Python Integration in RStudio - Data Science IDE Review
Written by Matt Dancho

The two major data science languages, Python and R, have historically taken two separate paths when it comes to where data scientists are doing the coding. The R language has the RStudio IDE, which is a great IDE for data science because of its feature rich setup for efficiently developing analyses. The Python language has the Jupyter Notebook (and more recently Jupyter Lab) that provides a web-based notebook. Most data scientists write their code in separate places - Python is written in Jupyter Notebooks, and R is written in the RStudio IDE. Until now - RStudio is making the case for a powerful mult-language IDE designed for Data Science.
RStudio Preview Version 1.2
The RStudio Version 1.2 Preview Edition comes with support for Python and several other data science languages including SQL and Stan. With this release, RStudio is making a case for a powerful, all-in-one R + Python Data Science IDE.
Let’s take a look at how the Python integration works.
RStudio is making the case for a powerful mult-language IDE designed for Data Science.
Summary of RStudio Python Review
With the rollout of the Python Integration - a major new feature in RStudio - We did a product review of the RStudio IDE from the perspective of data scientist using Python. We created a script file (.py file) and worked interactively with the RStudio IDE’s console, help documentation, and plotting panel performing basic operations that a data scientist will be doing quite frequently.
Here’s what we liked about the new RStudio IDE Python Integration:
-
Sending code to Console is fast. Scripting can now be done efficiently with CTRL + Enter sending code to the Console.
-
Tabbed autocompletion works well. Directory paths, function completion, even function arguments are supported.
-
Help documentation shows up in the Help Window. This is super useful so I don’t have to scroll away from my code to see the help documenation and function examples.
-
Plots show up in the plot window. This is actually a seaborn plot in the RStudio IDE lower right quadrant!
Summary of RStudio IDE Python Integration
Contents
Get More From Business Science
Similar Articles to Check Out Next
Product Review
With the rollout of the Python Integration - a major new feature in RStudio - We did a product review of the RStudio IDE from the perspective of data scientist using Python. We created a script file (.py file) and worked interactively with the RStudio IDE’s console, help documentation, and plotting panel performing basic operations that a data scientist will be doing quite frequently.
Get the Data
The data that we’ll be using to test out the Python functionality comes from Wes McKinney’s (creator of pandas) “Python for Data Analysis” book. Here’s the GitHub Repo where you can download the pydata-book materials.
Get the Data Here
Video Python + RStudio IDE Review
Here’s a quick video review using Python in the RStudio IDE.
Python Integration Review - MovieLens 1M Data Set
With the new Preview Version 1.2 of RStudio IDE, we can work with Python seamlessly. We’ll take a test spin using the MovieLens 1M Data Set. Let’s go.
Importing Libraries
For this walkthrough, we’ll import 4 libraries:
pandas - Data manipulation library for Pythonnumpy - High-performance numerical computing librarymatplotlib - Visualization libraryseaborn - Augments matplotlib
# Python Libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
Bonus No. 1
This brings us to our first bonus - The Python script enables code completion that works with “TAB” command, just like with an R script.
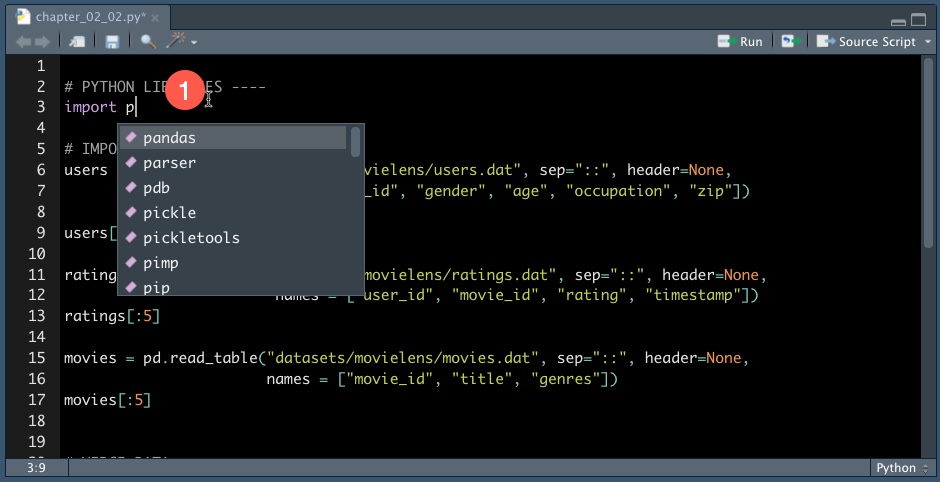
Tabbed Code Completion of Available Libraries
Importing Data
Next, we can read the “MovieLens” data set, which consists of 3 tables:
movies.dat: Movie informationratings.dat: Ratings information for each combination of movie and userusers.dat: User information such as gender, age, occupation, and zipcode
The users.dat file is read using the pd.read_table() function.
users = pd.read_table("datasets/movielens/users.dat", sep="::", header=None,
names=["user_id", "gender", "age", "occupation", "zip"])
print(users[:5])
## user_id gender age occupation zip
## 0 1 F 1 10 48067
## 1 2 M 56 16 70072
## 2 3 M 25 15 55117
## 3 4 M 45 7 02460
## 4 5 M 25 20 55455
We can import the remaining data with the following code.
ratings = pd.read_table("datasets/movielens/ratings.dat", sep="::", header=None,
names = ["user_id", "movie_id", "rating", "timestamp"])
movies = pd.read_table("datasets/movielens/movies.dat", sep="::", header=None,
names = ["movie_id", "title", "genres"])
Bonus No. 2
This brings us to our second bonus - The Python script enables code completion for all functions and arguments. Again, just like good ole RStudio!
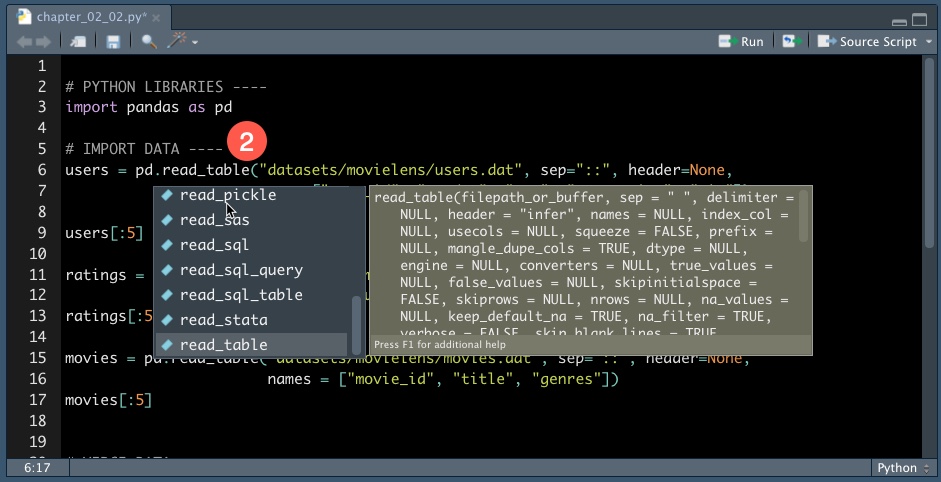
Tabbed Code Completion of Available Functions and Arguments
Merging Data
Next, we’ll merge the data using pd.merge(). We’ll inspect the first 5 lines and the shape of the data.
data = pd.merge(pd.merge(ratings, users), movies)
print(data[:5])
## user_id movie_id ... title genres
## 0 1 1193 ... One Flew Over the Cuckoo's Nest (1975) Drama
## 1 2 1193 ... One Flew Over the Cuckoo's Nest (1975) Drama
## 2 12 1193 ... One Flew Over the Cuckoo's Nest (1975) Drama
## 3 15 1193 ... One Flew Over the Cuckoo's Nest (1975) Drama
## 4 17 1193 ... One Flew Over the Cuckoo's Nest (1975) Drama
##
## [5 rows x 10 columns]
print(data.shape)
## (1000209, 10)
Pivot Table
With the data merged, we can begin to do some analysis. We’ll check out the pd.pivot_table() function.
mean_ratings = data.pivot_table(values="rating", index="title", columns="gender", aggfunc="mean")
print(mean_ratings[:5])
## gender F M
## title
## $1,000,000 Duck (1971) 3.375000 2.761905
## 'Night Mother (1986) 3.388889 3.352941
## 'Til There Was You (1997) 2.675676 2.733333
## 'burbs, The (1989) 2.793478 2.962085
## ...And Justice for All (1979) 3.828571 3.689024
Bonus No. 3
Our third bonus is the help documentation, which shows up right where it should - in the Help Window.
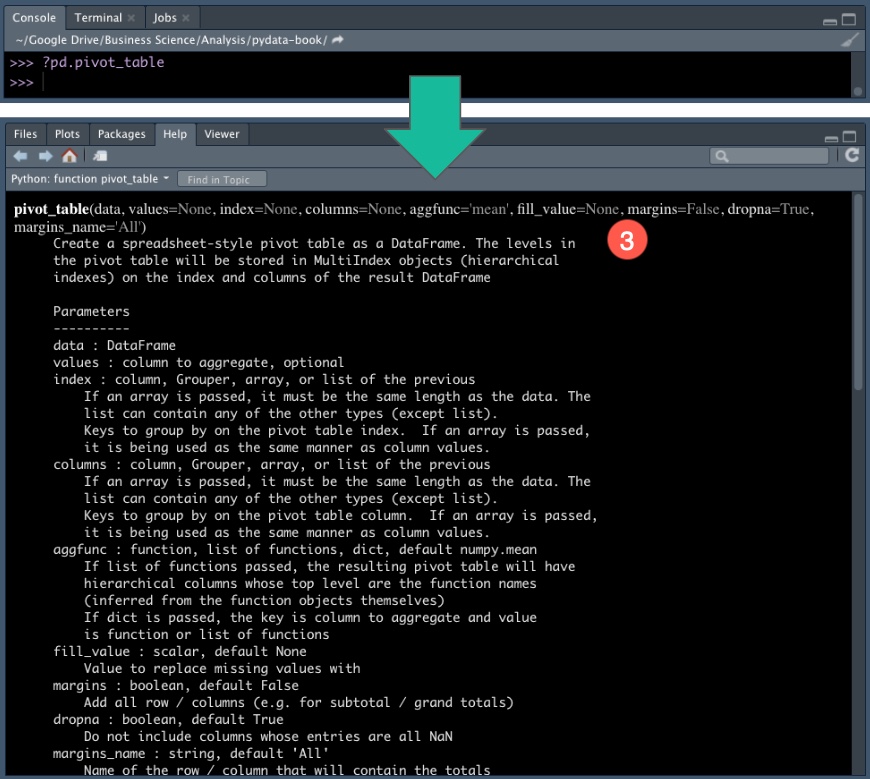
Help Documentation in the Help Panel
Measuring Rating Disagreement
We can do a bit of data manipulation to measure ratings disagreement for the most active titles. First, we need to assess which titles are the most active. We can group by “title” and use the size() function to count how many appearances each title makes in the data.
ratings_by_title = data.groupby("title").size()
print(ratings_by_title[:5])
## title
## $1,000,000 Duck (1971) 37
## 'Night Mother (1986) 70
## 'Til There Was You (1997) 52
## 'burbs, The (1989) 303
## ...And Justice for All (1979) 199
## dtype: int64
The next bit of code returns the index for the all titles that have more than 250 ratings.
active_titles = ratings_by_title.index[ratings_by_title >= 250]
print(active_titles)
## Index([''burbs, The (1989)', '10 Things I Hate About You (1999)',
## '101 Dalmatians (1961)', '101 Dalmatians (1996)', '12 Angry Men (1957)',
## '13th Warrior, The (1999)', '2 Days in the Valley (1996)',
## '20,000 Leagues Under the Sea (1954)', '2001: A Space Odyssey (1968)',
## '2010 (1984)',
## ...
## 'X-Men (2000)', 'Year of Living Dangerously (1982)',
## 'Yellow Submarine (1968)', 'You've Got Mail (1998)',
## 'Young Frankenstein (1974)', 'Young Guns (1988)',
## 'Young Guns II (1990)', 'Young Sherlock Holmes (1985)',
## 'Zero Effect (1998)', 'eXistenZ (1999)'],
## dtype='object', name='title', length=1216)
We can filter out to just the titles with more than 250 ratings using the index.
mean_ratings_active = mean_ratings.ix[active_titles]
print(mean_ratings_active[:5])
## gender F M
## title
## 'burbs, The (1989) 2.793478 2.962085
## 10 Things I Hate About You (1999) 3.646552 3.311966
## 101 Dalmatians (1961) 3.791444 3.500000
## 101 Dalmatians (1996) 3.240000 2.911215
## 12 Angry Men (1957) 4.184397 4.328421
print(mean_ratings_active.shape)
## (1216, 2)
We can get the difference between the genders and assess the greatest differences. We’ll also add the absolute difference using np.abs().
mean_ratings_active["diff"] = mean_ratings_active["M"] - mean_ratings_active["F"]
mean_ratings_active.sort_index(by="diff", inplace=True)
mean_ratings_active["diff_abs"] = np.abs(mean_ratings_active["diff"])
print(mean_ratings_active[:10])
## gender F M diff diff_abs
## title
## Dirty Dancing (1987) 3.790378 2.959596 -0.830782 0.830782
## Jumpin' Jack Flash (1986) 3.254717 2.578358 -0.676359 0.676359
## Grease (1978) 3.975265 3.367041 -0.608224 0.608224
## Little Women (1994) 3.870588 3.321739 -0.548849 0.548849
## Steel Magnolias (1989) 3.901734 3.365957 -0.535777 0.535777
## Anastasia (1997) 3.800000 3.281609 -0.518391 0.518391
## Rocky Horror Picture Show, The (1975) 3.673016 3.160131 -0.512885 0.512885
## Color Purple, The (1985) 4.158192 3.659341 -0.498851 0.498851
## Age of Innocence, The (1993) 3.827068 3.339506 -0.487561 0.487561
## Free Willy (1993) 2.921348 2.438776 -0.482573 0.482573
Visualizing Rating Disagreement
We can plot a scatter plot emphasizing the magnitude of the disagreement.
sns.relplot(x = "F", y = "M", hue = "diff_abs", size = "diff_abs", data=mean_ratings_active)
plt.title("Movie Rating Disagreement By Gender", fontdict = {"fontsize": 18})
plt.show()
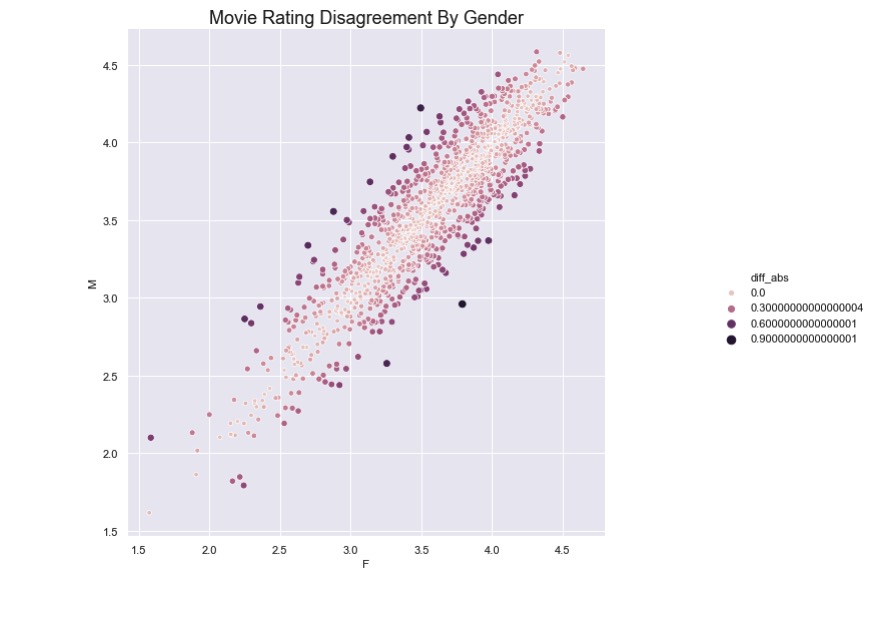
And finally, we can inspect the top and bottom movies to see which have the highest disagreement.
top_and_bottom_5 = pd.concat([mean_ratings_active[:5], mean_ratings_active[-5:]], axis=0)
print(top_and_bottom_5)
## gender F M diff diff_abs
## title
## Dirty Dancing (1987) 3.790378 2.959596 -0.830782 0.830782
## Jumpin' Jack Flash (1986) 3.254717 2.578358 -0.676359 0.676359
## Grease (1978) 3.975265 3.367041 -0.608224 0.608224
## Little Women (1994) 3.870588 3.321739 -0.548849 0.548849
## Steel Magnolias (1989) 3.901734 3.365957 -0.535777 0.535777
## Cable Guy, The (1996) 2.250000 2.863787 0.613787 0.613787
## Longest Day, The (1962) 3.411765 4.031447 0.619682 0.619682
## Dumb & Dumber (1994) 2.697987 3.336595 0.638608 0.638608
## Kentucky Fried Movie, The (1977) 2.878788 3.555147 0.676359 0.676359
## Good, The Bad and The Ugly, The (1966) 3.494949 4.221300 0.726351 0.726351
Bonus 4
Our final bonus is that the seaborn plot shows up exactly where it should: in the Plots Panel.
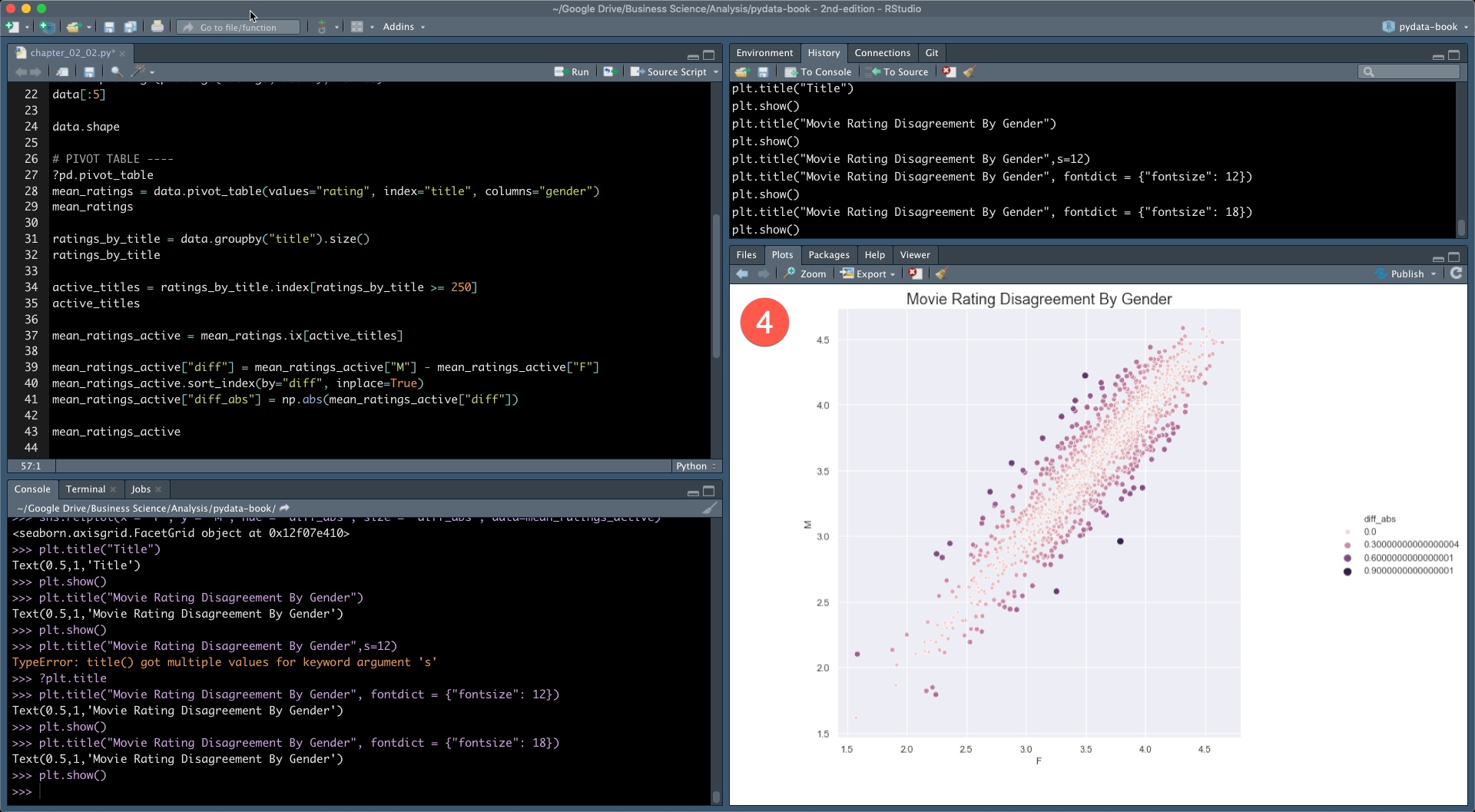
Plots show up in the Plots Panel
Conclusion
We are stoked about the prospect of the RStudio IDE supporting Python. In its current state, RStudio has an amazing level of integrated support for Python. Knowing RStudio, the features will only continue to improve. We are looking forward to seeing the RStudio IDE develop into a premier data science IDE supporting all relevant languages in the data science ecosystem.
Additional Information
We ran Python version 3.6 for this code tutorial. Note that the YouTube Video uses Python version 2.7.
# R Code - Returns python environment info
p <- reticulate::py_config()
p$version
## [1] "3.6"