Using Drake for ETL - Building A Shiny Real Estate App
Written by David Lucey
Introduction
The State of Connecticut requires each of its 169 municipalities to report real estate sales used in the assessment process. All reported transactions by towns are published on the Office of Policy and Management (OPM) website. In the past, annual databases were disclosed with differing storage formats each year (ie: .mdb, .xlsx and .csv), and the structure used to categorize transactions changed a number of times over the period. In the last year, the state aggregated all the old annual releases from 2001-2017 (and have recently added 2018) into one data set on Socrata (removing most of the old annual reports from their website).
We have dabbled with loading and cleaning the old databases more times than we care to admit, but never ended up with a clean final product (if that is even possible). As might be expected with so many towns using different conventions for property type classification, transaction coding, and even sale amounts, so the data even at the town level can lack uniformity. Since we had already done the legwork to classify the property types from the 1999-2012 annual databases prior to the publication of the aggregated data (ie: “Single Family”, “Condo/Apartment”, etc), and weren’t convinced that the State’s version would be better, we preferred to use our own classifications where we had them. We decided to use our manually-cleaned data up until 2012, and then the OPM’s aggregated report from Socrata after that, but also wanted make it possible for someone running our code to have it work only with the Socrata API.
Though we learned a lot about data wrangling on this project, we accumulated a messy code base, with starts and stops spread across multiple notebooks as we came up with ad hoc solutions to the many challenges. When we listened to Will Landau speak in the rOpen-Sci Community Call, we learned that there weren’t many examples of ETL using drake, but it seemed like a promising means of organizing our project. This post will describe our efforts to use drake, starting from extracting, cleaning and finally deploying the data to a Shiny app. It didn’t take long to reconstitute into functions and organize according to the structure of a drake plan. It feels much cleaner, but we only scratched the surface not getting to static and dynamic branching, high performance computing or more efficient storage. Hopefully, we can learn from any comments and possibly help others by posting it.
Loading Data in the drake Plan
The drake plan organizes the project work flow according to targets, which are generated by scripts of functions and often functions of functions. The natural flow for our ETL was to check if the raw data was available on the local disc, call the OPM’s aggregated data from Socrata, merge it into our new data set where appropriate and save to disc. We wanted to make the work flow reproducible, so it should still work without the data from disc for a shorter time period. All of our code for load_raw_data(), load_socrata() and load_and_clean_sources() is available on Github. For the most part, we were able to set up and run this part without any difficulty. There are also options to store targets in more efficient formats with the fst package, but we didn’t use them, because when we tried to add them, we couldn’t get the app deployment at rsconnect to work. The times for each segment of the work flow, from loading to cleaning can be seen in the Dependency Graph below.
# R Libraries for this blogdown post
# See Github for libraries used in drake project
library(data.table)
library(DT)
knitr::opts_chunk$set(
fig.width = 15,
fig.height = 8,
out.width = '100%')
# Our drake plan
the_plan <-
drake::drake_plan(
raw_99_11 = try(load_raw_data()),
cleaned_01_recent = load_socrata(),
new = merge_and_clean_sources(
raw_99_11,
cleaned_01_recent
),
save_file = saveRDS(new, file_out("ct_sales_99_2018.RDS")),
deployment = rsconnect::deployApp(
appFiles = file_in(
"ct_sales_99_2018.RDS",
"app.R",
"R/plot_dotplot.R",
"R/plot_spaghetti.R",
"R/plot_timeplot.R"
),
appName = "ct_real_assess",
forceUpdate = TRUE
)
)
In the code above, the_plan yields a small tibble with a column for the target and an expression list column called “command” (seen below).
## # A tibble: 5 x 2
## target command
## <chr> <expr_lst>
## 1 raw_99_11 try(load_raw_data()) …
## 2 cleaned_01_rec… load_socrata() …
## 3 new merge_and_clean_sources(raw_99_11, cleaned_01_recent) …
## 4 save_file saveRDS(new, file_out("ct_sales_99_2018.RDS")) …
## 5 deployment rsconnect::deployApp(appFiles = file_in("ct_sales_99_2018.RDS…
Challenges to Deploy Shiny to rsconnect in drake
We struggled when we tried to deploy the Shiny app, because we were unclear which environment drake was using and how to get all the required elements into it (ie: the app, functions, libraries and data). The topic of deploying a Shiny app from drake seemed to be lightly covered, so we asked for help on Stack Overflow, kindly answered by Will Landau himself.
We show working code above to use file_out() to save to our local drake data folder, and then file_in() send the data, app script and supporting functions to rsconnect for deployment. Will told us that this is required to ensure that the targets are in the correct order, and to respond appropriately to changes in our app.R and ct_sales_99_2018.RDS. If we instead passed new to deployApp(), drake wouldn’t be able to detect the sequence to work out the target dependencies. In other words, these two parts would be shown as disconnected trees in the Dependency Graph (see ours below).
In addition, to sending the app elements to rsconnect via file_out() as shown in the deployment target above, we also had to separately invoke them along with the required libraries a second time within app.R to get deployment to work at shinyapps.io. Another challenge may have been that our app is using plotly for one of the charts,. There are known issues regarding passing the random seed to plotly, which we didn’t entirely understand. We weren’t clear if this was because of drake, shiny or rsconnect, and this may not be the most efficient way of accomplishing our goal, so we are open to suggestions if there is a cleaner method.
Drake Config and Dependency Graph
Will Landau recommends to always check the dependency graph before running make(), and the vis_drake_graph() function is the best way to accomplish this (see our Dependency Graph below). In any case, the flow of targets go from the data to deployment with no stray branches.
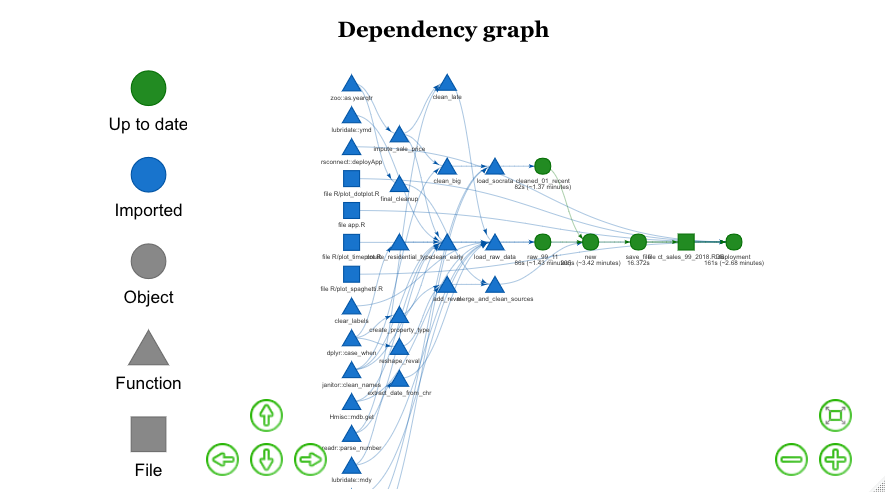
We relied heavily on Miles McBain’s Benefits of a function-based diet (The {drake} post) to set up our project file structure and _drake.R script. He has also built the dflow package, which we would use in the future, but didn’t this time, because we already had already launched the project when we discovered it. The chunk below shows our full _drake.R script which loads the required packages, functions from the R folder and calls drake_config() with our plan. Neither the plan or the drake_config() are called here for the blog post.
# Not run here
# This code comes entirely from Miles McBain's work
## Load your packages, e.g. library(drake).
source("./packages.R")
## Load your R files
lapply(list.files("./R", full.names = TRUE), source)
## _drake.R must end with a call to drake_config().
## The arguments to drake_config() are basically the same as those to make().
## lock_envir allows functions that alter the random seed to be used. The biggest
## culprits of this seem to be interactive graphics e.g. plotly and mapdeck.
drake_config(the_plan,
lock_envir = FALSE)
The last step after configuration is to run make(), which usually took 4-5 minutes. We found that the intermediate targets sometimes ran when we weren’t expecting them to, because we hadn’t made any changes. Once make() runs, all of the intermediate targets can be accessed at any time with loadd() (see below).
# Not run here
drake::make(the_plan)
Loadd and Summarize
Below, we show that we can access our finished data.table with loadd() even from a separate project directory, although here we had to set the working directory for the chunk to our drake project in order to run loadd().
setwd("/Users/davidlucey/Desktop/David/Projects/ct_real_assess/")
drake::loadd("new")
head(new)
## town next_reval_year address assessed_value sale_price
## 1: Easton 2016 173 WESTPORT RD 69830 175000
## 2: Easton 2016 40 ABBEY RD 107160 250000
## 3: Easton 2016 126 SPORT HILL RD 64070 155000
## 4: Easton 2016 S PARK AVE 97830 440000
## 5: Easton 2016 25 CARRIAGE DR 110850 180000
## 6: Easton 2016 139 JUDD RD 82100 125000
## sales_ratio non_use_code property_type date list_year qtr year
## 1: 0.3990286 0 Vacant 1999-10-07 <NA> 1999.75 1999
## 2: 0.4286400 0 Vacant 1999-11-05 <NA> 1999.75 1999
## 3: 0.4133548 0 Vacant 1999-11-04 <NA> 1999.75 1999
## 4: 0.2223409 7 Vacant 1999-11-15 <NA> 1999.75 1999
## 5: 0.6158333 0 Vacant 1999-11-17 <NA> 1999.75 1999
## 6: 0.6568000 0 Vacant 1999-11-24 <NA> 1999.75 1999
## source reval_yr
## 1: 2 3
## 2: 2 3
## 3: 2 3
## 4: 2 3
## 5: 2 3
## 6: 2 3
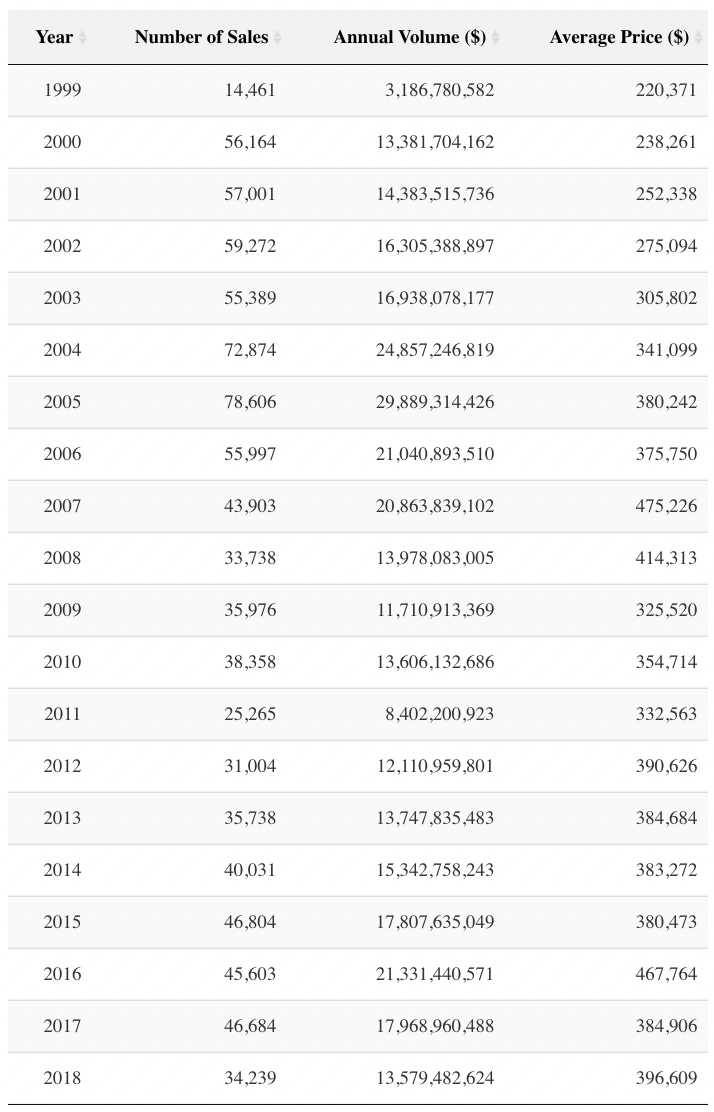
We summarize the full 900k+ set in the table below, which includes all properties and transactions types, including bankruptcy and related party. We can see the total market in CT actually peaked in number of transactions and dollar volumes in 2004-05, though average prices kept rising for two more years, and have mostly drifted downwards ever since with Connecticut’s sluggish recovery.
Shiny App
It wouldn’t be right to not include the final product..

Conclusion
Now we have a well-organized work flow which can be easily updated as new OPM releases become available on Socrata. Anybody with Socrata and rsconnect credentials should be able to clone and easily run our formerly incomprehensible code. We have a good structure to add new targets in the future. For example, we would like to geo-code the addresses, because we think there may be geographical patterns in the price movements (ie: larger plots further from commercial hubs have become less attractive to buyers over time). This is challenging because the addresses are messy and don’t have zip codes, and there don’t seem to be many low cost and comprehensive sources of CT addresses, and services like Google are expensive at this scale. Another aspiration would be to add attributes of the land and structure in order to model values and observe changing coefficients, but that seems a bridge too far.
We are also planning to an additional post on our observation that the lowest valued slice of properties in many towns are often systematically assessed more highly (relative to selling prices) than higher valued segments (hence carry an undue property tax burden). This can be seen in the Timeplot and Dotplot tabs of the Shiny app. Overall, we think there may be opportunities to combine other public data we have collected about income taxes, local government spending and public employment pensions, education and transportation as part of our “Nutmeg Project” to try to understand what has gone wrong to make one of the best educated and highest income states in the country, also the most financially fragile.
Author: David Lucey, Founder of Redwall Analytics
David spent 25 years working with institutional global equity research with several top investment banking firms.