Docker for Data Science: An Important Skill for 2021 [Video]
Written by Matt Dancho

Data Science Technology Trends
A year ago I wrote about technologies Data Scientists should focus on based on industry trends. Moving into 2021, these trends remain clear - Organizations want Data Science, Cloud, and Apps. Here’s what’s happening and how Docker plays a part in the essential skills of 2020-2021 and beyond.
Articles in Series
- Part 1 - Five Full-Stack Data Science Technologies
- Part 2 - AWS Cloud
- Part 3 - Docker (You Are Here)
- Part 4 - Git Version Control
- Part 5 - H2O Automated Machine Learning (AutoML)
- Part 6 - R Shiny vs Tableau (3 Business Application Examples)
- [NEW BOOK] - The Shiny Production with AWS Book
Changing Trends in Tech Jobs
Indeed, the popular employment-related search engine, released an article this past Tuesday showing changing trends from 2015 to 2019 in “Technology-Related Job Postings”. We can see a number of changes in key technologies - One that we are particularly interested in is the 4000% increase in Docker.
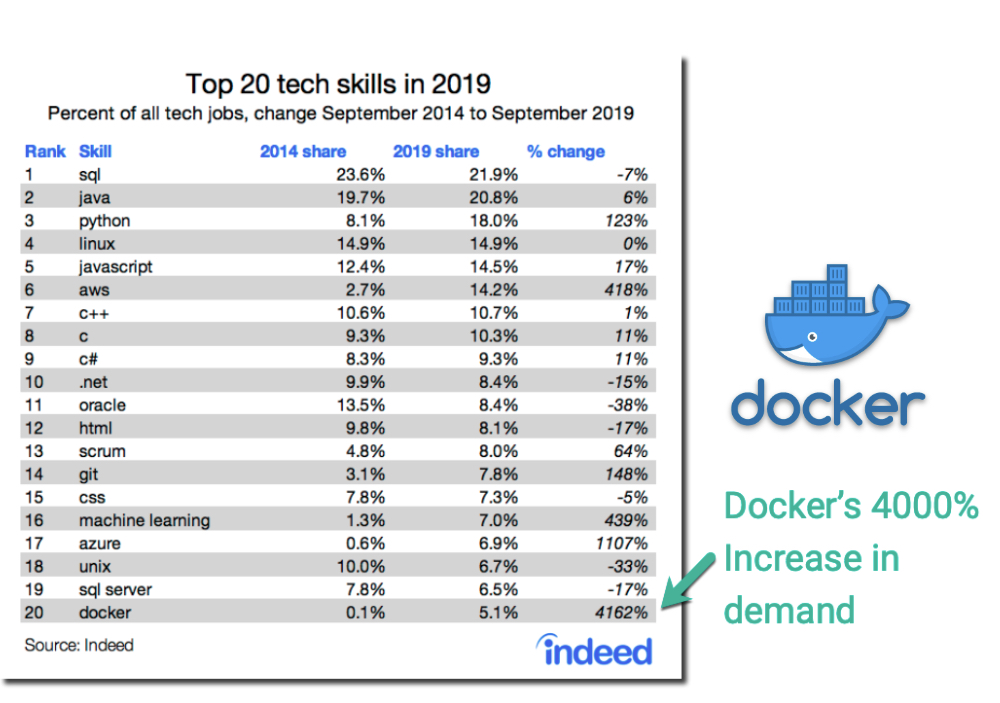
Source: Indeed Hiring Lab.
Drivers of Change
There are 3 Key Drivers of changes in technologies:
-
Rise of Machine Learning (and more generically Data Science) - Unlock Business Insights
-
Businesses Shifting to the Cloud Services versus On-Premise Infrastructure - Massive Cost Savings and Flexibility Increase
-
Businesses Shifting to Distributed Applications versus Ad-Hoc Executive Reports - Democratize Data and Improve Decision-Making within the Organization
If you aren’t gaining experience in data science, cloud, and web applications, you are risking your future.
Machine Learning (Point 1)
Data Science is shifting. We already know the importance of Machine Learning. But a NEW CHANGE is happening. Organizations need distributed data science. This requires a new set of skills - Docker, Git, and Apps. (More on this in a minute).
Cloud Services (Point 2)
Last week, I released “Data Science with AWS”. In the article, I spoke about the shift to Cloud Services and the need to learn AWS (No. 6 on Indeed’s Skill Table, 418% Growth). I’ll reiterate - AWS is my Number 1 skill that you must learn going into 2020.
Azure (No. 17, 1107% Growth) is in the same boat along with Google Cloud Platform for Data Scientists in Digital Marketing.
The nice thing about cloud - If you learn one, then you can quickly switch to the others.
Distributed Web Applications (Point 3)
Businesses now need Apps + Cloud. I discuss this at length in this YouTube video.

Watch on YouTube
Download the Slides
Let’s talk about the BIG CHANGE from the video…
The Big Change: From 2015 to 2020, apps now essential to business strategy
The landscape of Data Science is changing from reporting to application building:
- In 2015 - Businesses need reports to make better decisions
- In 2020 - Businesses need apps to empower better decision making at all levels of the organization
This transition is challenging the Data Scientist to learn new technologies to stay relevant…
In fact, it’s no longer sufficient to just know machine learning. We also need to know how to put machine learning into production as quickly as possible to meet the business needs.
To do so, we need to learn from the Programmers the basics of Software Engineering that can help in our quest to unleash data science at scale and unlock business value.
Learning from programmers
Programmers need applications to run no matter where they are deployed, which is the definition of reproducibility.
The programming community has developed amazing tools that help solve this issue of reproducibility for software applications:
It turns out that Data Scientists can use these tools to build apps that work.
We’ll focus on Docker (and DockerHub), and we’ll make a separate article for Git (and GitHub).
What is Docker?
Let’s look at a (Shiny) application to see what Docker does and how it helps.
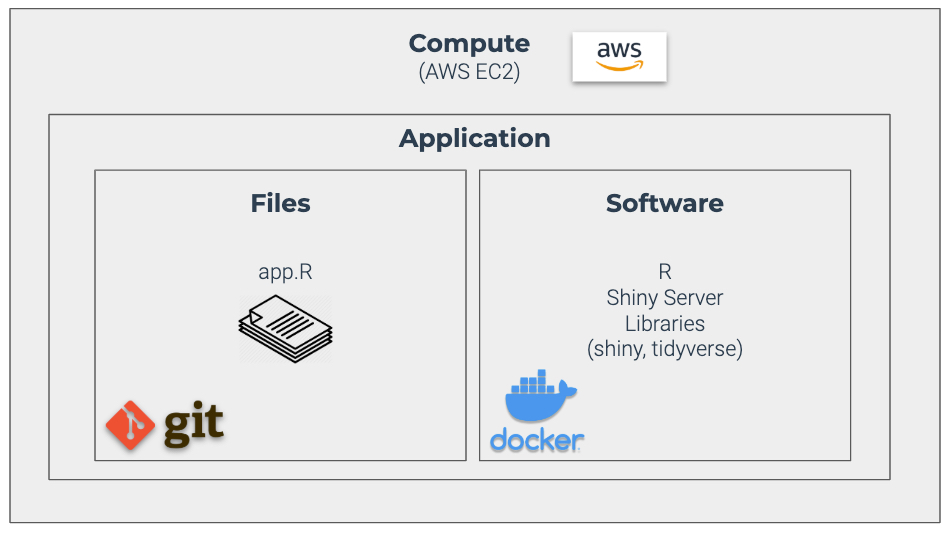
We can see that application consists of 2 things:
-
Files - The set of instructions for the app. For a Shiny App this includes an app.R file that contains layout instructions, server control instructions, database instructions, etc
-
Software - The code external to your files that your application files depend on. For a Shiny App, this is R, Shiny Server, and any libraries your app uses.
Docker "locks down" the Software Environment. This means your software is 100% controlled so that your application uses the same software every time.
Key terminology
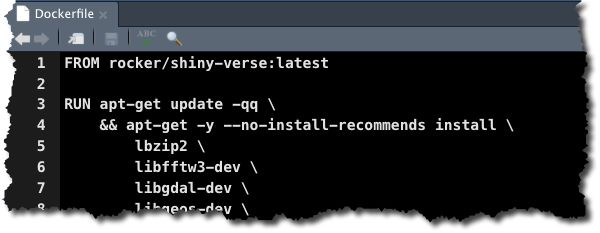
Dockerfile
A Dockerfile contains the set of instructions to create a Docker Container. Here’s an example from my Shiny Developer with AWS Course.
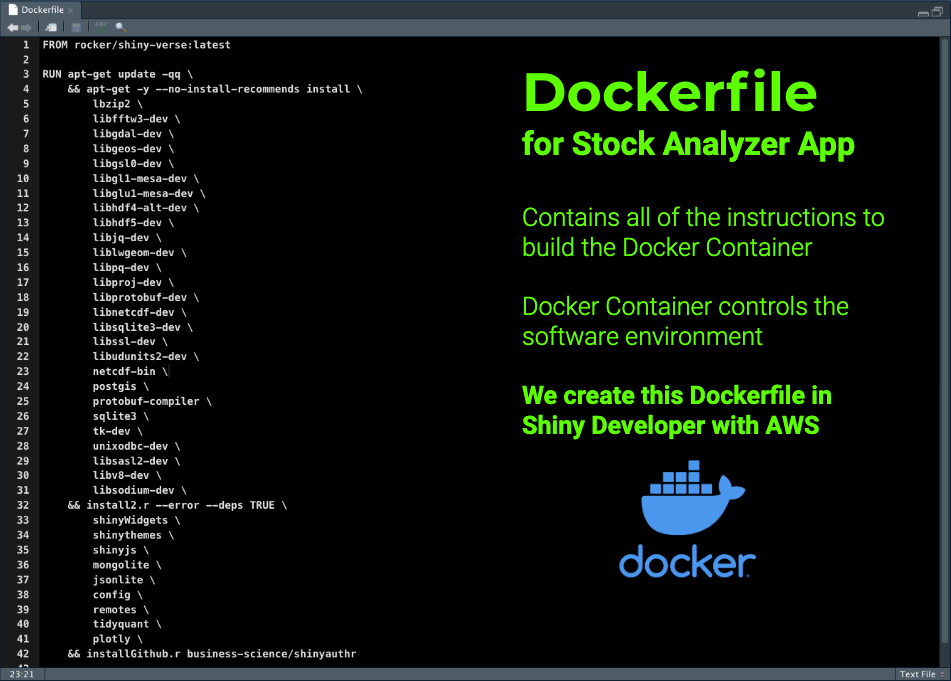
Dockerfile - Used to create a Docker Container
From Shiny Developer with AWS Course
Docker Container
A docker container is a stored version of the software environment built - Think of this as a saved state that can be reproduced on any server (or computer).
Docker Containers are a productivity booster. It usually takes 30 minutes or so to build a software environment in Docker, but once built the container can be stored locally or on DockerHub. The Docker Container can then be installed in minutes on a server or computer.
Without Docker Containers, it would take 30 minutes per server/computer to build an equivalent environment.
Key Point: Docker Containers not only save the state of the software environment making apps reproducible, but they also enhance productivity for data scientists trying to meet the ever-changing business needs.
DockerHub
DockerHub is a repository for Docker Containers that have been previously built.
You can install these containers on computers or use these Containers as the base for new containers.
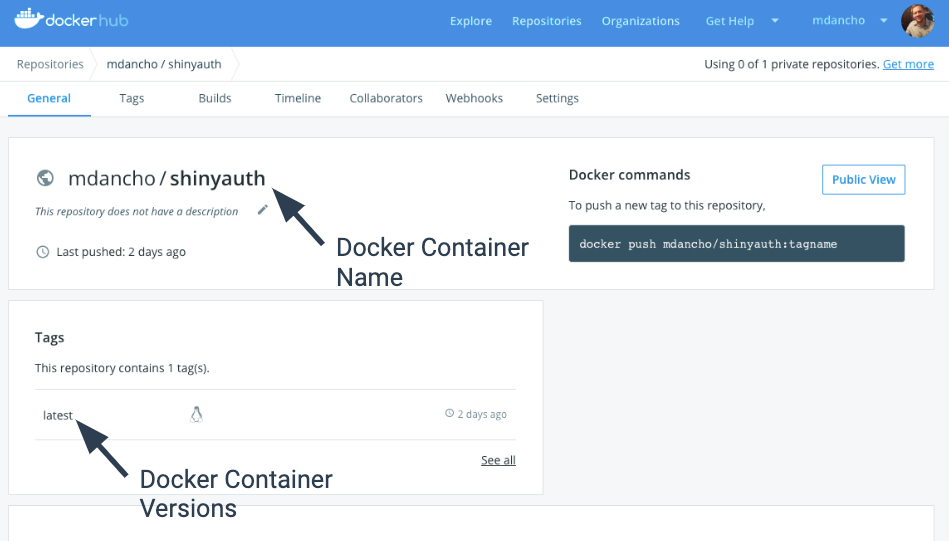
DockerHub - Used to share Docker Containers
From Shiny Developer with AWS Course
Real Docker Use Case Example
In Shiny Developer with AWS, we use the following application architecture that uses AWS EC2 to create an Ubuntu Linux Server that hosts a Shiny App in the cloud called the Stock Analyzer.
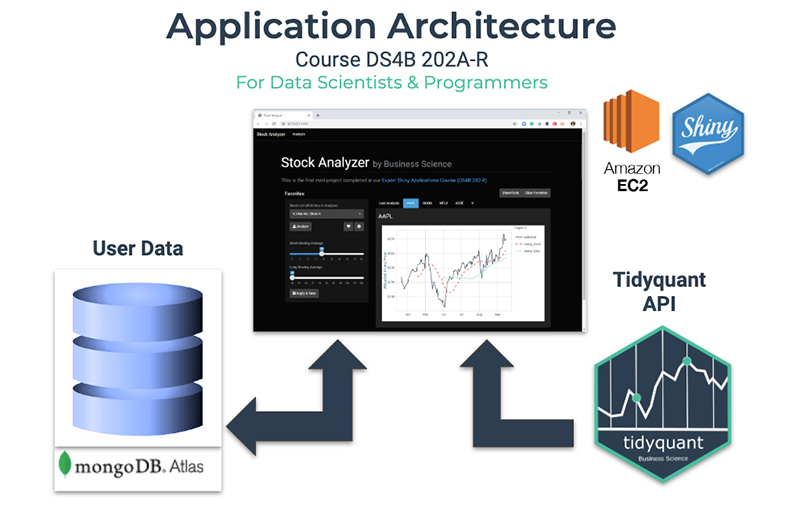
Data Science Web Application Architecture
From Shiny Developer with AWS Course
We use a Dockerfile that is based on rocker/shiny-verse:latest version.
We build on top of the “shiny-verse” container to increase the functionality by adding libraries:
mongolite for connecting to NoSQL databasesshiny libraries like shinyjs, shinywidgets to increase shiny functionalityshinyauthr for authentication
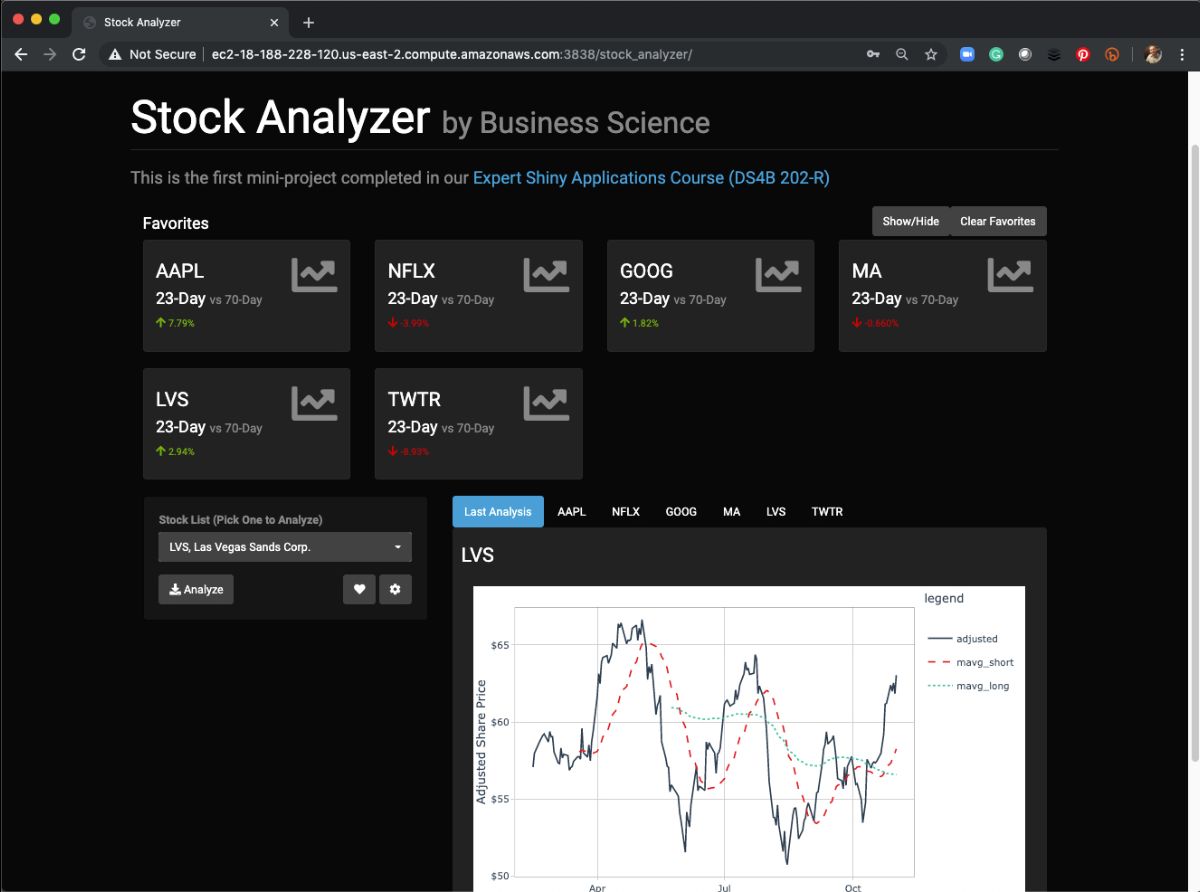
We then deploy our “Stock Analyzer” application using this Docker Container called shinyauth. The application gets hosted on our Amazon AWS EC2 instance.
If you are ready to learn how to build and deploy Shiny Applications in the cloud using AWS, then I recommend my NEW 4-Course R-Track System, which includes:
- Business Analysis with R (Beginner)
- Data Science for Business (Advanced)
- Shiny Web Applications (Intermediate)
- Expert Shiny Developer with AWS (Advanced) - NEW COURSE!!
I look forward to providing you the best data science for business education.
Matt Dancho
Founder, Business Science
Lead Data Science Instructor, Business Science University