timekit: Time Series Forecast Applications Using Data Mining
Written by Matt Dancho
The timekit package contains a collection of tools for working with time series in R. There’s a number of benefits. One of the biggest is the ability to use a time series signature to predict future values (forecast) through data mining techniques. While this post is geared toward exposing the user to the timekit package, there are examples showing the power of data mining a time series as well as how to work with time series in general. A number of timekit functions will be discussed and implemented in the post. The first group of functions works with the time series index, and these include functions tk_index(), tk_get_timeseries_signature(), tk_augment_timeseries_signature() and tk_get_timeseries_summary(). We’ll spend the bulk of this post introducing you to these. The next function deals with creating a future time series from an existing index, tk_make_future_timeseries(). The last set of functions deal with coercion to and from the major time series classes in R, tk_tbl(), tk_xts(), tk_zoo() (and tk_zooreg()), and tk_ts().
Benefits
So, why another time series package? The short answer is because it helps with data mining, communication between time series objects, and facilitating accurate future time series. The long answer is slightly more complicated, and I will attempt to explain.
Time Series Signature
The first reason and arguably the most important reason is the idea that there is a large amount of information stored inside a simple yet complex time index that is very useful for modeling and data mining. The time index is the collection of time-based values that define when each observation occurred. Consider the timestamp “2016-01-01 00:00:00”. This contains a wealth of information related to the observation including year, month, day, hour, minute and second. We can even extract more information including half, quarter, week of year, day of year, and so on with little effort. Next is the concept of the frequency (or periodicity or scale), which is the amount of time between multiple observations. From this time difference we can get even more information such as the periodicity of the data, whether the observations are regular or irregularly spaced, and even which observations are frequently missing. By my count, there’s at least 20+ features that can be retrieved from a simple timestamp. The important concept is that these features can exploded (or broken out) into what I’m calling the time series signature, which is nothing more than a decomposition of the unique features related to time index values. This data is very useful as it can be summarized, modeled, mined, sliced and diced, etc. As and example of the power of the signature, we can generate a prediction using data mining techniques such as this (see alcohol sales example later).
Prediction and Forecast Accuracy
The second reason is that often we want to make predictions into the future. There’s a number of packages such as forecast and prophet that already specialize in this. For forecast the future dates can be incorrect especially for daily data. A regular numeric system doesn’t contain true dates and a sequential system results in inaccuracy with respect to irregular dates. For prophet, the mechanism to compute holidays and missing days is internal to the predict() method, and therefore the a method specific to creating future dates is needed. Two types of days cause problems: those that are regularly skipped and irregularly skipped. The regularly skipped days (such as weekends or sometimes companies get to take every other Friday off) need to be factored into the future date sequence. The irregularly skipped days (think holidays) cause issues as well, and these suffer the additional problem as they can be difficult (but not impossible) to predict.
Communication and Coercion Between Time-Based Object Classes
The third reason is that the R object structures that contain time-based information are difficult use together. My first attempt was born in tidyquant where I created the as_tibble() and as_xts() functions to coerce (convert) back and forth. I was naive in this attempt because the problem is larger: we have zoo, ts and many other packages that work with time-based information. The xts and zoo packages solved part of the problem, but there’s two issues that persist. First, the time-based tibble (“tidy” data frame with class tbl) does not communicate well with the rest of the group. Coercing to xts, zoo and ts objects can result in a lot of issues especially when coercion rules for homogeneous object classes take over. Weird things can happen such as turning numeric data into character or converting date to numeric without warning. Further, each coercion method (as_tibble, as.xts, as.zoo, as.ts) has its own nuances that are inconsistent. Second, some classes like ts do not use a time-based index, but rather use a regularized numeric-based index. Without maintaining the time-based index, we can never go back to the original data structure, whether it is tbl, xts, zoo, etc.
Enter timekit
The timekit package solves each of these issues. It includes functions to create a time series signature and a time series summary from a sequence of dates. It includes methods to accurately generate future time series index values, which is especially important for daily data. It provides consistent coercion methods that prevent inadvertent class coercion issues resulting from homogeneous object structures and that maximize time-based index retention for regularized data structures.
Test Driving timekit
Let’s take timekit for a test drive. We’ll be using a few other packages in the process to help with the examples. First, install timekit.
install.packages("timekit")
Next, load these packages:
library(tidyquant)
library(timekit)
Example 1: Predicting Daily Volume for FB
This example is intended to expose potential users to several functions in timekit. We’ll develop a prediction algorithm to predict daily volume using the time series signature. First, start with the FANG data set from the tidyquant package. Filter to get just the FB stock prices, and select the “date” and “volume” columns. This is a typical time series data structure. A time-based tibble with a “date” column and a features column (“volume” in this case).
FB_tbl <- FANG %>%
filter(symbol == "FB") %>%
select(date, volume)
FB_tbl
## # A tibble: 1,008 × 2
## date volume
## <date> <dbl>
## 1 2013-01-02 69846400
## 2 2013-01-03 63140600
## 3 2013-01-04 72715400
## 4 2013-01-07 83781800
## 5 2013-01-08 45871300
## 6 2013-01-09 104787700
## 7 2013-01-10 95316400
## 8 2013-01-11 89598000
## 9 2013-01-14 98892800
## 10 2013-01-15 173242600
## # ... with 998 more rows
First, split the data into two sets, one for training and one for comparing the actual output to our predictions.
# Everything before 2016 will be used for training (2013-2015 data)
train <- FB_tbl %>%
filter(date < ymd("2016-01-01"))
# Everything in 2016 will be used for comparing the output
actual_future <- FB_tbl %>%
filter(date >= ymd("2016-01-01"))
Next, augment the time series signature to the training set using tk_augment_timeseries_signature(). This function adds the time series signature as additional columns to the data frame. The signature will be used next for the data mining process.
train <- tk_augment_timeseries_signature(train)
train
## # A tibble: 756 × 24
## date volume index.num diff year half quarter month
## <date> <dbl> <int> <int> <int> <int> <int> <int>
## 1 2013-01-02 69846400 1357084800 NA 2013 1 1 1
## 2 2013-01-03 63140600 1357171200 86400 2013 1 1 1
## 3 2013-01-04 72715400 1357257600 86400 2013 1 1 1
## 4 2013-01-07 83781800 1357516800 259200 2013 1 1 1
## 5 2013-01-08 45871300 1357603200 86400 2013 1 1 1
## 6 2013-01-09 104787700 1357689600 86400 2013 1 1 1
## 7 2013-01-10 95316400 1357776000 86400 2013 1 1 1
## 8 2013-01-11 89598000 1357862400 86400 2013 1 1 1
## 9 2013-01-14 98892800 1358121600 259200 2013 1 1 1
## 10 2013-01-15 173242600 1358208000 86400 2013 1 1 1
## # ... with 746 more rows, and 16 more variables: month.xts <int>,
## # month.lbl <ord>, day <int>, hour <int>, minute <int>,
## # second <int>, wday <int>, wday.xts <int>, wday.lbl <ord>,
## # mday <int>, yday <int>, week <int>, week.iso <int>, week2 <int>,
## # week3 <int>, week4 <int>
Next, model the data using a regression. We are going to use the lm() function to model volume using the time series signature.
fit_lm <- lm(volume ~ ., data = train[,-1])
summary(fit_lm)
##
## Call:
## lm(formula = volume ~ ., data = train[, -1])
##
## Residuals:
## Min 1Q Median 3Q Max
## -56182422 -14721686 -3529158 9826043 289760015
##
## Coefficients: (12 not defined because of singularities)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.986e+11 4.109e+11 0.727 0.4677
## index.num 4.266e+00 6.607e+00 0.646 0.5187
## diff -4.755e+01 2.987e+01 -1.592 0.1118
## year -1.512e+08 2.086e+08 -0.725 0.4689
## half 1.669e+07 1.514e+07 1.102 0.2706
## quarter 7.128e+06 7.701e+06 0.926 0.3549
## month -1.806e+07 3.711e+06 -4.866 1.4e-06 ***
## month.xts NA NA NA NA
## month.lbl.L NA NA NA NA
## month.lbl.Q 5.420e+06 3.451e+06 1.570 0.1167
## month.lbl.C 6.025e+05 7.687e+06 0.078 0.9376
## month.lbl^4 -2.337e+06 3.422e+06 -0.683 0.4947
## month.lbl^5 -6.224e+06 8.735e+06 -0.713 0.4764
## month.lbl^6 7.658e+06 3.455e+06 2.216 0.0270 *
## month.lbl^7 6.488e+06 5.521e+06 1.175 0.2403
## month.lbl^8 3.082e+06 3.397e+06 0.907 0.3645
## month.lbl^9 NA NA NA NA
## month.lbl^10 -5.133e+06 3.389e+06 -1.515 0.1303
## month.lbl^11 NA NA NA NA
## day NA NA NA NA
## hour NA NA NA NA
## minute NA NA NA NA
## second NA NA NA NA
## wday -7.561e+05 1.391e+06 -0.544 0.5868
## wday.xts NA NA NA NA
## wday.lbl.L NA NA NA NA
## wday.lbl.Q 2.538e+06 3.569e+06 0.711 0.4773
## wday.lbl.C -6.012e+06 2.570e+06 -2.339 0.0196 *
## wday.lbl^4 -1.394e+06 2.210e+06 -0.631 0.5284
## mday NA NA NA NA
## yday NA NA NA NA
## week 1.249e+05 3.900e+06 0.032 0.9745
## week.iso 3.581e+05 2.458e+05 1.457 0.1456
## week2 -2.302e+06 2.189e+06 -1.052 0.2932
## week3 8.228e+05 1.233e+06 0.667 0.5047
## week4 1.940e+06 9.881e+05 1.963 0.0500 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 26960000 on 731 degrees of freedom
## (1 observation deleted due to missingness)
## Multiple R-squared: 0.2628, Adjusted R-squared: 0.2396
## F-statistic: 11.33 on 23 and 731 DF, p-value: < 2.2e-16
Now we need to build the future data to model. We already have the index in the actual_future data. However, in practice we don’t normally have the future index. Let’s build it using the existing index following three steps:
- Extract the index from the training set with
tk_index()
- Make a future index factoring in holidays and weekly inspection using
tk_make_future_timeseries()
- Create a time series signature from the future index using
tk_get_timeseries_signature()
# US trading holidays in 2016
holidays <- c("2016-01-01", "2016-01-18", "2016-02-15", "2016-03-25", "2016-05-30",
"2016-07-04", "2016-09-05", "2016-11-24", "2016-12-23", "2016-12-26",
"2016-12-30") %>%
ymd()
# Build new data for prediction: 3 Steps
new_data <- train %>%
tk_index() %>%
tk_make_future_timeseries(n_future = 252, skip_values = holidays, inspect_weekdays = TRUE) %>%
tk_get_timeseries_signature()
# New data should look like this
new_data
## # A tibble: 252 × 23
## index index.num diff year half quarter month month.xts
## <date> <int> <int> <int> <int> <int> <int> <int>
## 1 2016-01-04 1451865600 NA 2016 1 1 1 0
## 2 2016-01-05 1451952000 86400 2016 1 1 1 0
## 3 2016-01-06 1452038400 86400 2016 1 1 1 0
## 4 2016-01-07 1452124800 86400 2016 1 1 1 0
## 5 2016-01-08 1452211200 86400 2016 1 1 1 0
## 6 2016-01-11 1452470400 259200 2016 1 1 1 0
## 7 2016-01-12 1452556800 86400 2016 1 1 1 0
## 8 2016-01-13 1452643200 86400 2016 1 1 1 0
## 9 2016-01-14 1452729600 86400 2016 1 1 1 0
## 10 2016-01-15 1452816000 86400 2016 1 1 1 0
## # ... with 242 more rows, and 15 more variables: month.lbl <ord>,
## # day <int>, hour <int>, minute <int>, second <int>, wday <int>,
## # wday.xts <int>, wday.lbl <ord>, mday <int>, yday <int>,
## # week <int>, week.iso <int>, week2 <int>, week3 <int>, week4 <int>
Now use the predict() function to run a regression prediction on the new data.
# Prediction using a linear model, fit_lm, on future index time series signature
pred_lm <- predict(fit_lm, newdata = new_data)
Let’s compare the prediction to the actual daily FB volume in 2016. Using the add_column() function, we can add the predictions to the actual data, actual_future. We can then plot the prediction using ggplot().
# Add predicted values to actuals data
actual_future <- actual_future %>%
add_column(yhat = pred_lm)
# Plot using ggplot
actual_future %>%
ggplot(aes(x = date)) +
geom_line(aes(y = volume), data = train, color = palette_light()[[1]]) +
geom_line(aes(y = volume), color = palette_light()[[1]]) +
geom_line(aes(y = yhat), color = palette_light()[[2]]) +
scale_y_continuous(labels = scales::comma) +
labs(title = "Forecasting FB Daily Volume: New Methods Using Data Mining",
subtitle = "Linear Regression Model Applied to Time Series Signature",
x = "",
y = "Volume",
caption = "Data from Yahoo! Finance: 'FB' Daily Volume from 2013 to 2016.") +
theme_tq(base_size = 12)
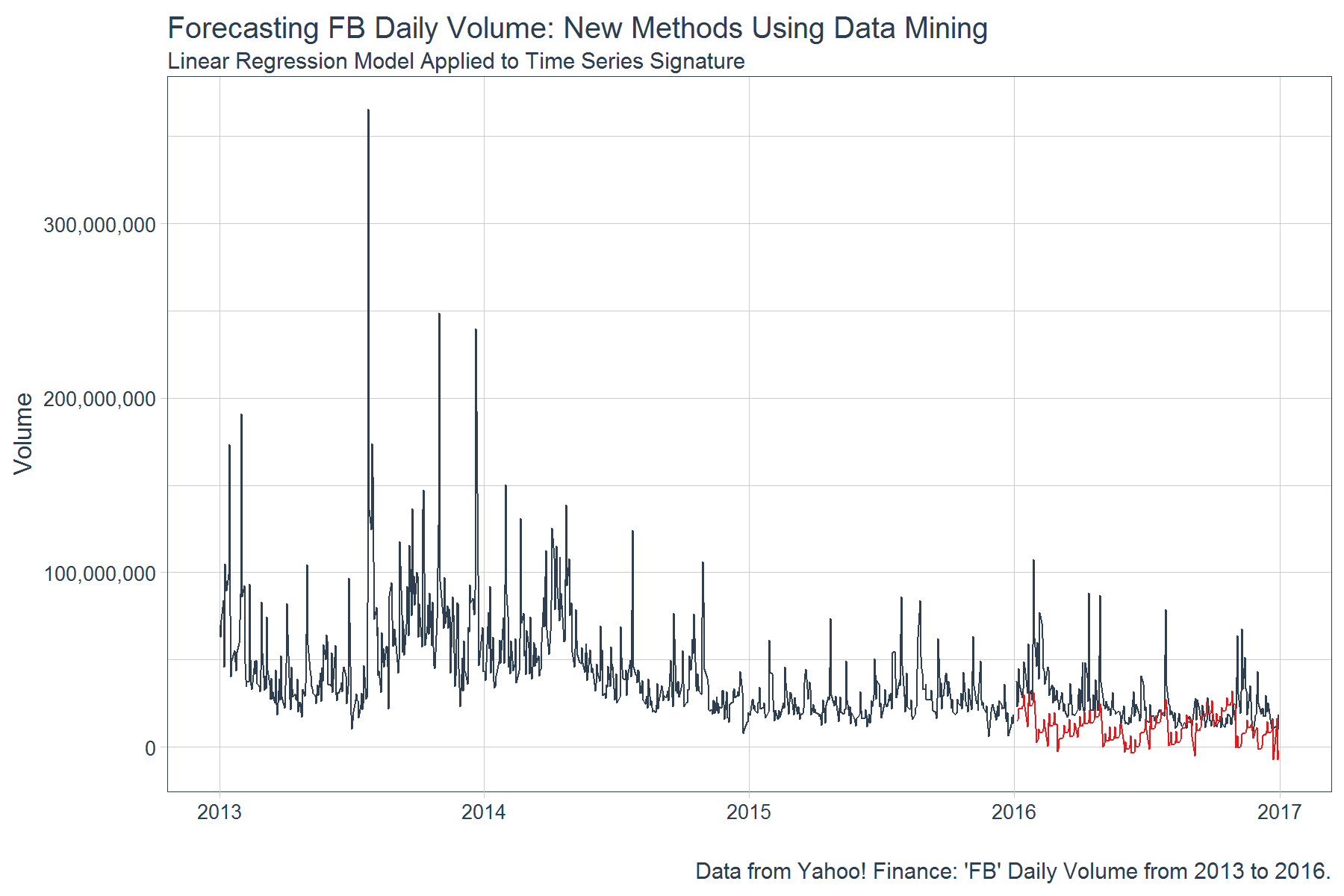
The predictions are a bit off as compared to the actuals and in some months the values are actually negative which is impossible. While the result is not necessarily earth shattering, let’s see how a regression algorithm performs data with a more prevalent pattern. Note that we did a performance comparison and the prophet package with default settings did much better job at identifying the volume pattern. With different modeling methods and tuning, the data mining approach can be significantly improved but it’s difficult to tell if the performance would be better than prophet.
Example 2: Forecasting Alcohol Sales
In this example, we’ll evaluate a time series with a more prevalent pattern. The beauty of this example is that you will see the power of data mining the time series signature with just a simple linear regression. We’ll be using a linear regression model again to model the time series signature, but you should be thinking about what other better modeling methods could be implemented. The example is truncated for brevity since the major steps are the same as Example 1.
# Collect data and convert to yearmon regularized monthly data
beer_sales <- tq_get("S4248SM144NCEN", get = "economic.data", from = "2000-01-01")
beer_sales <- beer_sales %>%
mutate(date = as.yearmon(date))
# Build training set and actual_future for comparison
train <- beer_sales %>%
filter(date < 2014)
actual_future <- beer_sales %>%
filter(date >= 2014)
# Add time series signature to training set
train <- train %>%
tk_augment_timeseries_signature()
# Fit the linear regression model to predict price variable
fit_lm <- lm(price ~ ., data = train[,-1])
# Create the new date following the 3 steps
new_data <- train %>%
tk_index() %>%
tk_make_future_timeseries(n_future = 38) %>%
tk_get_timeseries_signature()
# Make predictions using predict
pred_lm <- predict(object = fit_lm, newdata = new_data)
# Add predictions to actual_future
actual_future <- actual_future %>%
add_column(yhat = pred_lm)
# Plot using ggplot
actual_future %>%
ggplot(aes(x = date)) +
geom_line(aes(y = price), data = train, color = palette_light()[[1]]) +
geom_line(aes(y = price), color = palette_light()[[1]]) +
geom_line(aes(y = yhat), color = palette_light()[[2]]) +
scale_x_yearmon() +
scale_y_continuous(labels = scales::comma) +
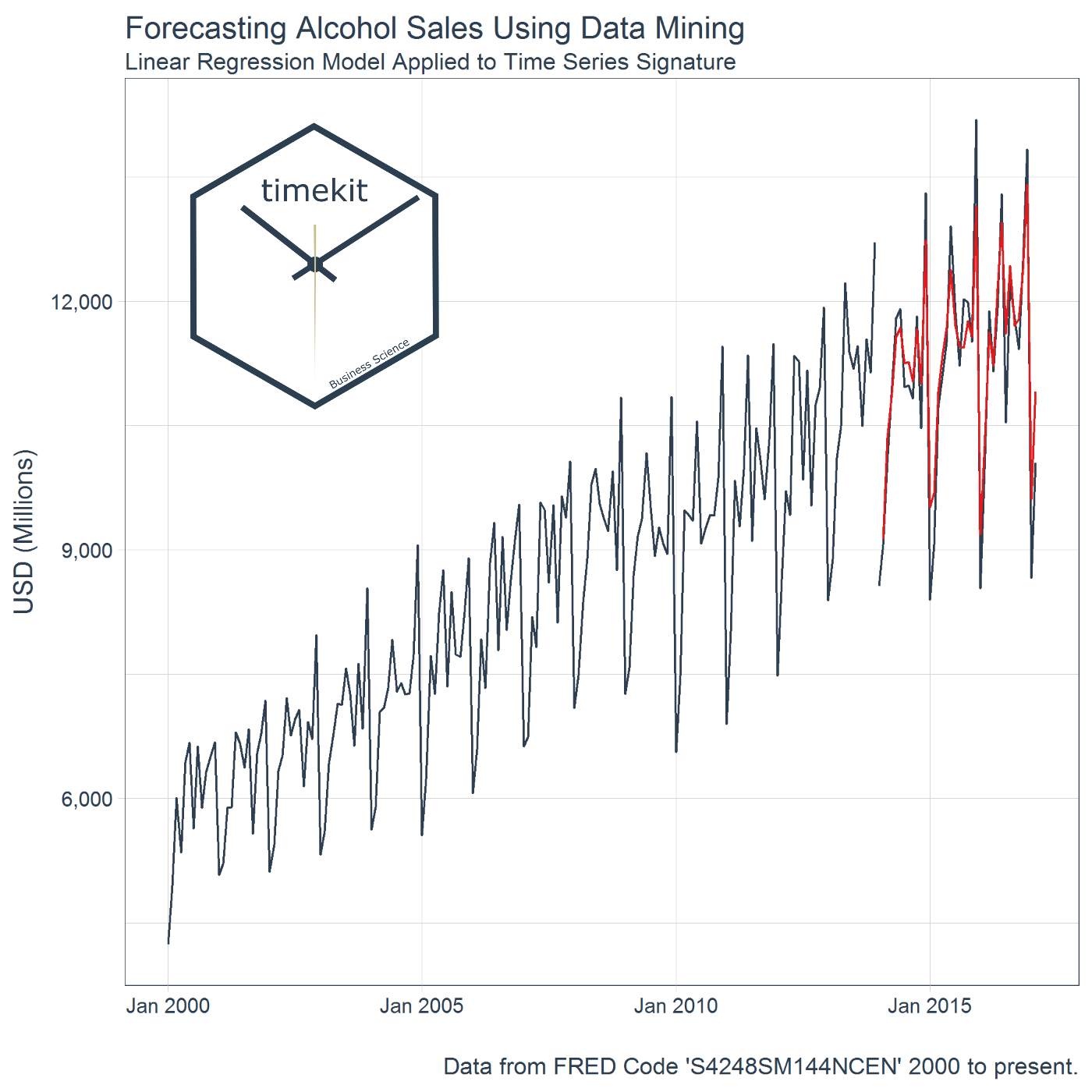
labs(title = "Forecasting Alcohol Sales Using Data Mining",
subtitle = "Linear Regression Model Applied to Time Series Signature",
x = "",
y = "USD (Millions)",
caption = "Data from FRED Code 'S4248SM144NCEN' 2000 to present.") +
theme_tq(base_size = 12)
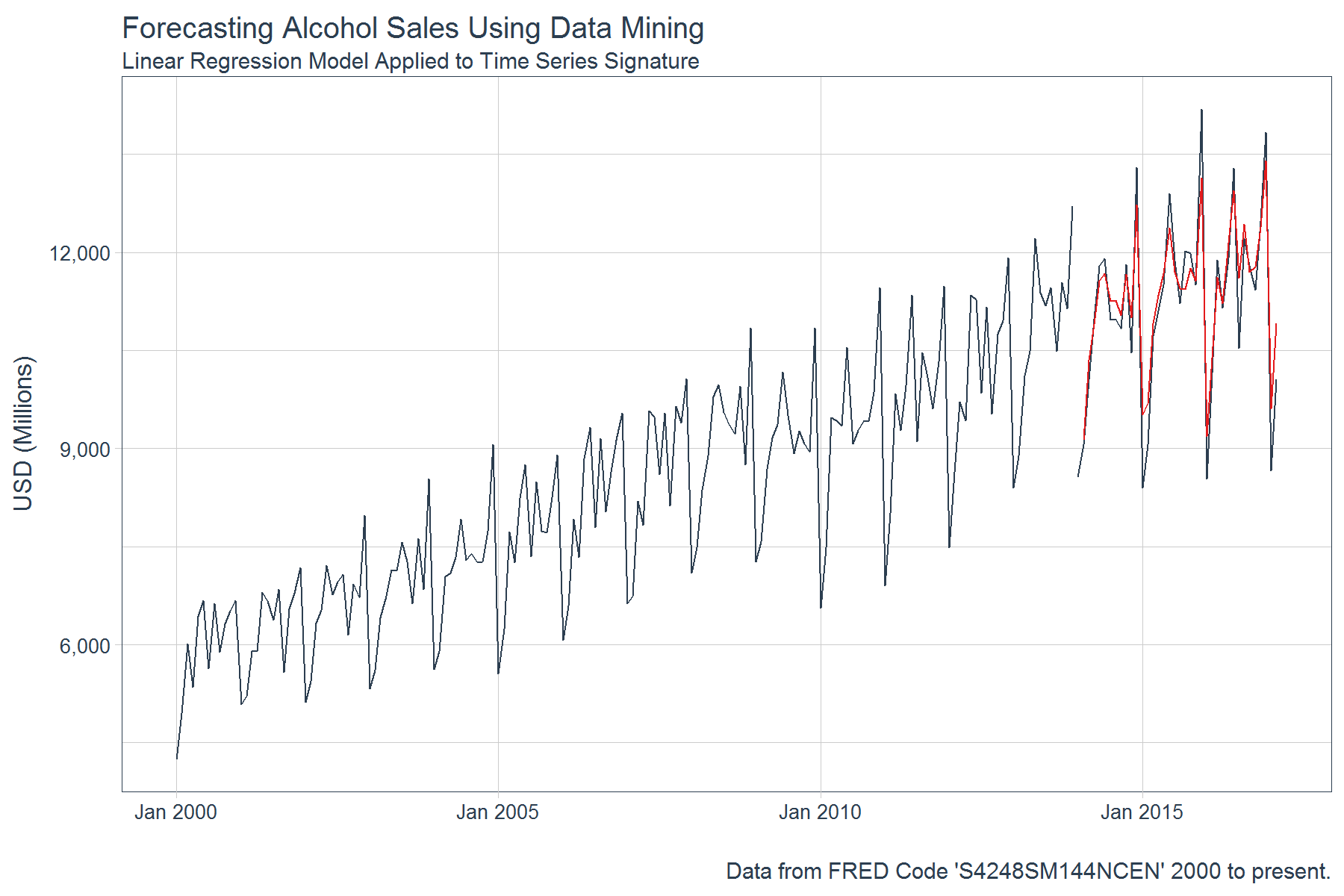
When a pattern is present, data mining using the time series signature can provide exceptional results. Further, the analyst has the flexibility to implement other data mining techniques and methods. We implemented a linear regression, but possibly other regression methods would work better.
Example 3: Simplified and Extensible Coercion
In the final example, we’ll examine briefly the various coercion functions that enable simplified coercion back and forth. We’ll start with the FB_tbl data.
FB_tbl
## # A tibble: 1,008 × 2
## date volume
## <date> <dbl>
## 1 2013-01-02 69846400
## 2 2013-01-03 63140600
## 3 2013-01-04 72715400
## 4 2013-01-07 83781800
## 5 2013-01-08 45871300
## 6 2013-01-09 104787700
## 7 2013-01-10 95316400
## 8 2013-01-11 89598000
## 9 2013-01-14 98892800
## 10 2013-01-15 173242600
## # ... with 998 more rows
We use the various timekit coercion methods to go back and forth without data loss. See how the original tibble is returned. Note the argument silent = TRUE removes the warning that the “date” column is being dropped. This is desirable since xts and the other matrix-based time classes should only use numeric data. No need to specify “order.by” arguments or worry about non-numeric data types being passed inadvertently. In addition, the ts object maintains a time-based index in addition to a regularized index.
FB_tbl %>%
tk_xts(silent = TRUE) %>% # Coerce to xts
tk_zoo() %>% # Coerce to zoo
tk_ts(start = 2013, freq = 252) %>% # Coerce to ts
tk_xts() %>% # Coerce back to xts
tk_tbl() # Coerce back to tbl
## # A tibble: 1,008 × 2
## index volume
## <date> <dbl>
## 1 2013-01-02 69846400
## 2 2013-01-03 63140600
## 3 2013-01-04 72715400
## 4 2013-01-07 83781800
## 5 2013-01-08 45871300
## 6 2013-01-09 104787700
## 7 2013-01-10 95316400
## 8 2013-01-11 89598000
## 9 2013-01-14 98892800
## 10 2013-01-15 173242600
## # ... with 998 more rows
One caveat is the going from ts to tbl. The default is timekit_idx = FALSE argument which returns a regularized index. If the time-based index is needed, just set timekit_idx = TRUE.
FB_tbl %>%
tk_ts(start = 2013, freq = 252, silent = TRUE) %>%
tk_tbl(timekit_idx = TRUE)
## # A tibble: 1,008 × 2
## index volume
## <date> <dbl>
## 1 2013-01-02 69846400
## 2 2013-01-03 63140600
## 3 2013-01-04 72715400
## 4 2013-01-07 83781800
## 5 2013-01-08 45871300
## 6 2013-01-09 104787700
## 7 2013-01-10 95316400
## 8 2013-01-11 89598000
## 9 2013-01-14 98892800
## 10 2013-01-15 173242600
## # ... with 998 more rows
Recap
Hopefully you can now see how timekit benefits time series analysis. We reviewed several of the functions related to extracting an index, adding a time series signature to an index or augmenting to a data frame, making a future time series that accounts for weekends and holidays, and coercing between various time series object classes. We also saw how the time series signature can be used in predictive analytics and data mining. The goal was to introduce you to timekit. Hopefully you now have a baseline to assist with future time series analysis.
Announcements
If you’re interested in meeting with the members of Business Science, we’ll be speaking at the following upcoming conferences:
Important Links
If you are interested learning more about timekit:
Further Reading
I find the R Data Mining Website and Reference Card to be an invaluable tool when researching (and trying to remember) the various data mining techniques. Many of these techniques can be implemented in time series analysis with timekit.