Recreating RView's ''Reproducible Finance With R: Sector Correlations''
Written by Davis Vaughan
The folks at RStudio have a segment on their RViews blog, “Reproducible Finance with R”, one that we at Business Science are very fond of! In the spirit of reproducibility, we thought that it would be appropriate to recreate the RViews post, “Reproducible Finance with R: Sector Correlations”. This time, however, the tidyquant package will be used to streamline much of the code that is currently used. The main advantage of tidyquant is to bridge the gap between the best quantitative resources for collecting and manipulating quantitative data: xts, zoo, quantmod and TTR, and the data modeling workflow and infrastructure of the tidyverse. When implemented, tidyquant cuts the code down by about half and simplifies the workflow.
Table of Contents
Correlating Sector ETF Returns to the SP500
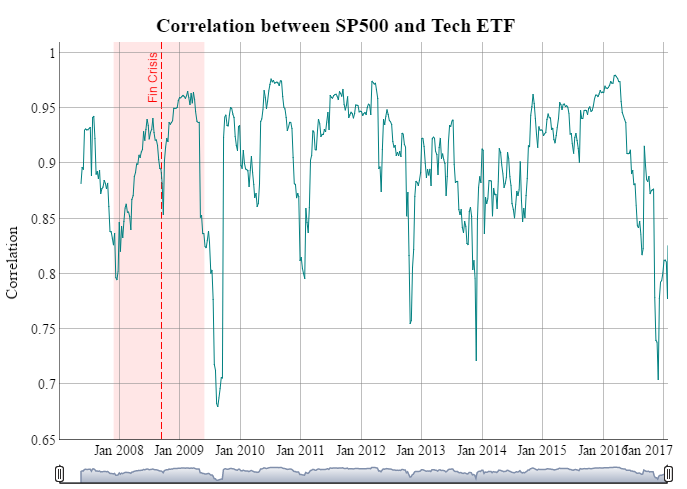
The folks at RStudio have a new segment in RViews (The RStudio blog) called “Reproducible Finance with R”. For their first installation of 2017 they looked at how Sector Exchange Traded Fund (ETF) returns correlate to the broader market using the Spider SP500 ETF (“SPY”) as a proxy for the SP500 index. The RViews post can be found here, and here’s a snapshot of the final chart comparing the correlation between the SP500 (overall market) and the Technology ETF over time.
Source: Reproducible Finance with R: Sector Correlations
Today, the newest member of the Business Science (BizSci) team, Davis Vaughan, shows how you can implement our R financial package, tidyquant, to streamline the RViews Sector Correlations analysis. I hope you’ll join me in welcoming Davis to our team! You can follow him on twitter, LinkedIn and GitHub.
Matt Dancho, Director of Product Development @ BizSci
Prerequisites
Let’s start by loading some packages.
library(tidyquant)
library(dygraphs)
We’ll use the same ETF tickers as RViews.
# List of tickers for sector etfs.
ticker <- c("XLY", "XLP", "XLE", "XLF", "XLV",
"XLI", "XLB", "XLK", "XLU", "SPY")
# And the accompanying sector names for those ETFs.
sector <- c("Consumer Discretionary", "Consumer Staples",
"Energy", "Financials", "Health Care", "Industrials",
"Materials", "Information Technology", "Utilities", "Index")
etf_ticker_sector <- tibble(ticker, sector)
etf_ticker_sector
## # A tibble: 10 × 2
## ticker sector
## <chr> <chr>
## 1 XLY Consumer Discretionary
## 2 XLP Consumer Staples
## 3 XLE Energy
## 4 XLF Financials
## 5 XLV Health Care
## 6 XLI Industrials
## 7 XLB Materials
## 8 XLK Information Technology
## 9 XLU Utilities
## 10 SPY Index
Data Import
Alright, now is where things get interesting! Let’s take a peek at the differences in how you might get data to solve this problem.
RViews
Here’s the RViews code snippet. RViews created a special function to import closing prices using getSymbols() directly from the quantmod package. They then used periodReturn() to convert these prices to weekly log returns. Internal to the function, there are calls to getSymbols and do.call with merge and lapply twice, once to get closing prices and once to get log weekly returns. Pretty complicated. Kudos to the author, Jonathan Regenstein, at RStudio for figuring this out.
# A function to build an xts object of etf returns.
etf_weekly_returns <- function(ticker) {
# Download prices using getSybmols
symbols <- getSymbols(ticker, auto.assign = TRUE, warnings = FALSE)
# Take just the Closing prices.
etf_prices <- do.call(merge, lapply(symbols, function(x) Cl(get(x))))
# Use the periodReturn() function to get log weekly returns.
etf_returns <- do.call(merge, lapply(etf_prices,
function(x) periodReturn(x,
period = 'weekly',
type = 'log')))
#Change the column names to the sector names from our dataframe above.
colnames(etf_returns) <- etf_ticker_sector$sector
etf_returns
}
# Let's pass in our ticker symbols and build an xts object of etf returns
etf_returns_rviews <- etf_weekly_returns(etf_ticker_sector$ticker)
head(etf_returns_rviews)
## Consumer Discretionary Consumer Staples Energy
## 2007-01-05 -0.007034027 -0.005722007 -0.011733539
## 2007-01-12 0.026062578 0.014055350 -0.008620725
## 2007-01-19 0.008875499 0.003765102 0.020354264
## 2007-01-26 -0.019888442 -0.004519819 0.004760584
## 2007-02-02 0.022409825 0.011634547 0.030830343
## 2007-02-09 -0.006315545 -0.010502685 -0.004101903
## Financials Health Care Industrials Materials
## 2007-01-05 -0.011167160 0.005655589 -0.007693470 -0.0113323889
## 2007-01-12 0.013331718 0.017361037 0.017579216 0.0290876947
## 2007-01-19 -0.001081666 0.011312637 0.001123511 0.0152115609
## 2007-01-26 -0.003795098 -0.012772249 -0.011577145 0.0086291974
## 2007-02-02 0.015362168 0.014501414 0.027452705 0.0151288535
## 2007-02-09 -0.005901386 -0.005485765 -0.009439299 -0.0008194183
## Information Technology Utilities Index
## 2007-01-05 0.007260335 -0.019471313 -0.005888436
## 2007-01-12 0.021886396 -0.006668599 0.019029484
## 2007-01-19 -0.027005903 0.005005572 -0.002936435
## 2007-01-26 -0.001283929 0.005532545 -0.004842978
## 2007-02-02 0.016985546 0.023177534 0.018680358
## 2007-02-09 -0.008881386 0.025021348 -0.006025965
BizSci
And, the BizSci version using tidyquant. We first get the ETF prices using tq_get() and group the prices by ticker and sector. Then we use tq_transform() to get the period returns from the stock prices.
If you are new to tidyquant, tq_transform() is used when the return is in a different periodicity than the input. It accepts ohlc_fun = Cl and transform_fun = periodReturn , along with any additional periodReturn args passed by way of .... This tells the function to use the closing price to calculate period returns and return the result as a new tibble. Note that typically you would used the ohlc_fun = Ad for period returns since stock splits are present in closing prices, but for an ETF we should not have splits.
# Get stock prices
prices <- etf_ticker_sector %>%
tq_get(get = "stock.prices") %>%
group_by(ticker, sector)
# Transform to period returns
etf_returns_bizsci <- prices %>%
tq_transform(ohlc_fun = Cl, transform_fun = periodReturn,
period = 'weekly', type = 'log')
head(etf_returns_bizsci)
## Source: local data frame [6 x 4]
## Groups: ticker, sector [1]
##
## ticker sector date weekly.returns
## <chr> <chr> <date> <dbl>
## 1 XLY Consumer Discretionary 2007-01-05 -0.007034027
## 2 XLY Consumer Discretionary 2007-01-12 0.026062578
## 3 XLY Consumer Discretionary 2007-01-19 0.008875499
## 4 XLY Consumer Discretionary 2007-01-26 -0.019888442
## 5 XLY Consumer Discretionary 2007-02-02 0.022409825
## 6 XLY Consumer Discretionary 2007-02-09 -0.006315545
It’s that easy! No need for do.call(), lapply(), or any special functions! It’s all been taken care of for you. Grouping by ticker (and sector to keep the column) allows us to perform the transform on each group separately, but with one line of code. Also, notice that the data is preserved in a tidy format, as opposed to the xts format that RViews uses.
Additionally, RViews intends to create a flexdashboard from their notebook:
…this Notebook will be the first step toward an flexdashboard that lets us do more interactive exploration – choosing different sector ETFs and rolling windows
-Jonathan Regenstein, RStudio
It would be easy to now create a function wrapping the process like RViews did, allowing the user to just enter the tibble of tickers. This could be useful in the flexdashboard that they will create, but for this post, we chose not do to that.
Rolling Correlations
The next step is to calculate rolling correlations between the SP500 index (“SPY”) ETF returns and the sector-specific ETF returns.
RViews
Here’s how RViews solved this problem in two steps.
Step 1: Create a Sector Index Correlation Function
A function is a nice approach, but the downside is it only works for one component unless you use the purrr package to map the function. A special function was again created to merge the sector and SPY returns and then apply the rolling correlation using rollapply() with another special function. Very well done, but complicated.
# A function that calculates the rolling correlation between a sector ETF and the SPY SP500 ETF.
sector_index_correlation <- function(x, window) {
# Make one xts object to hold the sector returns and the SPY returns
merged_xts <- merge(x, etf_returns_rviews$'Index')
# Use rollapply() to calculate the rolling correlations.
# See what happens if you remove the 'pairwise.complete.obs' argument - the NAs will cause problems.
merged_xts$rolling_cor <- rollapply(merged_xts, window,
function(x) cor(x[,1], x[,2], use = "pairwise.complete.obs"),
by.column = FALSE)
names(merged_xts) <- c("Sector Returns", "SPY Returns", "Sector/SPY Correlation")
merged_xts
}
Step 2: Apply the function to the data
RViews applies the special function across the “Information Technology” ETF only. Again, purrr is needed to map across all ETF’s if desired, which is an additional step.
# Choose a sector ETF and a rolling window and pass them to the function we just build.
# Let's go with a 5 month window and the Information Technology sector.
# We will now have a new xts object with 3 time series: sector returns, SPY returns
# and the rolling correlation between those return series.
IT_SPY_correlation <- sector_index_correlation(etf_returns_rviews$'Information Technology', 20)
# Have a peek. The first 20 rows in the correlation column should be
# NAs.
head(IT_SPY_correlation, n = 25)
## Sector Returns SPY Returns Sector/SPY Correlation
## 2007-01-05 0.007260335 -0.0058884356 NA
## 2007-01-12 0.021886396 0.0190294841 NA
## 2007-01-19 -0.027005903 -0.0029364349 NA
## 2007-01-26 -0.001283929 -0.0048429782 NA
## 2007-02-02 0.016985546 0.0186803576 NA
## 2007-02-09 -0.008881386 -0.0060259646 NA
## 2007-02-16 0.015177315 0.0123590071 NA
## 2007-02-23 0.003341691 -0.0029549759 NA
## 2007-03-02 -0.057501940 -0.0467035959 NA
## 2007-03-09 0.015776007 0.0151013857 NA
## 2007-03-16 -0.002176236 -0.0161114796 NA
## 2007-03-23 0.026656737 0.0344812823 NA
## 2007-03-30 -0.010663355 -0.0097411262 NA
## 2007-04-05 0.022892097 0.0156515560 NA
## 2007-04-13 0.001256461 0.0074596420 NA
## 2007-04-20 0.014131615 0.0224544236 NA
## 2007-04-27 0.015561370 0.0061043558 NA
## 2007-05-04 0.016122840 0.0092528469 NA
## 2007-05-11 0.007171385 -0.0003976208 NA
## 2007-05-18 0.004752405 0.0115988780 0.8820099
## 2007-05-25 -0.004752405 -0.0061121613 0.8963962
## 2007-06-01 0.018096442 0.0156329832 0.8946237
## 2007-06-08 -0.012159397 -0.0199273050 0.9301269
## 2007-06-15 0.017214861 0.0133507228 0.9311254
## 2007-06-22 -0.009744766 -0.0166001040 0.9302817
BizSci
And, here’s how we solved it using tidyquant.
Step 1: Merge SPY ETF Weekly Returns with Sector ETF Weekly Returns
First, we add the weekly returns for the “SPY” index (which is currently the last group in the tibble) as it’s own column. This is what our correlations will be calculated against. To do this, we will have to isolate that “SPY” data, and merge it with the original data. The easiest way is to filter() the “SPY” weekly returns and then join (inner_join()) as a new column using by = "date" as the merge key.
# Isolate SPY
index <- etf_returns_bizsci %>%
ungroup() %>%
filter(ticker == "SPY") %>%
select(date, weekly.returns) %>%
rename(index.returns = weekly.returns)
# Join on date
etf_returns_bizsci_joined <- inner_join(etf_returns_bizsci, index, by = "date")
head(etf_returns_bizsci_joined)
## Source: local data frame [6 x 5]
## Groups: ticker, sector [1]
##
## ticker sector date weekly.returns
## <chr> <chr> <date> <dbl>
## 1 XLY Consumer Discretionary 2007-01-05 -0.007034027
## 2 XLY Consumer Discretionary 2007-01-12 0.026062578
## 3 XLY Consumer Discretionary 2007-01-19 0.008875499
## 4 XLY Consumer Discretionary 2007-01-26 -0.019888442
## 5 XLY Consumer Discretionary 2007-02-02 0.022409825
## 6 XLY Consumer Discretionary 2007-02-09 -0.006315545
## index.returns
## <dbl>
## 1 -0.005888436
## 2 0.019029484
## 3 -0.002936435
## 4 -0.004842978
## 5 0.018680358
## 6 -0.006025965
Step 2: Use tq_mutate_xy() to apply runCor()
Now what? RViews used the more generic rollapply() function, and then created the function for correlations. While this is definitely possible using tq_mutate, it’s easier to just use the runCor() function from the TTR package through tq_mutate_xy() instead. If you are new to tidyquant, the mutate functions will do exactly what we need:
-
tq_mutate() aggregates the functions from quantmod, xts, zoo, and TTR using OHLCV style data and notation. It accepts ohlc_fun and mutate_fun to apply a function to OHLCV inputs. We don’t use this version because it can’t accept non-OHLC data or apply functions that require two primary arguments.
-
tq_mutate_xy() works with functions from quantmod, xts, zoo, and TTR packages that require two arguments (x and y). It’s also used when you have data that is not in OHLCV format. Here, we face both situations. It accepts x, y, and mutate_fun args, which handles our situation perfectly!
The usage of runCor by itself looks like: runCor(x, y, n = 10) so we will use tq_mutate_xy() to pass in the x and y arguments, and then pass through n = 20 using the .... As an aside, you may be wondering what the col_rename argument is. Simply put it renames the mutation output, which is surprisingly handy by eliminating one extra line of code.
# Get running correlations
etf_returns_runCor_bizsci <- etf_returns_bizsci_joined %>%
tq_mutate_xy(x = weekly.returns, y = index.returns,
mutate_fun = runCor, n = 20, col_rename = "cor")
# Isolate Information Technology, and get past the NA's for our viewing pleasure
etf_returns_runCor_bizsci %>%
filter(sector == "Information Technology") %>%
slice(20:n())
## Source: local data frame [508 x 6]
## Groups: ticker, sector [1]
##
## ticker sector date weekly.returns
## <chr> <chr> <date> <dbl>
## 1 XLK Information Technology 2007-05-18 0.004752405
## 2 XLK Information Technology 2007-05-25 -0.004752405
## 3 XLK Information Technology 2007-06-01 0.018096442
## 4 XLK Information Technology 2007-06-08 -0.012159397
## 5 XLK Information Technology 2007-06-15 0.017214861
## 6 XLK Information Technology 2007-06-22 -0.009744766
## 7 XLK Information Technology 2007-06-29 0.002738081
## 8 XLK Information Technology 2007-07-06 0.021256839
## 9 XLK Information Technology 2007-07-13 0.018939960
## 10 XLK Information Technology 2007-07-20 0.005612700
## index.returns cor
## <dbl> <dbl>
## 1 0.0115988780 0.8820099
## 2 -0.0061121613 0.8963962
## 3 0.0156329832 0.8946237
## 4 -0.0199273050 0.9301269
## 5 0.0133507228 0.9311254
## 6 -0.0166001040 0.9302817
## 7 -0.0007974617 0.9303941
## 8 0.0168093546 0.9315747
## 9 0.0121497774 0.9328206
## 10 -0.0087563781 0.8887265
## # ... with 498 more rows
There’s an added bonus…
As opposed to the RViews function, we actually calculated the rolling correlations for all of the ETF groups in the tibble, not just the one that you pass in! This is typically desired because the user is usually interested in understanding how all groups within a data set correlate to a baseline as opposed to just one.
Dygraph
Finally, let’s recreate the Dygraph for the “Information Technology” sector. Dygraphs take an xts object as input, which is NOT the format we are in currently (we are in tibble format). The most useful function here is as_xts(), a tidyquant function that provides an easy way to convert from tibbles to xts. Selecting just the “date” and “cor” columns from the input and specifying the date_col = date in as_xts() allows us to use the same code as RViews to create the Dygraph.
etf_returns_runCor_bizsci %>%
ungroup() %>%
filter(sector == "Information Technology") %>%
select(date, cor) %>%
as_xts(date_col = date) %>%
dygraph(main = "Correlation between SP500 and Tech ETF") %>%
dyAxis("y", label = "Correlation") %>%
dyRangeSelector(height = 20) %>%
# Add shading for the recessionary period
dyShading(from = "2007-12-01", to = "2009-06-01", color = "#FFE6E6") %>%
# Add an event for the financial crisis.
dyEvent(x = "2008-09-15", label = "Fin Crisis", labelLoc = "top", color = "red")
And that’s it! Hopefully you have seen that tidyquant is a great way to streamline and even scale your financial analysis workflow. And, we have only scratched the surface of what it can do! You can check out the stable release of tidyquant from CRAN, and the development release from Github. Stay tuned for more to come!