Tidy Parallel Processing in R with furrr
Written by Matt Dancho
I’m super excited to introduce furrr, an R package that makes it painless to speed up your R-code. I’ll show a short demo of furrr in this article.
- Parallel processing in the
tidyverse couldn’t be easier with the furrr package.
- If you are familiar with the
purrr::map() function, then you’ll love furrr::future_map().
- We’ll use in this FREE R-Tip training to get a 2.6X speed-up in our code.
R-Tips Weekly
This article is part of R-Tips Weekly, a weekly video tutorial that shows you step-by-step how to do common R coding tasks.
Here are the links to get set up. 👇
Video Tutorial
Follow along with our Full YouTube Video Tutorial.
Learn how to use furrr in our 5-minute YouTube video tutorial.
(Click image to play tutorial)
Parallel Processing [furrr Tutorial]
This tutorial showcases the awesome power of furrr for parallel processing. We’ll get a 2.6X speed boost.

R Package Author Credits
This tutorial wouldn’t be possible without the excellent work of Davis Vaughan, creator of furrr. For more information beyond the tutorial, check out the furrr package here.

Before we get started, get the R Cheat Sheet
furrr is great for parallel processing. But, you’ll need to learn purrr to take full advantage. For these topics, I’ll use the Ultimate R Cheat Sheet to refer to purrr code in my workflow.
Quick Example:
Step 1. Download the Ultimate R Cheat Sheet.
Step 2. Then Click the “CS” hyperlink to “purrr”.
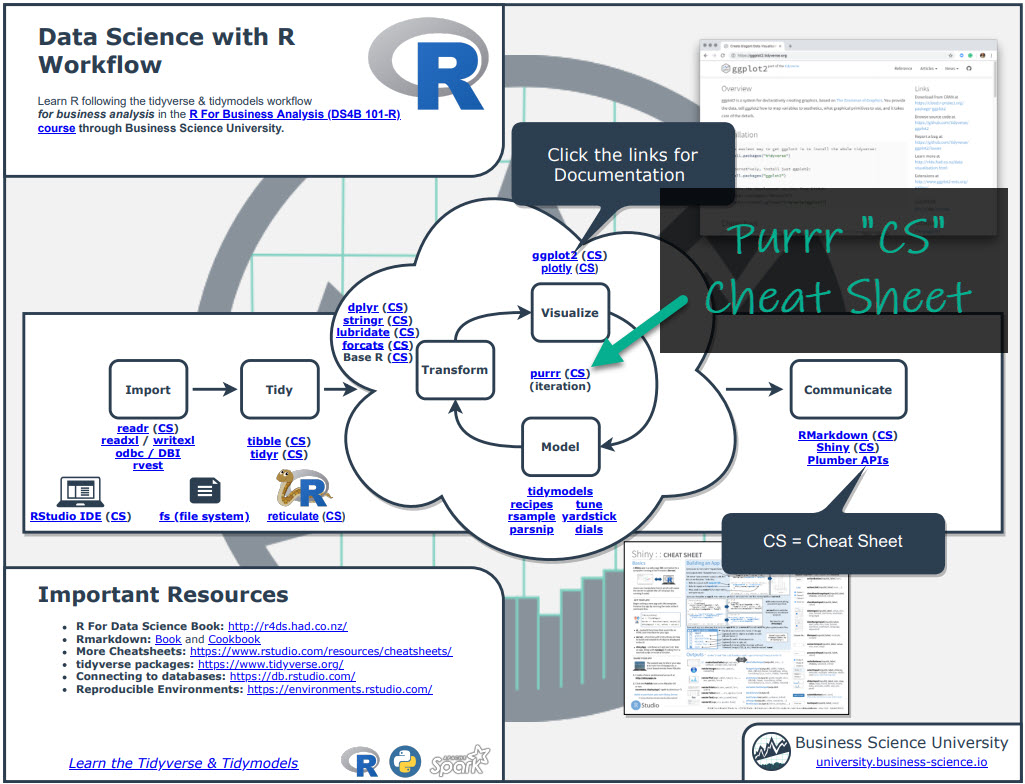
Step 3. Reference the purrr cheat sheet.

Onto the tutorial.
Load the Libraries

Get the code.
Get the Data
We’ll use the walmart_sales_weekly dataset from timetk. We will do a bit of data manipulation using dplyr.
select(): Used to select columnsset_names(): Used to update the column names

Get the code.
The output is a “tidy” dataset in long format where there are:
- 7 ID’s: Each ID represents a walmart store department
- Date and Value: The date and value combination represents the sales in a given week

Get the code.
Purrr: Nest + Mutate + Map
Next, we’ll use a common sequence of operations to iteratively apply an “expensive” modeling function to each ID (Store Deparment) that models the sales data as a function of it’s trend and month of the year.
Pro-Tip 1: Use the R cheat sheet to refer to purrr functions.
Pro-Tip 2: If you need to master R, then I’ll talk about my 5-Course R-Track at the end of the tutorial. It’s a way to up-skill yourself with the data science skills that organizations demand. I teach purrr iteration and nested structures in the R-Track.
Purrr Model Nested Data

Get the code.
We’ll first perform our “expensive modeling” with purrr, which runs each operation sequentially:
nest(): To convert the data to a “Nested” structure, where columns contain our data as a list structure. This generates a column called “data”, with our nested data.mutate() and map(): We use the combination of mutate() to first add a column called “model” and purrr::map() to iteratively apply an expensive function.- “Expensive Function”: The function that we apply is a linear regression using the
lm() function. We use Sys.sleep(1) to simulate an expensive calculation that takes 1-second during each iteration.
Purrr Nested Models and Timing
The output is our nested data now with a column called “model” that contains the 7 Linear Regression Models we just made.

Get the code.
Purrr operations can be expensive. In our case the operation took 7.14 seconds, mainly because we told the “Expensive Function” to sleep for 1-second before making the model.
Furrr: Nest + Mutate + Future Map
Now, we’ll redo the calculation, this time changing purrr::map() out for furrr::future_map(), which will let us run each calculation in parallel for a speed boost.
Furrr Set Plan and Model Nested Data
The furrr code is the same as before using purrr with two important changes:
- Add a
plan(): This allows you to set the number of CPU cores to use when parallel processing. I have 6-cores available on my computer, so I’ll use all 6.
future_map(): We swap purrr::map() out for furrr::future_map(), which let’s the iterative process run in parallel.

Get the code.
Furrr Nested Models and Timing
The output is the same nested data structure as previously. But we got a 2.6X Speed up (2.57-seconds with furrr vs 7.14-seconds with purrr)
Get the code.
Summary
We learned how to parallel process with furrr. But, there’s a lot more to modeling and data science. And, if you are just starting out, then this tutorial was probably difficult. That’s OK because I have a solution.
If you’d like to learn data visualizations, data wrangling, shiny apps, and data science for business with R, then read on. 👇
Need to advance your business data science skills?
I’ve helped 6,107+ students learn data science for business from an elite business consultant’s perspective.
I’ve worked with Fortune 500 companies like S&P Global, Apple, MRM McCann, and more.
And I built a training program that gets my students life-changing data science careers (don’t believe me? see my testimonials here):
6-Figure Data Science Job at CVS Health ($125K)
Senior VP Of Analytics At JP Morgan ($200K)
50%+ Raises & Promotions ($150K)
Lead Data Scientist at Northwestern Mutual ($175K)
2X-ed Salary (From $60K to $120K)
2 Competing ML Job Offers ($150K)
Promotion to Lead Data Scientist ($175K)
Data Scientist Job at Verizon ($125K+)
Data Scientist Job at CitiBank ($100K + Bonus)
Whenever you are ready, here’s the system they are taking:
Here’s the system that has gotten aspiring data scientists, career transitioners, and life long learners data science jobs and promotions…

Join My 5-Course R-Track Program Now!
(And Become The Data Scientist You Were Meant To Be...)
P.S. - Samantha landed her NEW Data Science R Developer job at CVS Health (Fortune 500). This could be you.