tidyquant Integrates Quandl: Getting Data Just Got Easier
Written by Matt Dancho
Today I’m very pleased to introduce the new Quandl API integration that is available in the development version of tidyquant. Normally I’d introduce this feature during the next CRAN release (v0.5.0 coming soon), but it’s really useful and honestly I just couldn’t wait. If you’re unfamiliar with Quandl, it’s amazing: it’s a web service that has partnered with top-tier data publishers to enable users to retrieve a wide range of financial and economic data sets, many of which are FREE! Quandl has it’s own R package (aptly named Quandl) that is overall very good but has one minor inconvenience: it doesn’t return multiple data sets in a “tidy” format. This slight inconvenience has been addressed in the integration that comes packaged in the latest development version of tidyquant. Now users can use the Quandl API from within tidyquant with three functions: quandl_api_key(), quandl_search(), and the core function tq_get(get = "quandl"). In this post, we’ll go through a user-contributed example, How To Perform a Fama French 3 Factor Analysis, that showcases how the Quandl integration fits into the “Collect, Modify, Analyze” financial analysis workflow. Interested readers can download the development version using devtools::install_github("business-science/tidyquant"). More information is available on the tidyquant GitHub page including the updated development vignettes.
Table of Contents
Overview
tidyquant: Bringing financial analysis to the tidyverse
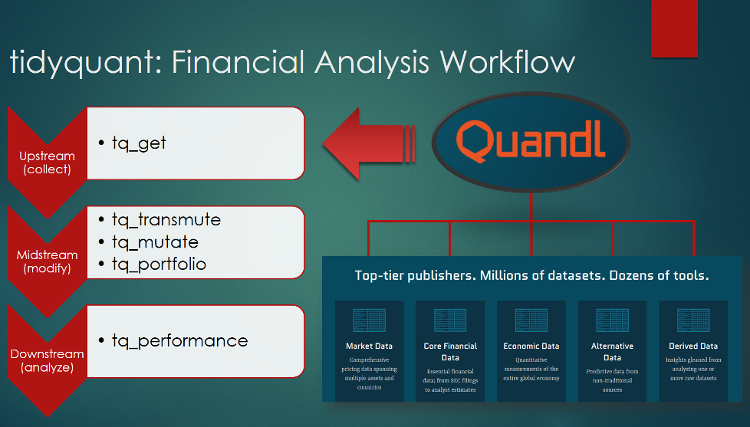
The topic for today is the Quandl integration today. Quandl enables access to a wide range of financial and economic data. It has it’s own R library appropriately named Quandl. Users can sign up for a FREE account, and in return users get an API key that enables access to numerous free and paid data sets. The Quandl package is very good: it enables searching the Quandl databases from the R console. Once a data set is found, the data set “code” can be used to retrieve the data in various formats. The one downside is that, although you can get multiple data sets (e.g. for multiple stocks, FRED codes, etc), the data returned is not “tidy”. This is where the tidyquant integration fits in. The integration makes it even more convenient to get data, and when multiple data sets are retrieved they are returned in one “tidy” data frame (aka “long” format which is perfect for grouping and scaling analysis)! In addition, you only need to load one package, tidyquant, to get the full capabilities of the Quandl API. The figure below shows how Quandl fits into the “Collect, Modify, Analyze” tidyquant financial analysis workflow.
If you are new to tidyquant, there’s a few core functions that you need to be aware of. I’ve broken them down by step in the CMA process.
-
Upstream (Collect): tq_get() is a one-stop shop for getting web-based financial data in a “tidy” data frame format. Get data for daily stock prices (historical), key statistics (real-time), key ratios (historical), financial statements, economic data from the FRED, FOREX rates from Oanda, and now Quandl!
- Midstream (Modify):
tq_transmute() and tq_mutate() manipulate financial data. tq_mutate() is used to add a column to the data frame. tq_transmute() is used to return a new data frame which is necessary for periodicity changes.tq_portfolio() aggregates a group (or multiple groups) of asset returns into one or more portfolios.
- Downstream (Analyze):
tq_performance() integrates PerformanceAnalytics functions that turn investment returns into performance metrics.
To learn more about the functions, browse the Development Vignettes on GitHub.
Prerequisites
To use the Quandl integration and other new tidyquant features, you’ll need to install the development version available on the Business Science GitHub Site. You can download with devtools.
devtools::install_github("business-science/tidyquant")
Next, load tidyquant, broom and corrr packages. The broom and corrr packages will help in our analysis at the end of the financial analysis workflow.
# Loads tidyquant, tidyverse, lubridate, quantmod, TTR, xts, zoo, PerformanceAnalytics
library(tidyquant)
library(broom) # Use `tidy` and `glance` functions
library(corrr) # tidy correlations
I also recommend the open-source RStudio IDE, which makes R Programming easy and efficient especially for financial analysis. Now, onto a really neat example showing off why Quandl is such a great tool.
Before we get started, I’d like to thank Bob Rietveld for the usage case. He’s been doing a lot of work with Fama French three and five factor models. You can find an example of his FF analyses here. In this example, we’ll perform a Fama French three factor regression on a portfolio of the following stocks: 20% AAPL, 20% F, 40% GE, and 20% MSFT. According to Investopedia:
The Fama and French Three Factor Model is an asset pricing model that expands on the capital asset pricing model (CAPM) by adding size and value factors to the market risk factor in CAPM. This model considers the fact that value and small-cap stocks outperform markets on a regular basis. By including these two additional factors, the model adjusts for the out-performance tendency, which is thought to make it a better tool for evaluating manager performance.
The CMA process steps we’ll implement are as follows:
- Collect Data: We’ll use the new Quandl integration to get both stock prices and Fama French data sets.
- Modify Data: This is a portfolio analysis so we’ll need to aggregate stock returns into a weighted portfolio
- Analyze Data: We’ll perform a regression analysis, and we need the
broom package for the tidy() and glance() functions.
Step 1: Collect Data
In this step, we will collect two data frames. The first is the historical stock returns for individual stocks. The second is the Fama French three factor data set. We are going to use the Quandl API integration so first set your API key using quandl_api_key(). If you don’t have an API key yet, you can sign up with Quandl.
quandl_api_key("your-api-key-here")
Collecting Historical Stock Returns
Next, let’s create a table of stocks. We will use the “WIKI” database which returns open, high low, close, volume, dividends, splits, and adjusted prices. The Quandl data sets use the following code format: “Database” / “Data Set”. For “AAPL”, this would be “WIKI/AAPL” indicating the WIKI database and AAPL data set. The code in the first column will allow us to pipe (%>%) the stock list to the tq_get() function next.
stock_list_quandl <- tribble(
~code, ~symbol,
"WIKI/AAPL", "AAPL",
"WIKI/F", "F",
"WIKI/GE", "GE",
"WIKI/MSFT", "MSFT"
)
stock_list_quandl
## # A tibble: 4 × 2
## code symbol
## <chr> <chr>
## 1 WIKI/AAPL AAPL
## 2 WIKI/F F
## 3 WIKI/GE GE
## 4 WIKI/MSFT MSFT
Once we have the stocks, we can very easily use tq_get(get = "quandl") to get stock prices and even stock returns depending on the options we use. The following time series options are available to be passed to the underlying Quandl::Quandl()function:
order = “asc”, “desc”start_date (from) = “yyyy-mm-dd”end_date (to) = “yyyy-mm-dd”column_index = numeric column number (e.g. 1)rows = numeric row number indicating first n rows (e.g. 100)collapse = “none”, “daily”, “weekly”, “monthly”, “quarterly”, “annual”transform = “none”, “diff”, “rdiff”, “cumul”, “normalize”
We’ll use from and to to select a ten year time period from the beginning of 2007 through the end of 2016, transform = "rdiff" to get percentage returns, collapse = "monthly" to get monthly data, and column_index = 11 to get the eleventh column, “adj.close”. We’ll rename the column from “adj.close” to “monthly.returns” to accurately describe the values.
stock_returns_quandl <- stock_list_quandl %>%
tq_get(get = "quandl",
from = "2007-01-01",
to = "2016-12-31",
transform = "rdiff",
collapse = "monthly",
column_index = 11) %>%
rename(monthly.returns = adj.close)
stock_returns_quandl
## # A tibble: 476 × 4
## code symbol date monthly.returns
## <chr> <chr> <date> <dbl>
## 1 WIKI/AAPL AAPL 2016-12-31 0.047468354
## 2 WIKI/AAPL AAPL 2016-11-30 -0.025893958
## 3 WIKI/AAPL AAPL 2016-10-31 0.005045587
## 4 WIKI/AAPL AAPL 2016-09-30 0.064750236
## 5 WIKI/AAPL AAPL 2016-08-31 0.023618063
## 6 WIKI/AAPL AAPL 2016-07-31 0.090062762
## 7 WIKI/AAPL AAPL 2016-06-30 -0.042659724
## 8 WIKI/AAPL AAPL 2016-05-31 0.071799336
## 9 WIKI/AAPL AAPL 2016-04-30 -0.139921094
## 10 WIKI/AAPL AAPL 2016-03-31 0.127210673
## # ... with 466 more rows
Collecting Fama French 3-Factor Monthly Data
Next, we need to get the Fama French data. Suppose we don’t know exactly what we are looking for. We’ll use the function, quandl_search(), to query the Quandl API (a wrapper for Quandl.search()). We can search within the R console by setting query to a descriptive value. We’ll set per_page = 5 to get the top 5 results. We’ll set silent = TRUE to turn off the meta data output (in practice it may be beneficial to leave this easy-to-read option on). The results returned contain the “id”, dataset_code, “database_code”, “name”, “description”, etc, which gives us both insight into the data set contents and the information needed to retrieve. I’ve removed “description” to make it easier to view the information.
quandl_search(query = "FAMA FRENCH", per_page = 5, silent = TRUE) %>%
select(-description)
| id |
dataset_code |
database_code |
name |
refreshed_at |
newest_available_date |
oldest_available_date |
column_names |
frequency |
type |
premium |
database_id |
| 30216128 |
MOMENTUM_A |
KFRENCH |
Fama/French Factors (Annual) |
2017-03-18T21:08:12.712Z |
2016-12-31 |
1927-12-31 |
Date, Momentum |
annual |
Time Series |
FALSE |
389 |
| 30579533 |
FACTORS_A |
KFRENCH |
Fama/French Factors (Annual) |
2017-03-18T21:06:21.885Z |
2016-12-31 |
1927-12-31 |
Date, Mkt-RF, SMB, HML, RF |
annual |
Time Series |
FALSE |
389 |
| 2292156 |
FACTORS_M |
KFRENCH |
Fama/French Factors (Monthly) |
2017-03-18T21:06:21.953Z |
2017-01-31 |
1926-07-31 |
Date, Mkt-RF, SMB, HML, RF |
monthly |
Time Series |
FALSE |
389 |
| 2292158 |
FACTORS_W |
KFRENCH |
Fama/French Factors (Weekly) |
2017-03-18T21:06:25.103Z |
2017-01-27 |
1926-07-02 |
Date, Mkt-RF, SMB, HML, RF |
weekly |
Time Series |
FALSE |
389 |
| 2676225 |
MOMENTUM_M |
KFRENCH |
Fama/French Factors (Monthly) |
2017-03-18T21:08:12.746Z |
2017-01-31 |
1927-01-31 |
Date, Momentum |
monthly |
Time Series |
FALSE |
389 |
The third result, “FACTORS_M”, is what we need. We can retrieve with tq_get(get = "quandl") by piping (%>%) "KFRENCH/FACTORS_M". (Remember that the format is always database code / dataset code). We’ll tack on collapse = "monthly" to ensure the dates match up with the returns, stock_returns_quandl.
# Get Fama French 3 Factor Data
fama_french_3_M <- "KFRENCH/FACTORS_M" %>%
tq_get(get = "quandl",
collapse = "monthly")
fama_french_3_M
## # A tibble: 1,087 × 5
## date mkt.rf smb hml rf
## <date> <dbl> <dbl> <dbl> <dbl>
## 1 2017-01-31 1.94 -0.95 -2.76 0.04
## 2 2016-12-31 1.81 -0.04 3.52 0.03
## 3 2016-11-30 4.86 5.68 8.44 0.01
## 4 2016-10-31 -2.02 -4.41 4.15 0.02
## 5 2016-09-30 0.25 2.00 -1.34 0.02
## 6 2016-08-31 0.50 0.94 3.18 0.02
## 7 2016-07-31 3.95 2.90 -0.98 0.02
## 8 2016-06-30 -0.05 0.61 -1.49 0.02
## 9 2016-05-31 1.78 -0.27 -1.79 0.01
## 10 2016-04-30 0.92 0.68 3.25 0.01
## # ... with 1,077 more rows
Now we have all of the data needed. We are ready to move on to modifying the data.
Step 2: Modify Data
There’s two parts to this step. First, we will aggregate the portfolio in the weights specified in the beginning of the example:
- 20% AAPL, 20% F, 40% GE, and 20% MSFT.
Second, we will join the aggregated portfolio returns with the Fama French data.
Aggregate Portfolio
Portfolio aggregation is performed using tq_portfolio() as follows. We create a tibble (“tidy” data frame) of weights that can be mapped using the first column, “stocks”.
# Creating tibble of stock weights that can be mapped to the portfolio assets
weights_tib <- tibble(stocks = c("AAPL", "F", "GE", "MSFT"),
weights = c(0.2, 0.2, 0.4, 0.2))
weights_tib
## # A tibble: 4 × 2
## stocks weights
## <chr> <dbl>
## 1 AAPL 0.2
## 2 F 0.2
## 3 GE 0.4
## 4 MSFT 0.2
Then we pass the individual stock returns, stock_returns_quandl, to the tq_portfolio() function specifying the assets column “symbol” and the returns column “monthly.returns”. The weights_tib tibble is also passed to the weights argument. Note that there is also an argument, rebalance_on = c(NA, "years", "quarters", "months", "weeks", "days") if rebalancing is a consideration to factor into the model. Last, the output column is renamed to “monthly.returns” using the col_rename argument.
# Aggregating weighted portfolio returns
portfolio_returns <- stock_returns_quandl %>%
tq_portfolio(assets_col = symbol,
returns_col = monthly.returns,
weights = weights_tib,
rebalance_on = NA,
col_rename = "monthly.returns")
portfolio_returns
## # A tibble: 119 × 2
## date monthly.returns
## <date> <dbl>
## 1 2007-02-28 -0.034414463
## 2 2007-03-31 0.022735121
## 3 2007-04-30 0.050631578
## 4 2007-05-31 0.068295584
## 5 2007-06-30 0.028425228
## 6 2007-07-31 0.002249988
## 7 2007-08-31 -0.001170495
## 8 2007-09-30 0.077241302
## 9 2007-10-31 0.113769305
## 10 2007-11-30 -0.076217903
## # ... with 109 more rows
Join Portfolio Returns and Fama French Data
We can join the two data sets by the “date” column in each using left_join from the dplyr package.
portfolio_fama_french <- left_join(portfolio_returns, fama_french_3_M, by = "date")
portfolio_fama_french
## # A tibble: 119 × 6
## date monthly.returns mkt.rf smb hml rf
## <date> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2007-02-28 -0.034414463 -1.96 1.32 -0.10 0.38
## 2 2007-03-31 0.022735121 0.68 -0.06 -0.23 0.43
## 3 2007-04-30 0.050631578 3.49 -2.07 -1.15 0.44
## 4 2007-05-31 0.068295584 3.24 -0.01 -0.07 0.41
## 5 2007-06-30 0.028425228 -1.96 0.79 -1.11 0.40
## 6 2007-07-31 0.002249988 -3.73 -2.50 -3.34 0.40
## 7 2007-08-31 -0.001170495 0.92 -0.10 -2.25 0.42
## 8 2007-09-30 0.077241302 3.22 -2.28 -1.91 0.32
## 9 2007-10-31 0.113769305 1.80 0.22 -2.62 0.32
## 10 2007-11-30 -0.076217903 -4.83 -2.61 -1.18 0.34
## # ... with 109 more rows
Now we are ready to analyze.
Step 3: Anaylze Data
In the final step we will analyze two ways. First, we will perform the three factor regression, which yields model parameters. Second, we will review visually by plotting a correlation matrix.
Three Factor Regression Model
The article, “Rolling Your Own: Three-Factor Analysis”, by William J. Bernstein with Efficient Frontier goes through an excellent step-by-step explaining the method. We are concerned with the following variables:
- Return of the Total Market minus the T-Bill return (mkt.rf): The return of the total market (CRSP 1-10) minus the T-bill return (Mkt)
- Small Minus Big (smb): The return of small company stocks minus that of big company stocks
- High Minus Low (hml): The return of the cheapest third of stocks sorted by price/book minus the most expensive third
Three factor regression is performed with the lm() function by analyzing the relationship between the portfolio returns and the three FF factors.
ff_3 <- lm(monthly.returns ~ mkt.rf + smb + hml, data = portfolio_fama_french)
Using glance from the broom package, we can review the regression metrics. Note kable() from the knitr package is used to create aesthetically pleasing tables. We can see from the “r.squared” value that 67% of the variance of the portfolio returns is explained by the model.
glance(ff_3) %>%
knitr::kable()
| r.squared |
adj.r.squared |
sigma |
statistic |
p.value |
df |
logLik |
AIC |
BIC |
deviance |
df.residual |
| 0.6709785 |
0.6623953 |
0.0424483 |
78.17375 |
0 |
4 |
209.1576 |
-408.3151 |
-394.4195 |
0.2072133 |
115 |
Using tidy from the broom package, we can review the model coefficients: these are the most interesting. The intercept is the alpha, and at 0.005 the portfolio is outperforming the model by approximately 0.005% per month or roughly 0.055% per year (although the p-value indicates this is not statistically significant). Next are the “loadings” for the three factors. The “mkt.rf” is the beta for the portfolio, which indicates very low volatility compared to the market (anything less than 1.0 means lower volatility than the market). The “smb” value of essentially zero signifies large-cap (anything below 0 is large cap, above 0.5 is small cap). The “hml” value of essentially zero signifies a growth fund (a zero value defines a growth portfolio, a value of more than 0.3, a value fund).
tidy(ff_3) %>%
knitr::kable()
| term |
estimate |
std.error |
statistic |
p.value |
| (Intercept) |
0.0046336 |
0.0039400 |
1.1760314 |
0.2420111 |
| mkt.rf |
0.0138197 |
0.0009619 |
14.3665066 |
0.0000000 |
| smb |
-0.0027443 |
0.0018407 |
-1.4909358 |
0.1387162 |
| hml |
-0.0013105 |
0.0014951 |
-0.8765756 |
0.3825446 |
Visualize Correlations
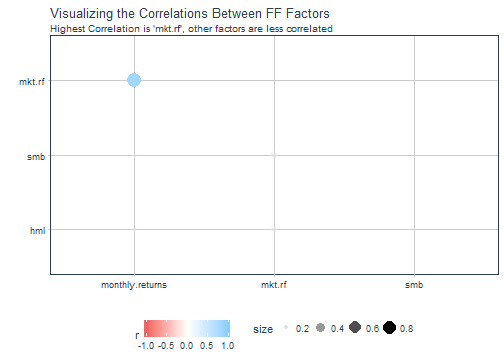
We can also visualize the results using the new corrr package to get a sense of the relationship the portfolio returns to each of the factors. The correlate() function creates a correlation matrix. The shave() function removes the upper diagonal.
portfolio_corr <- portfolio_fama_french %>%
select(-c(date, rf)) %>%
correlate() %>%
shave()
# `fashion` used for pretty printing
fashion(portfolio_corr) %>%
knitr::kable()
| rowname |
monthly.returns |
mkt.rf |
smb |
hml |
| monthly.returns |
|
|
|
|
| mkt.rf |
.81 |
|
|
|
| smb |
.22 |
.36 |
|
|
| hml |
.22 |
.33 |
.19 |
|
Visualizing is just one more step with rplot() (similar to ggplot() + correlation geom). We can see that the market reference is highly correlated to the monthly portfolio returns, but this is the only value that has a significant correlation.
portfolio_corr %>%
rplot() +
labs(title = "Visualizing the Correlations Between FF Factors",
subtitle = "Highest Correlation is 'mkt.rf', other factors are less correlated") +
theme_tq()
Conclusions
The new Quandl integration opens up a lot of doors with regards to financial and economic data. The API is now integrated into the “tidyverse” workflow enabling scaling and easy data manipulations following the “Collect, Modify, Analyze” financial analysis workflow we use with tidyquant. The Fama French analysis is just one example of new and interesting analyses that are now easily performed. This is just the beginning. Feel free to email us at Business Science with new and interesting ways you are using tidyquant!
Recap
We covered a lot of ground today. We exposed you to the new Quandl integration and how it fits within the “Collect, Modify, Analyze” financial analysis workflow. We used quandl_api_key() to set an API key, enabling access to the Quandl API. We used quandl_search() to search the Quandl API for Fama French data. We used tq_get(get = "quandl") to retrieve data from Quandl, passing various options to conveniently get monthly returns. We aggregated a portfolio using tq_portfolio and joined the portfolio returns with the Fama French data. We then performed a basic Fama French Three Factor analysis. The entire analysis from beginning to end was easy, efficient, and “tidy”! =)
Further Reading
-
TQ01-Core Functions in tidyquant, Development Version: The Core Functions in tidyquant vignette (development version) has a nice section on the features related to the Quandl integration!
-
R for Data Science: A free book that thoroughly covers the “tidyverse”. A prerequisite for maximizing your abilities with tidyquant.