XGBoost: Tuning the Hyperparameters (My Secret 2 Step Process in R)
Written by Matt Dancho
Hey guys, welcome back to my R-tips newsletter. For years, I was hyperparameter tuning XGBoost models wrong. In 3 minutes, I’ll share one secret that took me 3 years to figure out. When I did, it cut my training time 10X. Let’s dive in.
Table of Contents
Here’s what you’re learning today:
- My big mistake I’ll explain what I was doing wrong for 3 years. And how I fixed it.
- How I Hyperparameter Tune XGBoost Models Now in R. This will blow your mind.
Get the Code (In the R-Tip 076 Folder)
SPECIAL ANNOUNCEMENT: AI for Data Scientists Workshop on December 18th
Inside the workshop I’ll share how I built a SQL-Writing Business Intelligence Agent with Generative AI:
What: GenAI for Data Scientists
When: Wednesday December 18th, 2pm EST
How It Will Help You: Whether you are new to data science or are an expert, Generative AI is changing the game. There’s a ton of hype. But how can Generative AI actually help you become a better data scientist and help you stand out in your career? I’ll show you inside my free Generative AI for Data Scientists workshop.
Price: Does Free sound good?
How To Join: 👉 Register Here
R-Tips Weekly
This article is part of R-Tips Weekly, a weekly video tutorial that shows you step-by-step how to do common R coding tasks. Pretty cool, right?
Here are the links to get set up. 👇
For years I was hyperparameter tuning XGBoost wrong. Here’s how I do it now.
First, here’s a quick review of XGBoost and the algorithm’s hyperparameters.
What is XGBoost?
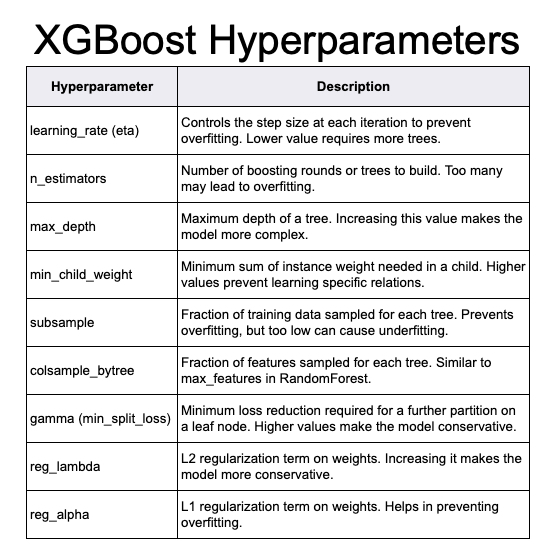
XGBoost (eXtreme Gradient Boosting) is a popular machine learning algorithm, especially for structured (tabular) data. It’s claim to fame is winning tons of Kaggle Competitions. But more importantly, it’s fast, accurate, and easy to use. But it’s also easy to screw it up.
Hyperparameter Tuning
To stabilize your XGBoost models, you need to perform hyperparameter tuning. Otherwise XGBoost can overfit your data causing predictions to be horribly wrong on out of sample data.
My 3-Year “Beginner” Mistake:
XGBoost has tons of parameters. The mistake I was making was treating all of the parameters equally. This caused me hours of tuning my models. And my results weren’t half as good until I started doing this.
How I improved my hyperparameter tuning:
XGBoost has one parameter that rules them all. And after 3 years, I noticed that model stability was 80% driven by this parameter. What was it?
Learning rate. When I figured this out that’s when things started to change. My models got better. My training times were reduced. Win win.
My Simple 2 Step Hyperparameter Tuning Method for XGBoost:
What I was doing wrong was doing random grid search over all of the parameters. This took hours. So I made a key change. I began isolating Learning Rate, tuning it first. This was Step 1. The search space for one parameter is super fast to tune.
What about the other parameters? Once learning rate was tuned, I then opened the search space to more parameters. This is Step 2. The rest of the parameters have maybe 20% contribution to performance, so that means I can reduce the search space dramatically.
The BIG benefit:
Separating tuning into 2 steps cut my training times by a factor of 10X. And my models actually became better. Faster training, better models. Win win.
XGBoost Hyperparameter Tuning (how to do my 2 step process in R)
Now that you know the secret, let’s see how to do it in R.
R Code
Get The Code: You can follow along with the R code in the R-Tips Newsletter. All code is avaliable in R-Tip 076.
Get the Code (In the R-Tip 076 Folder)
Load the Libraries and Data
First, we load the libraries and data. Run this code from the R-Tips Newsletter 076 Folder.
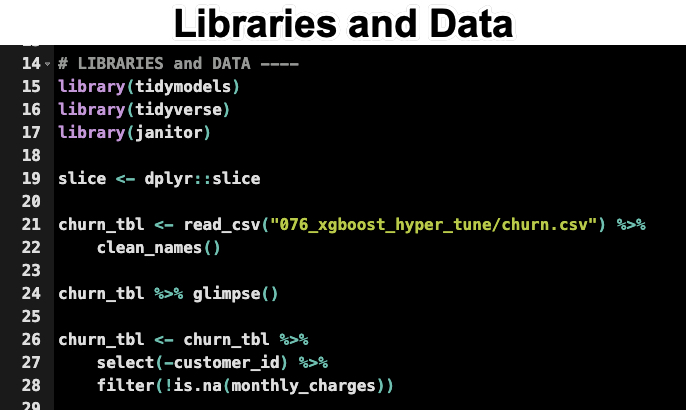
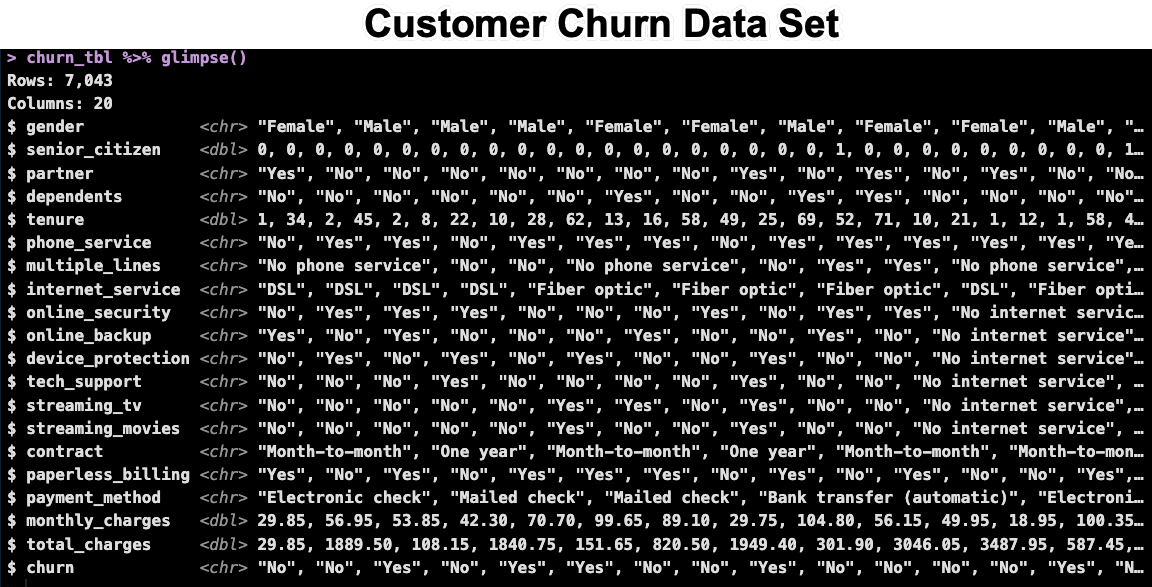
This loads in the customer churn dataset. We’ll use this to demonstrate the 2 step process.
Set up a Model and Preprocessor Specification
This is from tidymodels. We’ll use this to set up our model and preprocessing specification. Run this code from the R-Tips Newsletter 076 Folder.
Important: We only specify the learn_rate = tune() as the only tuning parameter right now. This is Step 1. We’ll add more parameters in Step 2.

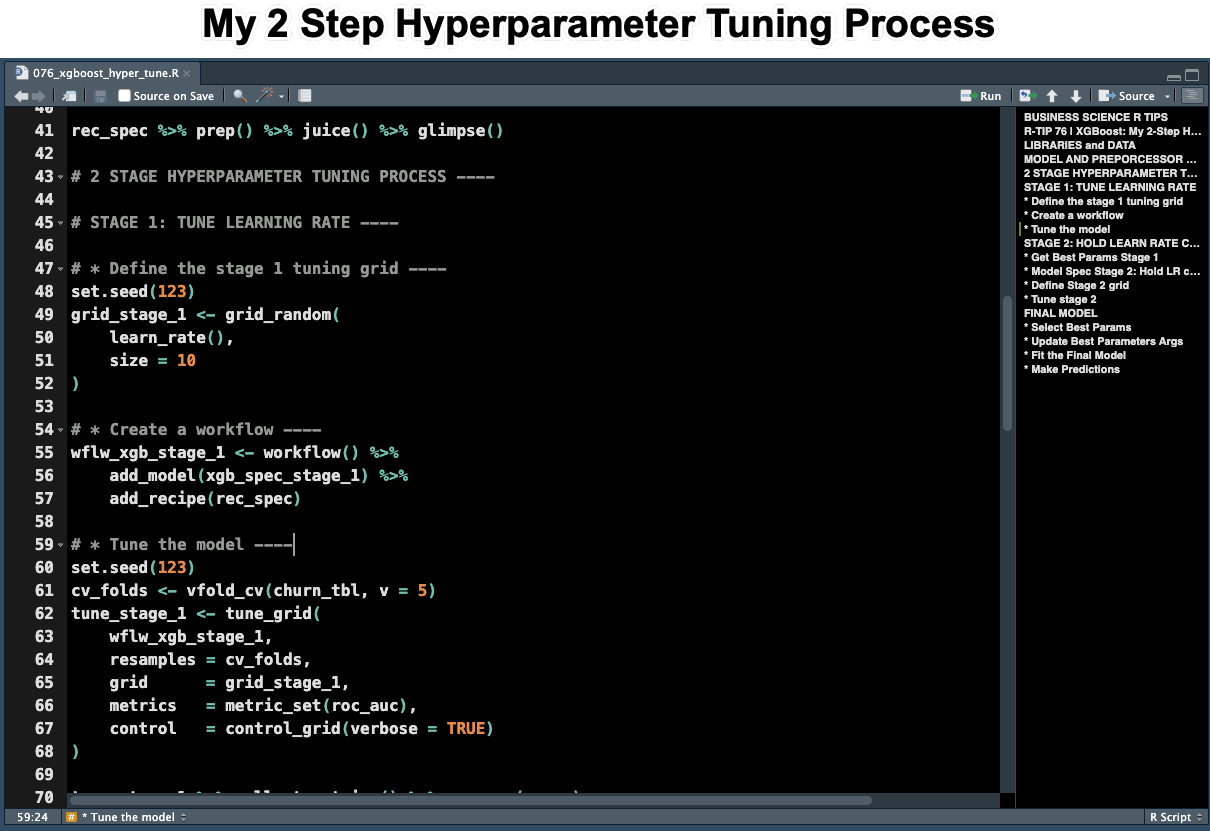
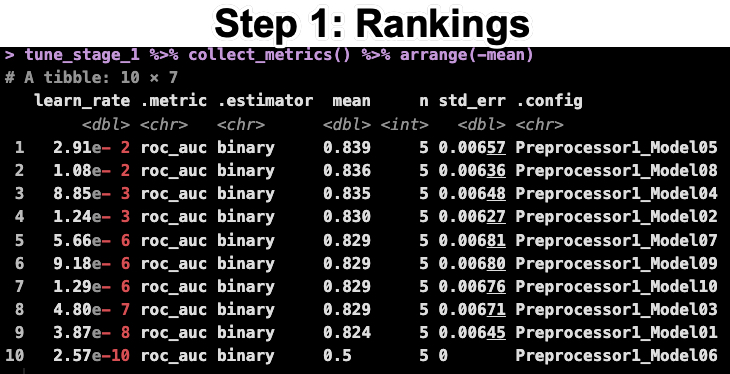
Step 1: Tuning the Learn Rate
For the first stage, we tune the learn rate. This is the most important parameter. Run this code from the R-Tips Newsletter 076 Folder.

In the code above:
- You make a Tuning Grid specifying 10 values for the learn rate.
- You set up the Workflow using the model and preprocessing specification.
- You set up the Resampling Specification using 5-fold cross validation. Then tune the learn rate using the
tune_grid() function and optimizing for the maximum ROC AUC value.
The last line of code returns the ranked results. You can see that the best learn rate is 2.91e-2.
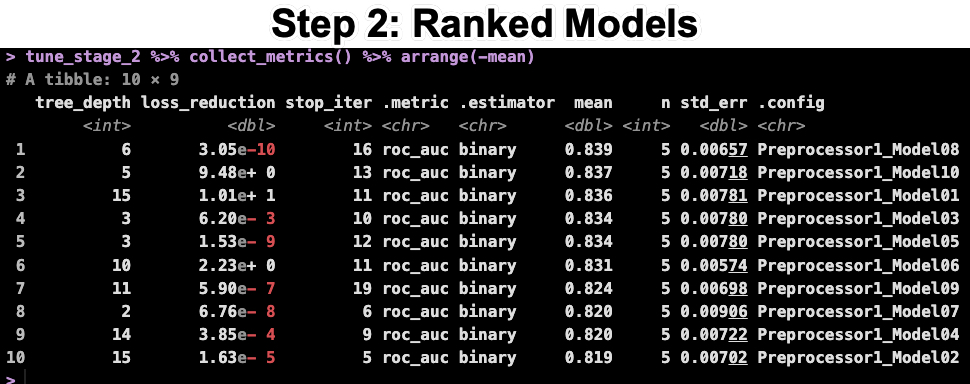
Step 2: Tuning the Rest of the Parameters
Now that we have the learn rate, we can tune the rest of the parameters. Run this code from the R-Tips Newsletter 076 Folder.

In the code above:
- Get the best learn rate from step 1
- Update the model specification with the best learn rate and the other parameters to tune.
- Make a new grid with 10 combinations of the new tuning parameters
- Tune the model using the new grid and the same resampling specification as before.
The last line of code returns the ranked results. You can see that the best AUC is still 0.839, which is what we obtained before.
Bonus Code: Finalize the Model
Now that we have the best parameters, we can finalize the model. Run this code from the R-Tips Newsletter 076 Folder.

Conclusions:
You’ve learned my secret 2 step process for tuning XGBoost models in R. But there’s a lot more to becoming an elite data scientist.
If you are struggling to become a Data Scientist for Business, then please read on…
Need to advance your business data science skills?
I’ve helped 6,107+ students learn data science for business from an elite business consultant’s perspective.
I’ve worked with Fortune 500 companies like S&P Global, Apple, MRM McCann, and more.
And I built a training program that gets my students life-changing data science careers (don’t believe me? see my testimonials here):
6-Figure Data Science Job at CVS Health ($125K)
Senior VP Of Analytics At JP Morgan ($200K)
50%+ Raises & Promotions ($150K)
Lead Data Scientist at Northwestern Mutual ($175K)
2X-ed Salary (From $60K to $120K)
2 Competing ML Job Offers ($150K)
Promotion to Lead Data Scientist ($175K)
Data Scientist Job at Verizon ($125K+)
Data Scientist Job at CitiBank ($100K + Bonus)
Whenever you are ready, here’s the system they are taking:
Here’s the system that has gotten aspiring data scientists, career transitioners, and life long learners data science jobs and promotions…

Join My 5-Course R-Track Program Now!
(And Become The Data Scientist You Were Meant To Be...)
P.S. - Samantha landed her NEW Data Science R Developer job at CVS Health (Fortune 500). This could be you.