Case Study: How To Build A High Performance Data Science Team
Written by Matt Dancho and Rafael Nicolas Fermin Cota
Artificial intelligence (AI) has the potential to change industries across the board, yet few organizations are able to capture its value and realize a real return-on-investment. The reality is that the transition to AI and data driven analysis is difficult and not well understood. The issue is twofold, first, the necessary technology to complete such a task has only recently become mainstream, and second, most data scientists are inexperienced in their respective industries. However, with all the uncertainty surrounding this topic, one hedge fund has managed to navigate through these challenges and accomplish what many companies are failing to do: building a high-performing data science team that achieves real return-on-investment (ROI).
This is the story of an outlier
Business Science was recently invited inside the walls of Amadeus Investment Partners, a hedge fund that has unlocked the power of artificial intelligence to gain superior results in one of the most competitive industries in the world: investments. Amadeus Investment Partners has spent the last five years building a high performance data science team. What they have built is nothing short of extraordinary.
In this article, we will discover what makes Amadeus Investment Partners an outlier and why they are unique in the data science space. We will learn the key ingredients that provide Amadeus a recipe that is driving ROI with artificial intelligence and examine what it takes to assemble a high-performance data science team.
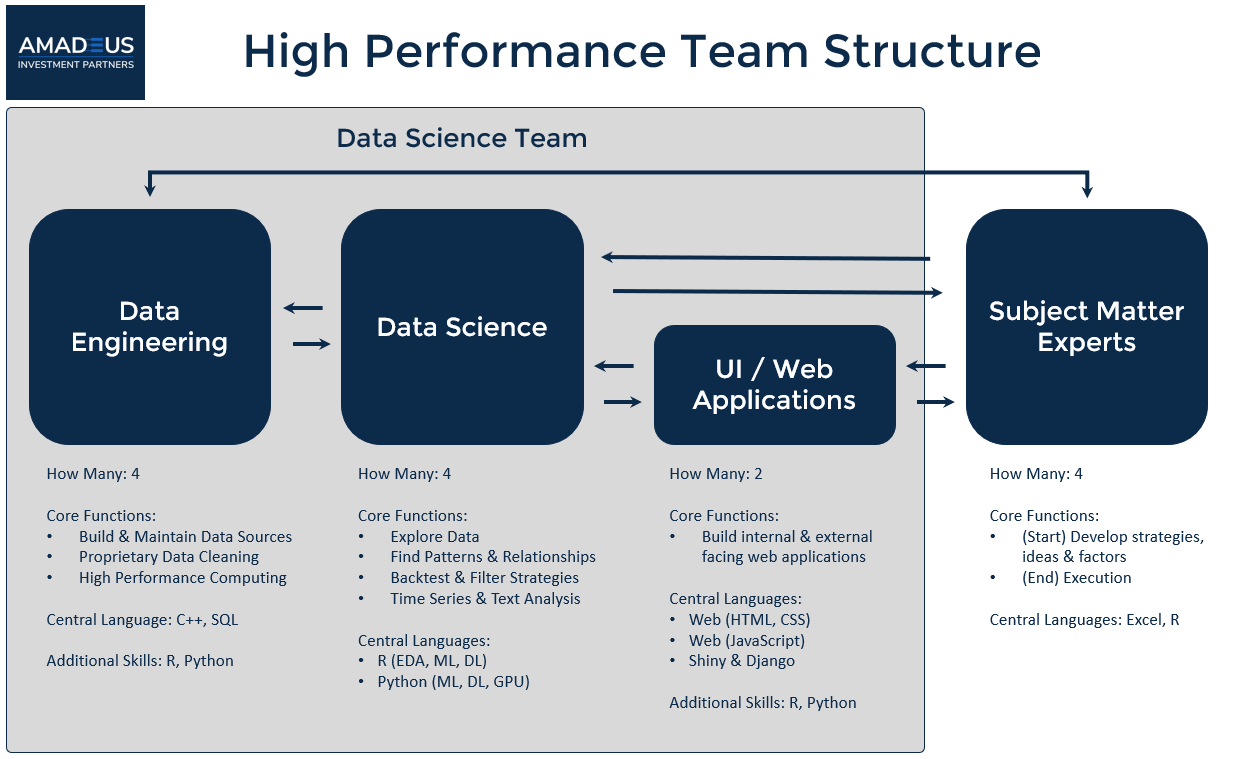
Data Science Team Structure, Amadeus Investment Partners
We will then describe how Business Science is using this information to develop best-in-class data science education in the form of both on-premise custom workshops and on-demand virtual workshops. We will show how we are integrating the exact same cutting-edge technology into our data science for business programs.
This is all aimed at one thing: developing a system for creating best-in-class data science teams.
If you are interested in developing a best-in-class data science team, then read on.
Examining An Outlier
Amadeus Investment Partners is a hedge fund that blends traditional fundamental investment principles with cutting-edge quantitative techniques to create “Quantamental” strategies that identify assets that yield excellent returns while minimizing risk for their investors. Their goal is to provide their investors with superior risk-adjusted returns.
Amadeus’ strategy is working. Here’s an overview of backtest results from 2005 in comparison to the S&P 500, which is a difficult benchmark to outperform. Over the backtest period, we can see that Amadeus’ strategy delivered “alpha”, which means the strategy generated excess returns (performance) beyond the returns of the benchmark.
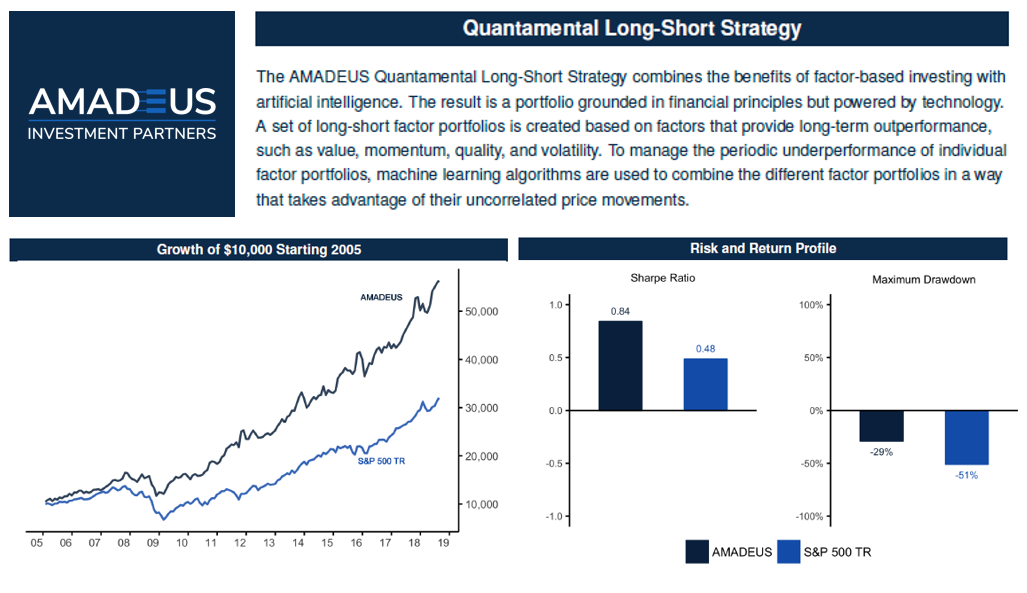
Risk-Return Performance, Amadeus' Quantamental Long-Short Strategy
From the Growth of $10,000 Starting 2005 chart, Amadeus appears to be a well-performing hedge fund. However, it’s not until we dive into the Risk and Return Profile, that we begin to see the magic come to light. The Sharpe Ratio, which is a ratio of reward-to-risk that is commonly referenced in investing, is almost double the S&P 500 over this time period. This means that Amadeus is taking less risk per unit of reward as compared to the S&P 500. Furthermore, the Maximum Drawdown, or the largest loss from the peak during the time frame, was about half of the S&P 500 during the same time period. Ultimately, what this means is that Amadeus is delivering exceptional returns while taking on less risk, which is very attractive to investors.
But, how is Amadeus achieving these results?
A Radically Different Organization
In our meetings with Amadeus, we found 3 key components to the high-performance data science team. Each of these are critically important to Amadeus’ successful execution of their radically-different data-driven strategy. Amadeus:
- Finds and trains talent in the most unlikely fashion
- Has a well-designed team structure and culture
- Provides access to cutting-edge technology
We will step through each of these key ingredients that make up the data-driven recipe for success.
Key 1: Finding and Training Talent in the Most Unlikely Fashion
The first key to the puzzle is finding and developing the talent to execute on the vision. That’s where Amadeus has excelled: finding talent in the most unlikely places.
Over the past several years, Amadeus has tactically been working with the leading educational institutions in Canada to selectively gain access to top students in…
Business Programs
Yes - Students that are top in their classes in Business Programs. If you take a look at the demographics of their team, most don’t have math or physics backgrounds. If you’re familiar with the conventional data science team makeup full of math and computer science Ph.D.’s, this might come as a surprise to you.
This unusual hiring practice is founded on the belief that the subject knowledge and the communication skills that the top business students bring are critical advantages in Amadeus’ data-driven approach. At the end of the day, data science is a tool that people use to answer questions that they’re interested in, and hiring people with the relevant subject matter expertise will ensure that the right questions will be asked. Amadeus subsequently converts these business-minded people to data scientists by augmenting their skillset with math and programming on the job.
“Hiring people with the relevant subject matter expertise ensures that the right questions are asked.”
-Rafael Nicolas Fermin Cota
In terms of training the hired talent, Amadeus has a distinct advantage. One of the founders, Rafael Nicolas Fermin Cota, was a professor at the Ivey Business School at Western University, one of the top schools for business in Canada. In his curriculum, he taught his students how to make business decisions using data science. He states,
“My work entails teaching students how to think. The specific course material, they may forget. But, if they learn to think, they will learn to solve the problems they face in their professional careers.”
-Rafael Nicolas Fermin Cota
It’s this spirit of learning and critical thinking that you experience when meeting with the Amadeus data science team. What you also take away is a structured approach to this intellectual curiosity. Each member told stories of their start at Amadeus. It begins the same - learning to code, studying statistics, and getting a great deal of mentorship. It takes six months of education and training before a new employee is ready to be an integral part of the team. The core curriculum includes the following concepts:
- Database management: Obtaining data from various sources and storing it effectively for further access.
- Data manipulation: Working with raw data (often in many different formats) and turning them into an
organized dataset that can be easily analyzed.
- Exploratory data analysis: Exploring the data to determine various characteristics of the dataset (NAs,
mean, standard deviation, type, etc.).
- Predictive Modelling: Using available data to predict the future outcome using machine learning and other
artificial intelligence concepts.
- Visualization: Presenting the results of the exploratory data analysis and predictive modelling to various
audiences.
This core training ensures a common body of knowledge that team members draw from during discussions, making the communication process much more efficient.
To continue the education and professional development of the team members, everyone is free to purchase any books, courses, or other training material as needed.
Key 2: Well-Designed Team Structure and Collaborative Culture
Once the initial training is over, each new hire is ready to be integrated into a functional part of the team. Integration involves finding the role that best suits their skill sets along with Amadeus’ needs. This approach allows the new hire to fill a position they are interested in while benefiting the organization.
The team structure was carefully designed to optimize the talent of the team members and to transparently reflect the desired interaction among the team members. Think of the High Performance Team Structure like the blueprint for success.
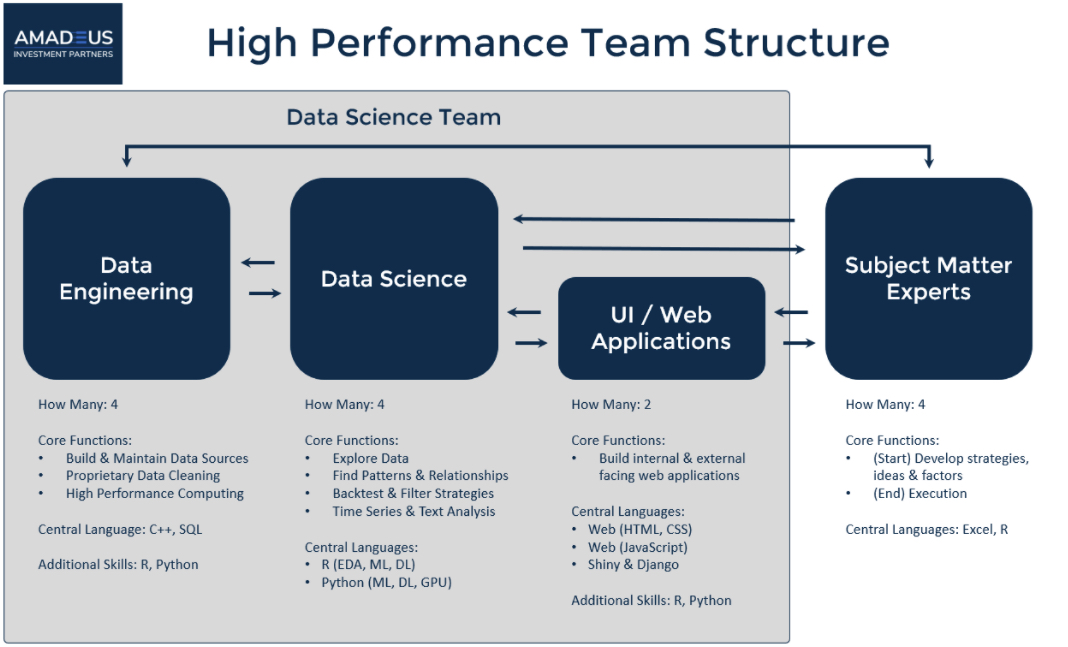
Data Science Team Structure, Designed for High Performance
It involves four key roles:
- Subject Matter Experts
- Data Engineering Experts
- Data Science Experts
- User Interface Experts
Subject Matter Experts (SME)
Amadeus has four SMEs that are involved at both the beginning and end of the investment strategy development process. At the beginning of the process, the SMEs are responsible for generating initial ideas for new strategies. These ideas are grounded on business fundamentals and meticulously researched before being discussed with the Data Engineering and the Data Science teams. The SMEs are also responsible for the end of the process, which is the execution of the strategies. This ensures that the investment execution in line with the original design of the strategies.
Relevant Skill-Sets:
- Accounting and Finance: Deep understanding of financial analysis and capital markets is required to build initial strategy ideas
- Excel: Excel is used to store initial strategy ideas
- R:
R is used to perform data exploration and efficiently work with data
Data Engineering Experts (DEE)
When the SMEs come up with new strategy ideas, the Data Engineering team is subsequently called to gather and make available the data required for the Data Science team to test the ideas. With petabytes of financial data at hand, the DEEs need to master programming methods that will make data delivery and computation as efficient as possible. Also, Amadeus has focused on data quality since further analysis is only meaningful given good quality data. The financial data is often noisy, contains many missing values, and requires timestamp joins, which is very difficult due to the size of the data and the fact that global data sources rarely align.
Relevant Skill-Sets:
- C++:
C++ is a high performance language at the heart of their data engineering operation. Parallelizing computations and developing distributed systems using C++ enables Amadeus to take full advantage of working with big data
- SQL:
SQL is the language used to directly interact with their databases
- R: The
data.table package is mainly used to scale R for speed when taking strategies from the exploration
to production
Data Science Experts (DSE)
The DSEs at Amadeus are critical for exploring various properties of ideas generated by the SMEs and developing different algorithms required by the strategy, based on their expertise in statistical analysis, machine learning (supervised and unsupervised), time series analysis, and text analysis. The main challenge they face is being able to iterate through the stream of hypotheses generated by the SMEs and rapidly develop analyses. They are the ones who identify patterns or anomalies in the dataset, produce concise reports for the SMEs to allow fast interpretation of results, and determine when the ROI from a project has diminished and new projects should be started.
Relevant Skill-Sets:
- R:
R is used for exploratory data analysis (EDA) and visualization because of its ease of use for exploration. The tidyverse is predominantly being used for quickly transforming data prior to exploration.
- Python:
Python is used for advanced machine learning and deep learning with high-performance NVIDIA GPUs. All the top deep learning frameworks are available in Python and can be easily deployed through the tools provided in the NVIDIA GPU Cloud.
User Interface Experts (UIE)
Amadeus develops interactive web applications to support internal decision-making and operations. New challenges present themselves when building dashboards. The application needs to be customized to the problem but also perform well when it comes to interactivity. Given these constraints, building a performant application often comes down to selecting the right tools. The UIEs use R + Shiny for lightweight applications or Python, Django and JavaScript when performance and interactivity are major concerns.
Relevant Skill-Sets:
- Databases: Data-driven web applications start at the database. Knowledge of the appropriate query language (
SQL, MongoDB, etc.) is necessary for effectively handling data.
- Data Analysis:
R + Shiny can be used for a quick proof of concept, while Python + Django are used for production level performance.
- Web Development:
HTML, CSS, JavaScript are a necessity when creating sophisticated web-based user interfaces.
Emphasis on Communication
An often overlooked part of a data science team is the team aspect, which requires communicating ideas and analyses through the workflow. For most other organizations, various departments work in silos, only interacting with each other at the senior management level. This prevents members from seeing the big picture and breeds internal competition for the detriment of the organizational performance.
At Amadeus, collaborative culture is encouraged as every project is carried out by a cross-sectional team, involving at least one person from each of the four functional parts described above. This way, the projects can benefit from the different perspectives of team members and the research process is streamlined without conflicts between each stage.
Also, all-hands weekly meetings are organized to keep each other up to date on individual progress and create a forum for team members to share insights and suggestions.
Key 3: Access to Cutting-Edge Technology

As mentioned above, it takes tremendous effort to find and train talent and have them work collaboratively. At this point, all of this effort would be futile if there was a technological bottleneck in the research process.
Data Science Team members have full access to computational infrastructure for both GPU intensive work (DL, NLP), and CPU intensive work (data cleaning, report generation, EDA). Their systems provide all team members immediate access to high-performance computational resources to minimize the time spent waiting for computations to run. This enables the team to quickly iterate through ideas.
At Amadeus, each team has their own computation stack as to not interfere with the work of the other teams. This infrastructure is all connected to allow interaction between teams.
- Data Engineering: Systems optimized for populating and querying databases. The DEEs provide a custom API that allows all other teams immediate access to data.
- Data Science: High-performance CPU and GPU systems ideal for training machine learning models and performing EDA.
- UI/Web Applications: Systems designed specifically for hosting web applications and in-house Shiny/Django applications. The UIEs can use the DSEs’ infrastructure when high-performance computations are required in the backend.
- Subject Matter Experts: Access to data and high-performance hardware through front-end APIs as well as hardware specifically designed for their execution needs.
Amadeus has partnered with NVIDIA, pioneers of the next generation of computational hardware for Artificial Intelligence research and deployment. The team is actively using high-performance computing with their in-house analytical technology stack that boasts the NVIDIA DGX-1, the world’s fastest deep learning system.
Business Science witnessed Amadeus’ data science team train a text classifier on financial news data for predicting article sentiment. The NVIDIA DGX-1 produced results in a matter of minutes, what would have taken several hours if not days on a CPU system or even a GPU system that is not optimized for deep learning.
Best-In-Class Data Science Education
Turning Insights Into Education
Business Science has gained the following insights from the Amadeus case study:
- Hiring talent with subject matter expertise and subsequently educating them in data science has proven to be effective in building a high performance team
- Communication among different teams is important, and education needs to support communication among the different teams
- The teams need to be equipped with the latest technology to reach full potential
Unfortunately, data science education is still in its infancy because most educational institutions don’t understand what it takes to do real-world data science. Most programs focus on theory or tools. This doesn’t work. Learning how to do real-world data science only comes from application and integration, and those with an understanding of the business have an advantage.
This is why Business Science is different.
We have built a best-in-class educational program that incorporates learnings:
- Through studying an outlier - A radically different data science team of the highest caliber that is successfully generating ROI for their organization.
- Through our own applied consulting experiences that have successfully generated ROI for organizations
- Through experience building the tools and software needed to solve business problems
The next-generation Business Science education offers two options that integrate this knowledge.
Building A Data Science Team? Business Science Can Help.
We are your educational partner. We are here to support your transition by providing best-in-class data science education. No matter what point you are at, we will take you where you need to go. Contact us to learn more about our educational data science capabilities.