Data Science for Business: 3 Reasons Why You Need the Expected Value Framework
Written by Matt Dancho
One of the most difficult and most critical parts of implementing data science in business is quantifying the return-on-investment or ROI. As a data scientist in an organization, it’s of chief importance to show the value that your improvements bring. In this article, we highlight three reasons you need to learn the Expected Value Framework, a framework that connects the machine learning classification model to ROI. Further, we’ll point you to a new video we released on the Expected Value Framework: Modeling Employee Churn With H2O that was recently taught as part of our flagship course: Data Science For Business (DS4B 201). The video serves as an overview of the steps involved in calculating ROI from reducing employee churn with H2O, tying the key H2O functions to the process. Last, we’ll go over some Expected Value Framework FAQ’s that are commonly asked in relation to applying Expected Value to machine learning classification problems in business.
Articles In this Series
Learning Trajectory
We’ll touch on the following Expected Value Framework topics in this article:
Alright, let’s get started!
Get The Best Resources In Data Science. Every Friday!
Sign up for our free "5 Topic Friday" Newsletter. Every week, I'll send you the five coolest topics in data science for business that I've found that week. These could be new R packages, free books, or just some fun to end the week on.
Sign Up For Five-Topic-Friday!
3 Reasons You Need To Learn The Expected Value Framework
Here are the 3 reasons you need to know about Expected Value if you want to tie data science to ROI for a machine learning classifier. We’ll use examples from the DS4B 201 course that are related to employee churn (also called employee turnover or employee attrition).
Reason #1: We Can Avoid The Problem With Max F1
The problem with machine learning classification is that most data scientists use the threshold that maximizes F1 as the classification threshold.
The problem with machine learning classification is that most data scientists use the threshold that maximizes F1 as the classification threshold. Using the threshold that maximizes F1 is the default for most machine learning classification algorithms. For many problems outside of the business domain this is OK. However, for business problems, this is rarely the best choice.
For those that are wondering what the threshold at max F1 is, it’s the threshold that harmonically balances the precision and recall (in other words, it optimally aims to reduce both the false positives and the false negatives finding a threshold that achieves a relative balance). The problem is that, in business, the costs associated with false positives (Type 1 Errors) and false negatives (Type 2 Errors) are rarely equal. In fact, in many cases false negatives are much more costly ( by a factor of 3 to 1 or more!).
Example: Cost of Type 1 And Type 2 Errors For Employee Attrition
As an example, let’s focus on the cost difference between Type 1 (false positives) and Type 2 (false negatives) in an employee attrition problem. Say we are considering a mandatory overtime reduction because saw that employees flagged as working overtime are 5X more likely to quit. We develop a prediction algorithm using H2O Automated Machine Learning and then run our LIME algorithm to develop explanations at the employee level. The LIME results confirm our suspicion. Overtime is a key feature supporting Employee Attrition.

Calculating Expected Attrition Cost From H2O + LIME Results
We develop a proposal to reduce overtime using our H2O classification model, which by default uses the threshold that maximizes F1 (treats Type 1 and Type 2 errors equally). We then begin targeting people for overtime reduction. We end up misclassifying people that leave as stay (Type 2 error) at roughly the same rate as we misclassify people that stay as leave (Type 1 error). The cost of overtime reduction for an employee is estimated at 30% of the lost productivity if the employee quits.
Here lies the problem: The cost of reducing the overtime incorrectly for some one that stays is 30% of missing the opportunity to reduce overtime for an employee incorrectly predicted to stay when they leave. In other words, Type 2 Error is 3X more costly than Type 1 Error, yet we are treating them the same!
“Type 2 Error is 3X more costly than Type 1 Error, yet we are treating them the same!”
Because of this, the optimal threshold for business problems is almost always less than the F1 threshold. This leads us to our second reason you need to know the Expected Value Framework.
Reason #2: We Can Maximize Expected Profit Using Threshold Optimization
When we have a calculation to determine the expected value using business costs, we can perform the calculation iteratively to find the optimal threshold that maximizes the expected profit or savings of the business problem. By iteratively calculating the savings generated at different thresholds, we can see which threshold optimizes the targeting approach.
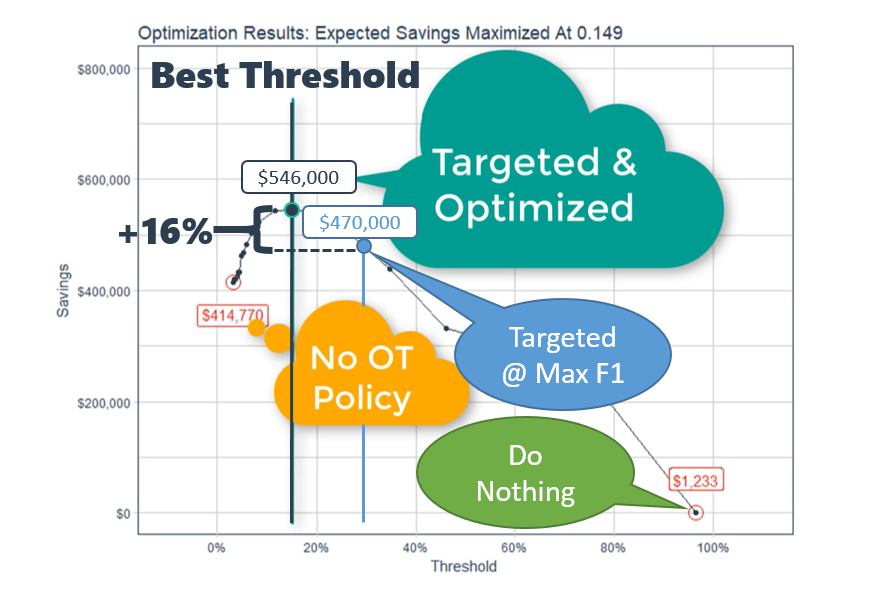
In the example below, we can see in the threshold optimization results that the maximum savings ($546K) occurs at a threshold of 0.149, which is 16% more savings than the savings at threshold at max F1 ($470K). It’s worth mentioning that the threshold that maximizes F1 was 0.280, and that for a test set containing 15% of the total population it cost $76K due to being sub-optimal ($546K - $470K). Extending this inefficiency to the full population (train + test data), this is a missed opportunity of $500K annually!
Threshold Optimization Results Results in 16% Benefit for A Test Set Containing 15% Of Total Population, Extending To Full Set is $500K Savings
The Expected Value Framework enables us to find the optimal threshold that accounts for the business costs, thus weighting Type 2 Errors appropriately. As shown, this can result in huge savings over the F1.
The Expected Value Framework enables us to find the optimal threshold that accounts for the business costs, thus weighting Type 2 Errors appropriately.
Ok, now we know we need to use Expected Value Framework. But it’s worth mentioning that the model we just built using H2O is not reality.
Wait, what?!?!
Here’s what I mean: The model is based on a number of assumptions including the average overtime percentage, the anticipated net profit per employee, and so on. The assumptions are imperfect. This leads us to the third reason you need to learn the Expected Value Framework.
Reason #3: We Can Test Variability In Assumptions And Its Effect On Expected Profit
Let’s face it, we don’t know what the future will bring, and we need to put our assumptions in check. This is exactly what the third benefit enables: Sensitivity Analysis, or testing the effect of model assumptions on expected profit (or savings).
In the human resources example below, we tested for a range of values average overtime percentage and net revenue per employee because our estimates for the future may be off. In the Sensitivity Analysis Results shown below, we can see in the profitability heat map that as long as the average overtime percentage is less than or equal to 25%, implementing a targeted overtime policy saves the organization money.
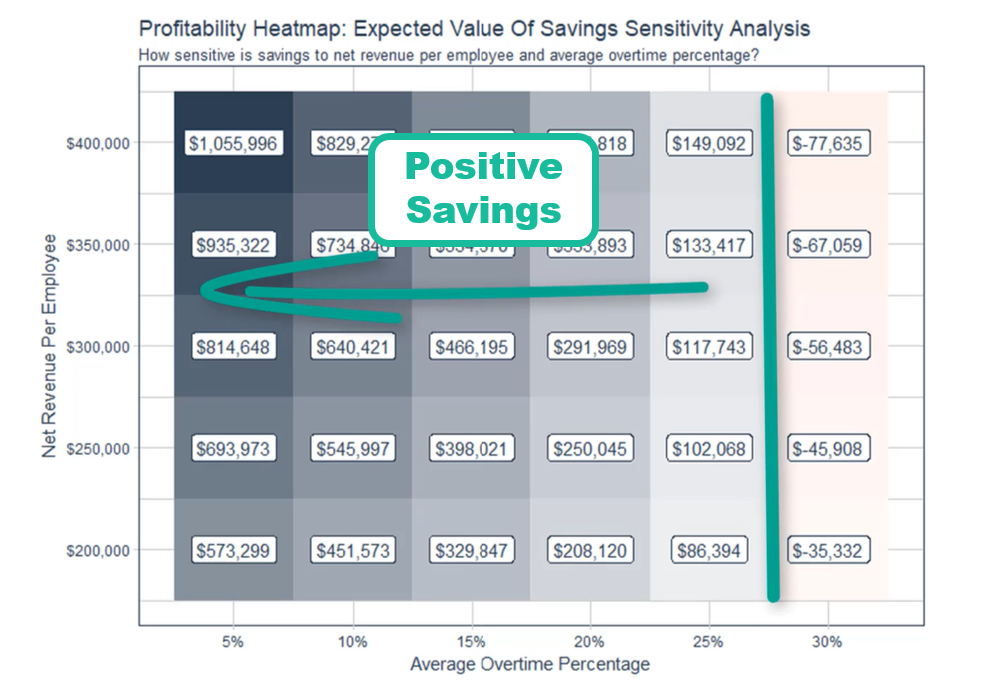
Sensitivity Analysis Results (Profitability Heat Map)
Wow! Not only can we test for the optimal threshold that maximizes the business case, we can use expected value to test for a range of inputs that are variable from year to year and person to person. This is huge for business analysis!
Interested in Learning The Expected Value Framework For Business?
If you're interested in learning how to apply the Expected Value Framework using R Programming, we teach it in Chapters 7 and 8 of Data Science For Business (DS4B 201) as part of our end-to-end Employee Churn business data science project.
Get Started Today!
YouTube Expected Value Framework Overview
Here’s a 20-minute tutorial on the Expected Value Framework that applies to the Data Science For Business (DS4B 201) course where we use H2O Automated Machine Learning to develop high performance models identifying those likely to leave and then the expected value framework to calculate the savings due to various policy changes.
FAQS: Expected Value Framework
The Expected Value Framework can be confusing and there’s a lot to learn. Here are a few of the most frequently asked questions related to applying the EVF to machine learning classification problems in business.
FAQ 1. What Is Expected Value?
Expected value is a way of assigning a value to a decision using the probability of it’s occurrence. We can do this for almost any decision.
Example: Is A Face-To-Face Meeting Warranted?
Suppose you work for a company that makes high tech equipment. Your company has received a quote for a project estimated at $1M in gross profit. The downside is that your competition is preferred and 99% likely to get the award. A face-to-face meeting will cost your organization $5,000 for travel costs, time to develop a professional quotation, and time and materials involved in the sales meeting. Should you take the meeting or no-quote the project?

High Tech Semiconductor Manufacturer
This problem is an expected value problem. We can assign a value to the meeting. We know that the competition is 99% likely to win, but we still have a 1% shot. Is it worth it?
Applying expected value, we multiply the probability of a win, which is 1%, by the profit of the win, which is $1M dollars. This totals $10,000 dollars. This is the expected benefit of the decision excluding any costs. If our total spend for the face-to-face meeting and quotation process is $5000, then it makes sense to take the meeting because it’s lower than $10,000 dollars, or the expected benefit.
FAQ 2. What Is The Expected Value Framework?
The Expected Value Framework is way to apply expected value to a classification model. Essentially it connects a machine learning classification model to ROI for the business. It enables us to combine:
- The threshold,
- Knowledge of costs and benefits, and
- The confusion matrix converted to expected error rates to account for the presence of false positives and false negatives.
We can use this combination to target based on postive class probability (think employee flight risk quantified as a probability) to gain even greater expected savings than an “all-or-none” approach without the framework.
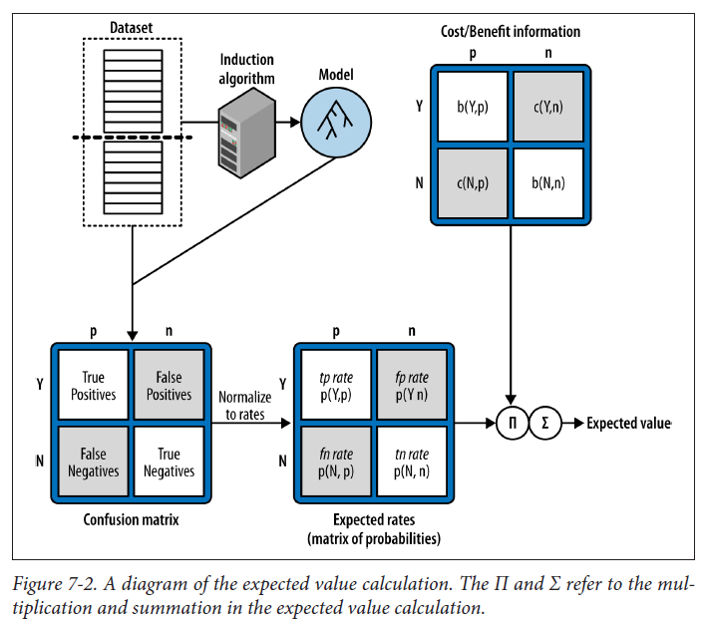
Source: Data Science for Business by Foster Provost & Tom Fawcett
FAQ 3. What Is The Threshold?
It’s the dividing line that we (the data scientist) select between which values for the positive class probability (Yes in the example shown below) we convert to a positive versus a negative. If we choose a threshold (say 0.30), only one observation meets this criteria.
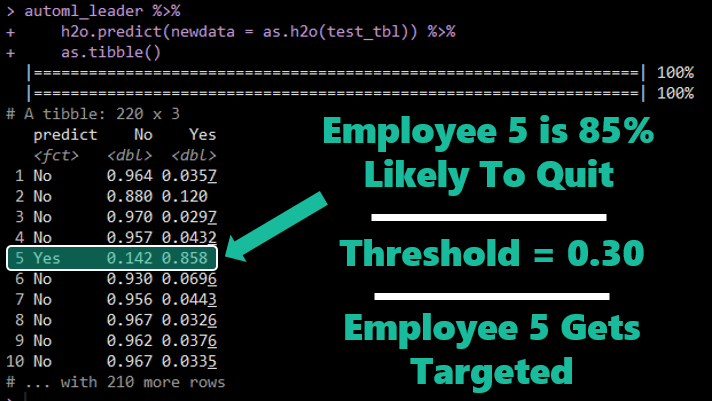
Class Probabilities
FAQ 4: What Are The Expected Rates?
The confusion matrix results can be converted to expected rates through a process called normalization. The “Actual Negative” and “Actual Positive” results are grouped and then converted to probabilities. The expected rates are then probabilities of correctly predicting an Actual value.
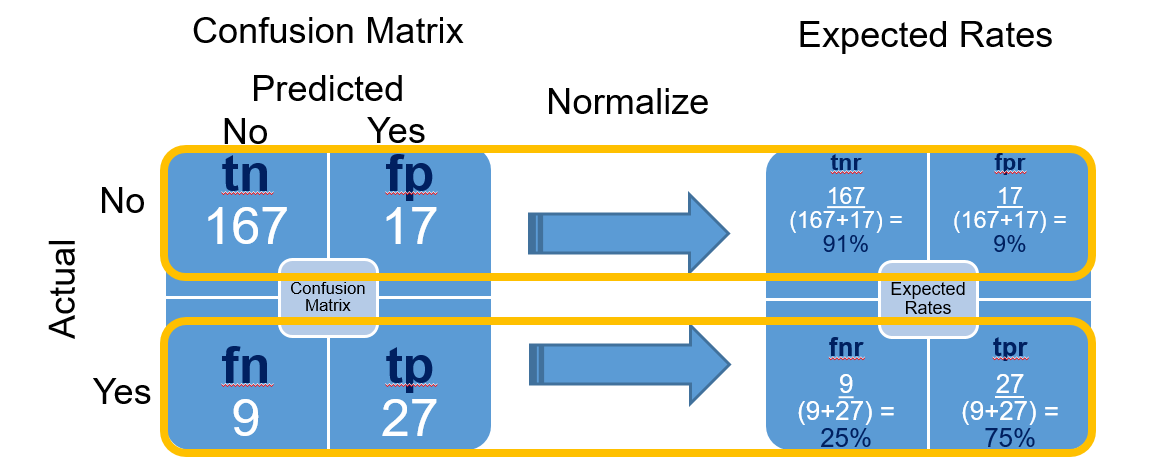
Expected Rates
FAQ 5: What Is The Cost-Benefit Matrix?
The cost / benefit matrix is the final piece needed for the Expected Value Framework. We develop this using our intuition about the problem. This is the most difficult part because we need to apply critical thinking to the business problem and the methodology we intend to use when coding the problem.
For the Employee Churn problem, one way to think of the cost benefit is analyzing two states: an initial state (baseline) and a new state (after a policy change to reduce overtime). We’ll use an employee named Maggie from the DS4B 201 course.
Initial State: Baseline With Allowing Overtime For Maggie
First, we’ll look at the initial state. In this scenario, Maggie’s probability of leaving is 15%, and she has a cost of attrition of $167K. The cost of a policy change is zero because no policy change is implemented in the baseline case. There are four scenarios we need to account for with probabilities of their own:
- The cases of true positives and true negatives when the algorithm predicts correctly
- And the cases of false positives and false negatives when the algorithm predicts incorrectly.
The cost of each scenario is what we are concerned with.

Cost-Benefit Matrix: Initial State (Baseline)
Going through a cost-benefit analysis, we can address each of these costs:
- First is true negatives. If Maggie stays, the cost associated with her staying is nothing.
- Second is true positives. If Maggie leaves, the cost associated with her leaving is $167K, which is her attrition cost.
- Third, is false positives. If Maggie was predicted to leave, but actually stays, the cost associated with this scenario is nothing. We did not implement a policy change for the baseline so we don’t have any costs.
- Fourth, is false negatives. If Maggie leaves but was predicted to stay, we lose her attrition cost.
The expected cost associated with her leaving is $25K
New State: Targeting Maggie For Overtime Reduction
Let’s propose a new state, one that eliminates overtime for Maggie.
In this scenario, Maggie’s probability of leaving drops to 3%. Her cost of attrition is the same, but now we are expecting a higher cost of policy change than we originally anticipated. The cost of the policy change in this scenario is 20% of her attrition cost, meaning she’s working approximately 20% over time. Should we make the policy change?

Like the initial state, there are four scenarios we need to account for with probabilities of their own
- First is true negatives. If Maggie stays, the cost associated with her staying is 20% of her attrition cost, or $33K.
- Second is true positives. If Maggie leaves, the cost associated with her leaving is $167K, which is her attrition cost plus the $33K policy change cost for reducing her overtime. This totals $200K.
- Third, is false positives. If Maggie was predicted to leave, but actually stays, the cost associated with this scenario is $33K because she was targeted.
- Fourth, is false negatives. If Maggie leaves but was predicted to stay, we lose her attrition cost plus the cost of targeting her, which total $200K
The expected cost is $38K for this scenario
Expected Savings (Benefit Of Expected Value Framework)
At an overtime percentage of 20%, the savings is (negative) -$13K versus the baseline. Therefore, we should not reduce Maggie’s over time.
This is the benefit of using Expected Value. Since the model predicts Maggie having only a 15% risk of leaving when working overtime, she is not a high flight risk. We can use the model to target people that are much higher risk to retain.
Next Steps: Take The DS4B 201 Course!
If interested in learning more, definitely check out Data Science For Business (DS4B 201). In 10 weeks, the course covers all of the steps to solve the employee turnover problem with H2O in an integrated fashion.
The students love it. Here’s a comment we just received on Sunday morning from one of our students, Siddhartha Choudhury, Data Architect at Accenture.
“To be honest, this course is the best example of an end to end project I have seen from business understanding to communication.”
Siddhartha Choudhury, Data Architect at Accenture
See for yourself why our students have rated Data Science For Business (DS4B 201) a 9.0 of 10.0 for Course Satisfaction!
Get Started Today!
Learning More
Check out our other articles on Data Science For Business!
Business Science University
Business Science University is a revolutionary new online platform that get’s you results fast.
Why learn from Business Science University? You could spend years trying to learn all of the skills required to confidently apply Data Science For Business (DS4B). Or you can take the first course in our Virtual Workshop, Data Science For Business (DS4B 201). In 10 weeks, you’ll learn:
-
A 100% ROI-driven Methodology - Everything we teach is to maximize ROI.
-
A clear, systematic plan that we’ve successfully used with clients
-
Critical thinking skills necessary to solve problems
-
Advanced technology: _H2O Automated Machine Learning__
-
How to do 95% of the skills you will need to use when wrangling data, investigating data, building high-performance models, explaining the models, evaluating the models, and building tools with the models
You can spend years learning this information or in 10 weeks (one chapter per week pace). Get started today!
Sign Up Now!