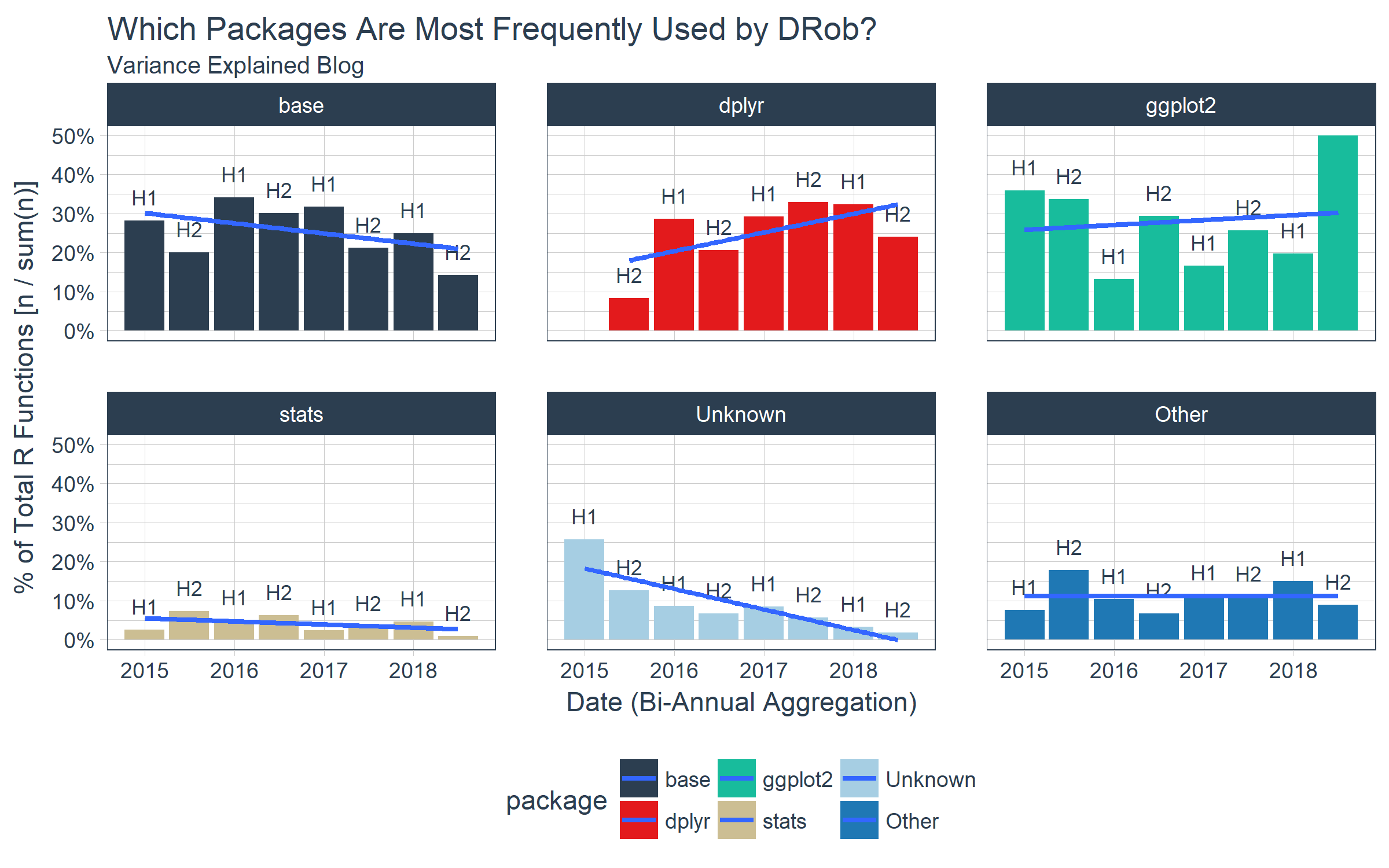
We switch to a percentage of total functions (pct column in ve_package_frequency_tbl) to get a better perspective on what trends are happening within posts over time. We see that DRob is trending in the direction of more dplyr and ggplot2 and using fewer “Unknown” packages, which are packages that I do not have currently loaded on my machine (e.g. not “tidyverse” or “base”). It’s clear that base, dplyr, and ggplot2 are DRob’s toolkits of choice.
ve_package_frequency_tbl %>%
ggplot(aes(date, pct, fill = package)) +
geom_bar(stat = "identity") +
geom_text(aes(x = date, y = pct, label = biannual),
vjust = -1, color = palette_light()[[1]], size = 3) +
geom_smooth(method = "lm", se = FALSE) +
facet_wrap(~ package, ncol = 3) +
scale_y_continuous(labels = scales::percent) +
scale_fill_tq() +
theme_tq() +
labs(
title = "Which Packages Are Most Frequently Used by DRob?",
subtitle = "Variance Explained Blog",
x = "Date (Bi-Annual Aggregation)", y = "% of Total R Functions [n / sum(n)]"
)
Finally, we can get the overall percentage of package usage by uncounting and recounting by package. We add a cumulative percentage column and see that we can almost get to 80% with just three package: dplyr, base, and ggplot2.
ve_package_frequency_tbl %>%
uncount(weights = n) %>%
count(package) %>%
count_to_pct() %>%
arrange(desc(n)) %>%
mutate(pct_cum = cumsum(pct)) %>%
knitr::kable()
| package |
n |
pct |
pct_cum |
| dplyr |
634 |
0.2739844 |
0.2739844 |
| base |
627 |
0.2709594 |
0.5449438 |
| ggplot2 |
535 |
0.2312014 |
0.7761452 |
| Other |
254 |
0.1097666 |
0.8859118 |
| Unknown |
174 |
0.0751945 |
0.9611063 |
| stats |
90 |
0.0388937 |
1.0000000 |
How “Tidy” Is DRob’s Code?
We saw in the package analysis that DRob is using quite a few “tidy” packages. We can extend the analysis to see how frequently he’s using “tidyverse” functions.
The tidyverse is a very popular set of packages that are developed specifically to do data science in an integrated and easy to understand way. Currently, the “tidyverse” consists of the following packages:
tidyverse_packages(include_self = F)
## [1] "broom" "cli" "crayon" "dplyr"
## [5] "dbplyr" "forcats" "ggplot2" "haven"
## [9] "hms" "httr" "jsonlite" "lubridate"
## [13] "magrittr" "modelr" "purrr" "readr"
## [17] "readxl\n(>=" "reprex" "rlang" "rstudioapi"
## [21] "rvest" "stringr" "tibble" "tidyr"
## [25] "xml2"
We can flag functions from the tidyverse package from DRob’s code base using the tidyverse_packages() function. If functions are in a tidyverse package, the are flagged as “Yes” and otherwise “No”.
ve_tidiness_tbl <- variance_explained_tbl %>%
select(date, function_name, package) %>%
mutate(tidy_function = case_when(
package %in% tidyverse_packages() ~ "Yes",
TRUE ~ "No"))
ve_tidiness_tbl %>% glimpse()
## Observations: 2,314
## Variables: 4
## $ date <date> 2018-02-04, 2018-02-04, 2018-02-04, 2018-0...
## $ function_name <chr> "library", "theme_set", "theme_light", "dir...
## $ package <chr> "base", "ggplot2", "ggplot2", "base", "purr...
## $ tidy_function <chr> "No", "Yes", "Yes", "No", "Yes", "Yes", "Ye...
Here’s how easy it is to quickly see how tidy DRob is. About 60% of his functions are “tidyverse” functions.
ve_tidiness_tbl %>%
count(tidy_function) %>%
count_to_pct() %>%
arrange(desc(n)) %>%
knitr::kable()
| tidy_function |
n |
pct |
| Yes |
1373 |
0.5933449 |
| No |
941 |
0.4066551 |
How has DRob’s “tidiness” changed over time? We’ll again call upon tibbletime to help transform the data using collapse_by().
ve_tidiness_over_time_tbl <- ve_tidiness_tbl %>%
select(date, tidy_function, function_name, package) %>%
arrange(date) %>%
as_tbl_time(index = date) %>%
collapse_by(period = "6 m", clean = TRUE) %>%
count(date, tidy_function) %>%
count_to_pct(date) %>%
filter(tidy_function == "Yes") %>%
mutate(biannual = paste0("H", semester(date)))
glimpse(ve_tidiness_over_time_tbl)
## Observations: 8
## Variables: 5
## $ date <date> 2015-01-01, 2015-07-01, 2016-01-01, 2016-0...
## $ tidy_function <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "...
## $ n <int> 29, 53, 189, 133, 310, 427, 140, 92
## $ pct <dbl> 0.3717949, 0.5578947, 0.4921875, 0.5277778,...
## $ biannual <chr> "H1", "H2", "H1", "H2", "H1", "H2", "H1", "H2"
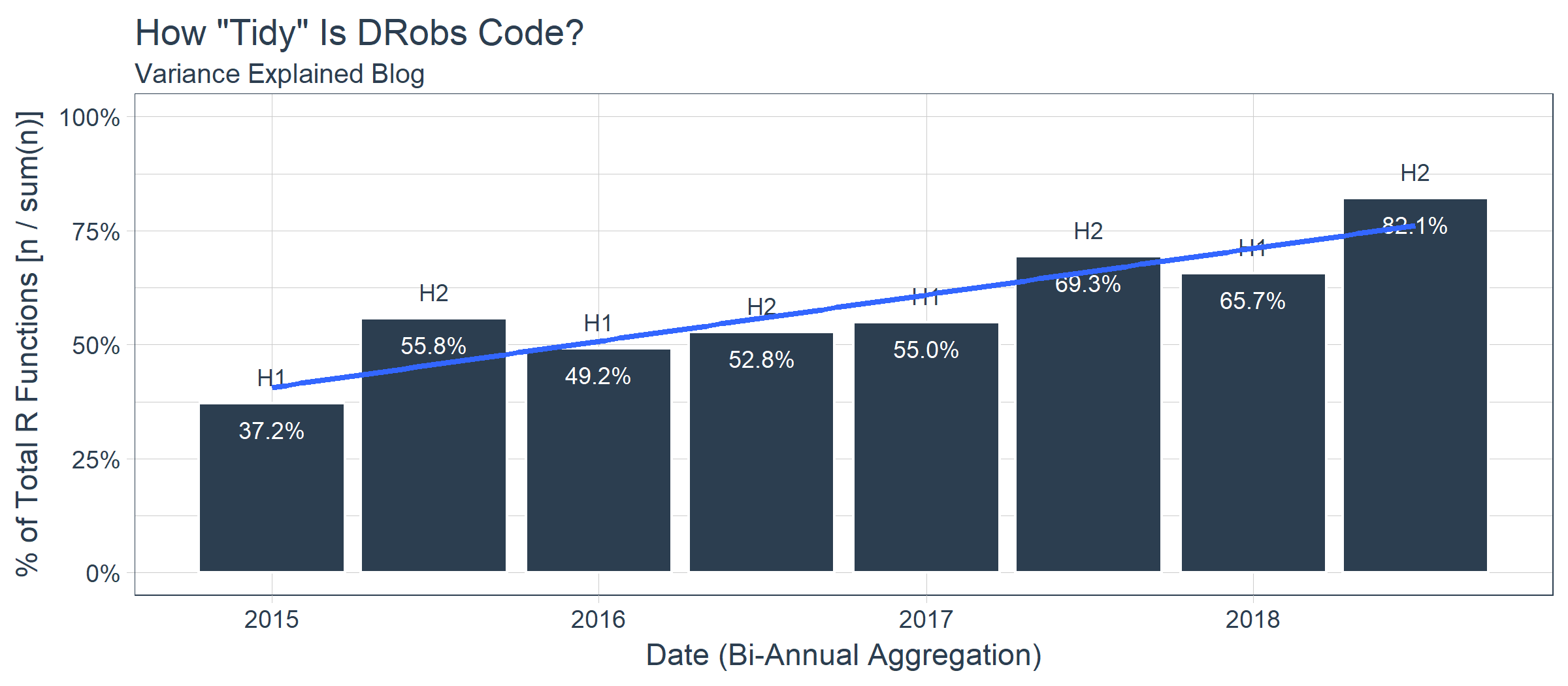
Here’s a fun fact… According to this graph, DRob is over twice as “tidy” now as when he started blogging in 2015. This should tell us that we really need to give the “tidyverse” a shot if we aren’t using it now.
ve_tidiness_over_time_tbl %>%
ggplot(aes(date, pct)) +
geom_bar(stat = "identity", fill = palette_light()[[1]], color = "white") +
geom_text(aes(x = date, y = pct, label = biannual),
vjust = -1, color = palette_light()[[1]], size = 3) +
geom_text(aes(x = date, y = pct, label = scales::percent(pct)),
vjust = 2, color = "white", size = 3) +
geom_smooth(method = "lm", se = FALSE) +
scale_y_continuous(labels = scales::percent) +
scale_fill_tq() +
theme_tq() +
labs(
title = 'How "Tidy" Is DRobs Code?',
subtitle = "Variance Explained Blog",
x = "Date (Bi-Annual Aggregation)", y = "% of Total R Functions [n / sum(n)]"
) +
expand_limits(y = 1)
Which Functions and Packages Should We Focus On For Learning R?
Now the million dollar question: What should we focus on if we are just starting out in R? We’ll use the 80/20 Rule, which boils down to which top functions build 80% of DRob’s code. Ideally this should be around 20% according to the rule. The question is actually really easy to answer using the cumsum() function from base. We can flag any cumulative percentages that are less than or equal to 80% as “high usage”.
ve_eighty_twenty_tbl <- variance_explained_tbl %>%
count(package, function_name) %>%
count_to_pct() %>%
arrange(desc(pct)) %>%
mutate(
pct_cum = cumsum(pct),
high_usage = case_when(
pct_cum <= 0.8 ~ "Yes",
TRUE ~ "No"
))
ve_eighty_twenty_tbl %>% glimpse()
## Observations: 312
## Variables: 6
## $ package <chr> "base", "dplyr", "ggplot2", "dplyr", "ggplo...
## $ function_name <chr> "library", "filter", "aes", "mutate", "ggpl...
## $ n <int> 171, 123, 123, 122, 83, 62, 61, 59, 41, 38,...
## $ pct <dbl> 0.073898012, 0.053154710, 0.053154710, 0.05...
## $ pct_cum <dbl> 0.07389801, 0.12705272, 0.18020743, 0.23292...
## $ high_usage <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "...
Next, we just count our high usage flags and turn the count to percent. We can see that 28.2% of functions create 80% of DRob’s code.
ve_eighty_twenty_tbl %>%
count(high_usage) %>%
count_to_pct(col = nn) %>%
knitr::kable()
| high_usage |
nn |
pct |
| No |
224 |
0.7179487 |
| Yes |
88 |
0.2820513 |
Finally, here are the functions by package that we should focus on if we are just starting out. Keep in mind this is just DRob and we may want to expand to other masters of data science to get an even better picture of the high usage functions.
ve_eighty_twenty_tbl %>%
filter(high_usage == "Yes") %>%
split(.$package)
## $base
## # A tibble: 23 x 6
## package function_name n pct pct_cum high_usage
## <chr> <chr> <int> <dbl> <dbl> <chr>
## 1 base library 171 0.0739 0.0739 Yes
## 2 base c 61 0.0264 0.322 Yes
## 3 base sum 59 0.0255 0.347 Yes
## 4 base mean 38 0.0164 0.382 Yes
## 5 base function 23 0.00994 0.519 Yes
## 6 base list 18 0.00778 0.537 Yes
## 7 base seq 17 0.00735 0.552 Yes
## 8 base set.seed 14 0.00605 0.585 Yes
## 9 base seq_len 12 0.00519 0.619 Yes
## 10 base log10 11 0.00475 0.634 Yes
## 11 base sample 11 0.00475 0.639 Yes
## 12 base cbind 10 0.00432 0.653 Yes
## 13 base log 10 0.00432 0.657 Yes
## 14 base is.na 9 0.00389 0.674 Yes
## 15 base min 9 0.00389 0.678 Yes
## 16 base cumsum 8 0.00346 0.720 Yes
## 17 base paste0 8 0.00346 0.724 Yes
## 18 base matrix 7 0.00303 0.741 Yes
## 19 base colSums 6 0.00259 0.768 Yes
## 20 base max 6 0.00259 0.770 Yes
## 21 base as.Date 5 0.00216 0.788 Yes
## 22 base replicate 5 0.00216 0.790 Yes
## 23 base t 5 0.00216 0.792 Yes
##
## $broom
## # A tibble: 2 x 6
## package function_name n pct pct_cum high_usage
## <chr> <chr> <int> <dbl> <dbl> <chr>
## 1 broom tidy 24 0.0104 0.509 Yes
## 2 broom augment 7 0.00303 0.744 Yes
##
## $dplyr
## # A tibble: 20 x 6
## package function_name n pct pct_cum high_usage
## <chr> <chr> <int> <dbl> <dbl> <chr>
## 1 dplyr filter 123 0.0532 0.127 Yes
## 2 dplyr mutate 122 0.0527 0.233 Yes
## 3 dplyr group_by 62 0.0268 0.296 Yes
## 4 dplyr summarize 41 0.0177 0.365 Yes
## 5 dplyr select 35 0.0151 0.397 Yes
## 6 dplyr count 31 0.0134 0.439 Yes
## 7 dplyr inner_join 28 0.0121 0.477 Yes
## 8 dplyr arrange 25 0.0108 0.488 Yes
## 9 dplyr ungroup 25 0.0108 0.499 Yes
## 10 dplyr n 23 0.00994 0.529 Yes
## 11 dplyr desc 15 0.00648 0.573 Yes
## 12 dplyr tbl_df 14 0.00605 0.591 Yes
## 13 dplyr funs 11 0.00475 0.644 Yes
## 14 dplyr anti_join 9 0.00389 0.682 Yes
## 15 dplyr mutate_each 8 0.00346 0.727 Yes
## 16 dplyr rename 8 0.00346 0.731 Yes
## 17 dplyr top_n 8 0.00346 0.734 Yes
## 18 dplyr data_frame 7 0.00303 0.747 Yes
## 19 dplyr distinct 7 0.00303 0.750 Yes
## 20 dplyr do 6 0.00259 0.773 Yes
##
## $ggplot2
## # A tibble: 23 x 6
## package function_name n pct pct_cum high_usage
## <chr> <chr> <int> <dbl> <dbl> <chr>
## 1 ggplot2 aes 123 0.0532 0.180 Yes
## 2 ggplot2 ggplot 83 0.0359 0.269 Yes
## 3 ggplot2 labs 35 0.0151 0.412 Yes
## 4 ggplot2 geom_line 32 0.0138 0.426 Yes
## 5 ggplot2 facet_wrap 30 0.0130 0.452 Yes
## 6 ggplot2 geom_point 30 0.0130 0.465 Yes
## 7 ggplot2 geom_histogram 14 0.00605 0.597 Yes
## 8 ggplot2 geom_smooth 13 0.00562 0.603 Yes
## 9 ggplot2 scale_y_continuous 13 0.00562 0.608 Yes
## 10 ggplot2 theme 12 0.00519 0.624 Yes
## 11 ggplot2 theme_set 10 0.00432 0.662 Yes
## 12 ggplot2 ylab 10 0.00432 0.666 Yes
## 13 ggplot2 element_text 9 0.00389 0.686 Yes
## 14 ggplot2 geom_bar 9 0.00389 0.690 Yes
## 15 ggplot2 geom_text 9 0.00389 0.694 Yes
## 16 ggplot2 scale_x_log10 9 0.00389 0.697 Yes
## 17 ggplot2 theme_bw 9 0.00389 0.701 Yes
## 18 ggplot2 geom_tile 7 0.00303 0.753 Yes
## 19 ggplot2 geom_abline 6 0.00259 0.775 Yes
## 20 ggplot2 geom_vline 6 0.00259 0.778 Yes
## 21 ggplot2 geom_boxplot 5 0.00216 0.794 Yes
## 22 ggplot2 geom_hline 5 0.00216 0.796 Yes
## 23 ggplot2 theme_void 5 0.00216 0.799 Yes
##
## $lubridate
## # A tibble: 1 x 6
## package function_name n pct pct_cum high_usage
## <chr> <chr> <int> <dbl> <dbl> <chr>
## 1 lubridate round_date 7 0.00303 0.756 Yes
##
## $purrr
## # A tibble: 1 x 6
## package function_name n pct pct_cum high_usage
## <chr> <chr> <int> <dbl> <dbl> <chr>
## 1 purrr map 9 0.00389 0.705 Yes
##
## $stats
## # A tibble: 5 x 6
## package function_name n pct pct_cum high_usage
## <chr> <chr> <int> <dbl> <dbl> <chr>
## 1 stats reorder 16 0.00691 0.566 Yes
## 2 stats qbeta 12 0.00519 0.630 Yes
## 3 stats lm 10 0.00432 0.670 Yes
## 4 stats dbeta 7 0.00303 0.759 Yes
## 5 stats rbeta 6 0.00259 0.780 Yes
##
## $stringr
## # A tibble: 1 x 6
## package function_name n pct pct_cum high_usage
## <chr> <chr> <int> <dbl> <dbl> <chr>
## 1 stringr str_detect 17 0.00735 0.559 Yes
##
## $tibble
## # A tibble: 1 x 6
## package function_name n pct pct_cum high_usage
## <chr> <chr> <int> <dbl> <dbl> <chr>
## 1 tibble data_frame 7 0.00303 0.762 Yes
##
## $tidyr
## # A tibble: 5 x 6
## package function_name n pct pct_cum high_usage
## <chr> <chr> <int> <dbl> <dbl> <chr>
## 1 tidyr separate 18 0.00778 0.545 Yes
## 2 tidyr gather 15 0.00648 0.579 Yes
## 3 tidyr crossing 13 0.00562 0.614 Yes
## 4 tidyr unite 9 0.00389 0.709 Yes
## 5 tidyr unnest 9 0.00389 0.713 Yes
##
## $Unknown
## # A tibble: 5 x 6
## package function_name n pct pct_cum high_usage
## <chr> <chr> <int> <dbl> <dbl> <chr>
## 1 Unknown percent_format 9 0.00389 0.717 Yes
## 2 Unknown ebb_fit_prior 8 0.00346 0.738 Yes
## 3 Unknown unnest_tokens 7 0.00303 0.765 Yes
## 4 Unknown dbetabinom.ab 6 0.00259 0.783 Yes
## 5 Unknown mcbind 6 0.00259 0.786 Yes
##
## $utils
## # A tibble: 1 x 6
## package function_name n pct pct_cum high_usage
## <chr> <chr> <int> <dbl> <dbl> <chr>
## 1 utils head 11 0.00475 0.649 Yes
Takeaways From DRob’s Code
-
DRob is using quite a bit of base, dplyr, and ggplot2 code. In fact, these three libraries account for 77.6% of his code on Variance Explained.
-
DRob’s code is getting… tidier! DRob is using approximately 80% tidyverse code in the most recent half-year of blogging. This trend is increasing, although it will eventually top out. This compares to around 37% tidy code when he began blogging in 2015.
-
If DRob is getting tidier, which area is getting impacted the most? It’s the packages I’ve categorized as “Unknown”. These are non-tidyverse or pre-loaded packages. In other words, these are uncommonly used packages that may serve a specialized need. I do not currently have these loaded, which is why they are considered “Unknown”. It’s worth mentioning that base and stats libraries are declining slightly, but not to the extent that specialized packages are declining. The bottom line - DRob is using less specialized packages and more tidyverse.
Analysis Risks
One point I have not discussed is that DRob is just one really good data scientist. His code is clearly representative of the tidyverse-style, which resonates with many future data scientists coming into the industry. If one wishes to emulate DRob, this is probably a good analysis to take and run with. However, it may make sense to also view other “masters” that exist as part of a future endeavor.
Another point is that we got 2,314 functions out of 58 posts. While this is by no means a small sample, we certainly may wish to increase the sample size to get more confidence in the most high usage functions. Personally, I’d like to see a 100X ratio between top functions and total observations, meaning the top 100 functions would be from at a minimum 10,000 functions. With that said, the analysis was performed accross a large sample of projects (58 posts less those that do not contain code) and multiple years which is another factor that improves confidence.
Bonus: How to Learn R by Analyzing Your Code
We spoke a lot about analyzing DRob’s code, but with a few modifications you can apply this analysis to your own code stored in .R or .Rmd files! Here’s how with the fs package.
We’ll begin with a relatively large code base from a project I’m working on, which is a new course called HR 201: Predicting Employee Attrition. It’s part of our brand new Business Science University Virtual Workshop, which will be released soon! This code base (directory containing R code) is not available to you, but you can follow along if you have a code base of .R or .Rmd files stored in a directory of your own. Just change the directory path to your own.
First, load the fs package. This is a great package for working with the file system on you computer.
library(fs)
Next, collect the path for YOUR code base directory. I will use my R Project directory for the HR 201 Course.
dir_path <- "../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/"
Use a function called dir_info() to retrieve the contents of the directory. Add the argument, recursive = TRUE, to collect all the files from the sub-directories. Use head() to return the first six rows only.
dir_info(dir_path, recursive = TRUE) %>%
head() %>%
knitr::kable()
| path |
type |
size |
permissions |
modification_time |
user |
group |
device_id |
hard_links |
special_device_id |
inode |
block_size |
blocks |
flags |
generation |
access_time |
change_time |
birth_time |
| ../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/00_Data |
directory |
0 |
r– |
2018-02-18 08:25:04 |
NA |
NA |
2586258886 |
1 |
0 |
1.322932e+16 |
4096 |
8 |
0 |
0 |
2018-02-18 08:25:04 |
2018-02-18 08:25:04 |
2018-02-02 16:43:35 |
| ../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/00_Data/desktop.ini |
file |
142 |
rw- |
2018-02-02 16:43:49 |
NA |
NA |
2586258886 |
1 |
0 |
2.589570e+16 |
4096 |
0 |
0 |
0 |
2018-02-02 16:43:49 |
2018-02-02 16:43:49 |
2018-02-02 16:43:49 |
| ../../../Business Science/Courses/Teachable/HR201Employee_Turnover_H2O/HR201_Employee_Turnover_Project/00_Data/WA_Fn-UseC-HR-Employee-Attrition.xlsx |
file |
255.7K |
rw- |
2017-11-26 06:37:44 |
NA |
NA |
2586258886 |
1 |
0 |
1.857735e+16 |
4096 |
512 |
0 |
0 |
2018-02-02 16:43:35 |
2018-02-08 15:43:31 |
2018-02-02 16:43:35 |
| ../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/00_Scripts |
directory |
0 |
r– |
2018-02-26 09:28:32 |
NA |
NA |
2586258886 |
1 |
0 |
4.053240e+16 |
4096 |
8 |
0 |
0 |
2018-02-26 09:28:32 |
2018-02-26 09:28:32 |
2018-02-02 16:43:35 |
| ../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/00_Scripts/assess_attrition.R |
file |
4.01K |
rw- |
2018-02-27 21:22:11 |
NA |
NA |
2586258886 |
1 |
0 |
9.007199e+15 |
4096 |
16 |
0 |
0 |
2018-02-27 21:22:11 |
2018-02-27 21:22:24 |
2018-02-05 16:36:02 |
| ../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/00_Scripts/desktop.ini |
file |
142 |
rw- |
2018-02-02 16:43:49 |
NA |
NA |
2586258886 |
1 |
0 |
4.503600e+15 |
4096 |
0 |
0 |
0 |
2018-02-02 16:43:49 |
2018-02-02 16:43:49 |
2018-02-02 16:43:49 |
Now that we see how dir_info() works, we can use one more function called path_file() to retrieve just the file portion of the path. We can then use the file name with str_detect() to detect only files with “.R” or “.Rmd” at the end. We’ll create a tibble of the file names and paths.
rmd_or_r_file_paths_tbl <- dir_info(dir_path, recursive = T) %>%
mutate(file_name = path_file(path)) %>%
select(file_name, path) %>%
filter(str_detect(file_name, "(\\.R|\\.Rmd)$"))
rmd_or_r_file_paths_tbl %>% knitr::kable()
| file_name |
path |
| assess_attrition.R |
../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/00_Scripts/assess_attrition.R |
| make_directory.R |
../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/00_Scripts/make_directory.R |
| mlhelpers.R |
../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/00_Scripts/mlhelpers.R |
| pipeline_for_modeling_attrition.R |
../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/00_Scripts/pipeline_for_modeling_attrition.R |
| business_understanding.R |
../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/01_Business_Understanding/business_understanding.R |
| data_understanding.R |
../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/02_Data_Understanding/data_understanding.R |
| data_preparation_part_1_readable.R |
../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/03_Data_Preparation/data_preparation_part_1_readable.R |
| data_preparation_part_2_machine_learning.R |
../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/03_Data_Preparation/data_preparation_part_2_machine_learning.R |
| modeling_part_1_h2o.R |
../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/04_Modeling/modeling_part_1_h2o.R |
| modeling_part_2_lime.R |
../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/04_Modeling/modeling_part_2_lime.R |
| evaluation_expected_value.R |
../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/05_Evaluation/evaluation_expected_value.R |
Next, we can create a custom function called, build_function_names_tbl_from_file_path(), which is very similar function to the url builder before. The main difference is that the HTML extraction code is replaced with readLines().
build_function_names_tbl_from_file_path <- function(path, loaded_functions_tbl) {
builder <- function(path, loaded_functions_tbl) {
readLines(path) %>%
parse_function_names() %>%
left_join(loaded_functions_tbl) %>%
filter(
!(function_name == "filter" & !(package == "dplyr"))
) %>%
mutate(package = ifelse(is.na(package), "Unknown", package))
}
safe_builder <- possibly(builder, otherwise = NA)
safe_builder(path, loaded_functions_tbl)
}
We can test it with one of the file paths.
file_path_1 <- rmd_or_r_file_paths_tbl$path[[1]]
file_path_1
## [1] "../../../Business Science/Courses/Teachable/HR201_Employee_Turnover_H2O/HR201_Employee_Turnover_Project/00_Scripts/assess_attrition.R"
Let’s see what it returns.
build_function_names_tbl_from_file_path(file_path_1, loaded_functions_tbl) %>%
glimpse()
## Observations: 57
## Variables: 2
## $ function_name <chr> "library", "count", "function", "quos", "en...
## $ package <chr> "base", "dplyr", "base", "dplyr", "dplyr", ...
Great, it works identically to the web scraping version but with local file paths. We have 57 functions just in the first file.
We can scale it to all code in the code base using the file paths. The process is almost identical to the web scraping process.
local_function_names_tbl <- rmd_or_r_file_paths_tbl %>%
mutate(
function_name = map(path, build_function_names_tbl_from_file_path, loaded_functions_tbl),
is_logical = map_dbl(function_name, is.logical)
) %>%
filter(is_logical != 1) %>%
select(file_name, function_name) %>%
unnest() %>%
left_join(loaded_functions_tbl)
local_function_names_tbl %>% glimpse()
## Observations: 1,422
## Variables: 3
## $ file_name <fs::path> "assess_attrition.R", "assess_attritio...
## $ function_name <chr> "library", "count", "function", "quos", "en...
## $ package <chr> "base", "dplyr", "base", "dplyr", "dplyr", ...
Part 2: Analyzing Your Code
You can run through the same process with your code. Here are my top 20 functions.
local_functions_top_20_tbl <- local_function_names_tbl %>%
count(package, function_name) %>%
count_to_pct() %>%
arrange(desc(n)) %>%
top_n(20) %>%
rowid_to_column(var = "rank")
local_functions_top_20_tbl %>%
ggplot(aes(x = n, y = fct_reorder(function_name, n), color = package)) +
geom_segment(aes(xend = 0, yend = function_name), size = 2) +
geom_point(size = 4) +
geom_label(aes(label = paste0(function_name, "(), ", package, ", ", scales::percent(pct))),
hjust = "inward", size = 3.5) +
expand_limits(x = 0) +
labs(
title = "Which Functions Are Most Frequently Used by DRob?",
subtitle = "Variance Explained Blog",
x = "Function Count (n)", y = "Count of R Functions (n)") +
scale_color_tq() +
theme_tq() +
theme(legend.position = "none")
Similarities
You can assess the similarities and differences between you and DRob. For example, DRob and I both use quite a bit of dplyr for data manipulation and ggplot2 for visualization.
local_functions_top_20_tbl %>%
filter(function_name %in% ve_functions_top_20_tbl$function_name) %>%
knitr::kable()
| rank |
package |
function_name |
n |
pct |
| 1 |
dplyr |
mutate |
88 |
0.0618847 |
| 2 |
ggplot2 |
aes |
62 |
0.0436006 |
| 3 |
dplyr |
select |
57 |
0.0400844 |
| 5 |
base |
library |
35 |
0.0246132 |
| 7 |
ggplot2 |
labs |
34 |
0.0239100 |
| 9 |
ggplot2 |
ggplot |
27 |
0.0189873 |
| 11 |
base |
c |
26 |
0.0182841 |
| 14 |
ggplot2 |
geom_line |
23 |
0.0161744 |
| 20 |
dplyr |
filter |
18 |
0.0126582 |
Differences
I have a few differences related to my coding techniques. I do quite a bit of programming so base::function() is in fourth place and dplyr::enquo() (part of the new tidy eval framework) is in 15th place. I also have tidyquant::palette_light() and tidyquant::theme_tq() related to my preference for tidyquant ggplot2 themes.
local_functions_top_20_tbl %>%
filter(!function_name %in% ve_functions_top_20_tbl$function_name) %>%
knitr::kable()
| rank |
package |
function_name |
n |
pct |
| 4 |
base |
function |
48 |
0.0337553 |
| 6 |
tidyquant |
palette_light |
35 |
0.0246132 |
| 8 |
base |
as.factor |
28 |
0.0196906 |
| 10 |
tidyquant |
theme_tq |
27 |
0.0189873 |
| 12 |
tibble |
as.tibble |
26 |
0.0182841 |
| 13 |
forcats |
fct_relevel |
24 |
0.0168776 |
| 15 |
dplyr |
enquo |
20 |
0.0140647 |
| 16 |
base |
names |
19 |
0.0133615 |
| 17 |
dplyr |
contains |
19 |
0.0133615 |
| 18 |
dplyr |
glimpse |
19 |
0.0133615 |
| 19 |
tibble |
glimpse |
19 |
0.0133615 |
And, we can also see how DRob’s top 20 differs from mine. Most of these functions are ones I use frequently, just not in my top 20. And, this is likely the case for DRob with the dissimilar functions in the table above.
ve_functions_top_20_tbl %>%
rowid_to_column(var = "rank") %>%
filter(!function_name %in% local_functions_top_20_tbl$function_name) %>%
knitr::kable()
| rank |
package |
function_name |
n |
pct |
| 6 |
dplyr |
group_by |
62 |
0.0267934 |
| 8 |
base |
sum |
59 |
0.0254970 |
| 9 |
dplyr |
summarize |
41 |
0.0177182 |
| 10 |
base |
mean |
38 |
0.0164218 |
| 14 |
dplyr |
count |
31 |
0.0133967 |
| 15 |
ggplot2 |
geom_point |
30 |
0.0129646 |
| 16 |
ggplot2 |
facet_wrap |
30 |
0.0129646 |
| 17 |
dplyr |
inner_join |
28 |
0.0121003 |
| 18 |
dplyr |
ungroup |
25 |
0.0108038 |
| 19 |
dplyr |
arrange |
25 |
0.0108038 |
| 20 |
broom |
tidy |
24 |
0.0103717 |
Conclusions
We are half-way on our quest to develop an optimal strategy on how to learn R. We picked a great candidate in DRob to learn from. He’s a tidyverse afficianado, a master data scientist, and he has a large sample of blog posts spanning multiple years to aggregate and analyze.
We learned a bunch of cool things related to our hypothesis. To recap, we hypothesized that (1) you don’t need to learn everything to become proficient at R, and (2) we can develop a strategic plan by learning from a master data scientist. We have not proven the second point yet, but the first we can confirm with confidence given that 88 functions created 80% of the output on DRob’s blog.
In the next post we’ll dive deeper into the list of top functions generated to see if we can develop a program to go from zero experience in R to intermediate status quickly! If our 80/20 theory is right, we should be able to go from zero to intermediate in just a couple weeks by focusing on the most critical functions.
R Resources
About Business Science
Business Science specializes in “ROI-driven data science”. Our focus is helping organizations apply data science to business through projects that generate a financial benefit. Visit Business Science on the web or contact us to learn more!