Speed Up Your Code Part 2: Parallel Processing Financial Data with multidplyr + tidyquant
Written
Since my initial post on parallel processing with multidplyr, there have been some recent changes in the tidy eco-system: namely the package tidyquant, which brings financial analysis to the tidyverse. The tidyquant package drastically increase the amount of tidy financial data we have access to and reduces the amount of code needed to get financial data into the tidy format. The multidplyr package adds parallel processing capability to improve the speed at which analysis can be scaled. I seriously think these two packages were made for each other. I’ll go through the same example used previously, updated with the new tidyquant functionality.
Table of Contents
Parallel Processing Applications in Financial Analysis
Collecting financial data in tidy format was overly difficult. Getting from xts to tibble was a pain, and there’s some amazing tidyverse functionality that cannot be used without the tibble (tidy data frame) format. That all changed with tidyquant. There’s a wide range of free data sources, and the tidyquant package makes it super simple to get financial and economic data in tidy format (more on this in a minute).
There’s one caveat to collecting data at scale: it takes time. Getting data from the internet, historical stock prices or financial statements or real-time statistics, for 500+ stocks can take anywhere from several minutes to 20+ minutes depending on the data size and number of stocks. tidyquant makes it easier to get and analyze data in the correct format, but we need a new tool to speed up the process. Enter multidplyr.
The multidplyr package makes it super simple to parallelize code. It works perfectly in the tidyverse, and, by the associative propery, works perfectly with tidyquant.
The example in this post shows off the new tq_get() function for getting stock prices at scale. However, we can get and scale much more than just stock prices. tq_get has the following data retrieval options:
-
get = "stock.index": This retrieves the entire list of stocks in an index. 18 indexes are available. Use tq_get_stock_index_options() to see the full list.
-
get = "stock.prices": This retrieves historical stock prices over a time period specified by to and from. This is the default option, and the one we use in this post.
-
get = "key.ratios": This retrieves the key ratios from Morningstar, which are historical values over the past 10-years. There are 89 key ratios ranging from valuation, to growth and profitability, to efficiency. This is a great place to chart business performance over time and to compare the key ratios by company. Great for financial analysis!
-
get = "key.stats": This retrieves real-time key stats from Yahoo Finance, which consist of bid, ask, day’s high, day’s low, change, current P/E valuation, current Market Cap, and many more up-to-the-minute stats on a stock. This is a great place for the day trader to work since all of the data is accurate as of the second you download it.
-
get = "financials": This retrieves the annual and quarterly financial statement data from Google Finance. Great for financial analysis!
-
get = "economic.data": This retrieves economic data from the FRED database by FRED code. As of the blog post date, there are 429,000 US and international time-series data sets from 80 sources. All you need is the FRED symbol such as “CPIAUCSL” for CPI. Vist the FRED website to learn more.
-
Other get options: "metal.prices", "exchange.rates", "dividends", and "splits". There’s lots of data you can get using tq_get!
The point I want to make is that ANY OF THESE GET OPTIONS CAN BE SCALED USING THE PROCESS I USE NEXT!!!
Prerequisites
The multidplyr package is not available on CRAN, but you can install it using devtools. Also, install the development version of tidyquant which has added functionality that will be available on CRAN soon with v0.3.0.
install.packages("devtools")
devtools::install_github("hadley/multidplyr")
devtools::install_github("mdancho84/tidyquant")
For those following along in R, you’ll need to load the following packages:
library(multidplyr) # parallel processing
library(tidyquant) # tidy financial analysis :)
I also recommend the open-source RStudio IDE, which makes R Programming easy and efficient.
Workflow
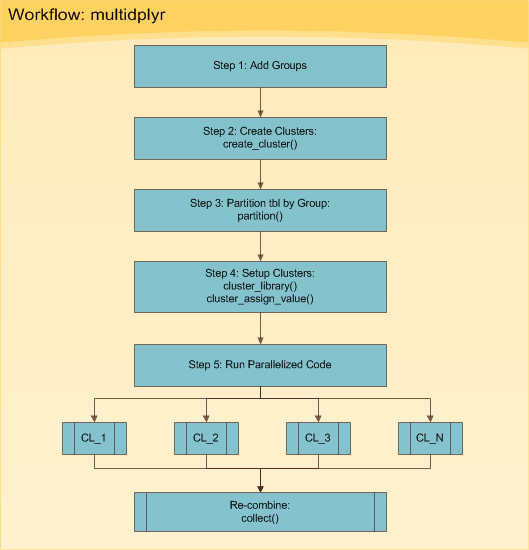
The multidplyr workflow can be broken down into five basic steps shown in Figure 1. The five steps are implemented in Processing in Parallel.
Figure 1: multidplyr Workflow
Essentially, you start with some data set that you need to do things to multiple times. Your situation generally falls into one of two types:
- It could be a really large data set that you want to split up into several small data sets and perform the same thing on each.
- It could be one data set that you want to perform multiple things on (e.g. apply many models).
The good news is both situations follow the same basic workflow. The toughest part is getting your data in the format needed to process using the workflow. Don’t worry, we’ll go through a real world example shortly so you can see how this is accomplished.
Real World Example
We’ll go through the multidplyr workflow using a real world example that I routinely use: collecting stock prices from the inter-web. Other uses include using modeling functions over grouped data sets, using many models on the same data set, and processing text (e.g. getting n-grams on large corpora). Basically anything with a loop.
Prep-Work
In preparation for collecting stock prices, we need two things:
- A list of stocks
- A function to get stock prices from a stock symbol
Let’s see how tidyquant makes this easy. First, getting a stock index used to be a pain:
Before tidyquant (Don’t use this):
library(rvest)
# Web-scrape SP500 stock list from Wikipedia
sp_500 <- read_html("https://en.wikipedia.org/wiki/List_of_S%26P_500_companies") %>%
html_node("table.wikitable") %>%
html_table() %>%
select(`Ticker symbol`, Security) %>%
as_tibble() %>%
rename(symbol = `Ticker symbol`,
company = Security)
# Show results
sp_500
Now with tidyquant (Use this!):
sp_500 <- tq_get("SP500", get = "stock.index")
sp_500
## # A tibble: 501 × 2
## symbol company
## <chr> <chr>
## 1 MMM 3M
## 2 ABT ABBOTT LABORATORIES
## 3 ABBV ABBVIE INC
## 4 ACN ACCENTURE
## 5 ATVI ACTIVISION BLIZZARD
## 6 AYI ACUITY BRANDS
## 7 ADBE ADOBE SYSTEMS
## 8 AAP ADVANCE AUTO PARTS
## 9 AET AETNA
## 10 AMG AFFILIATED MANAGERS GROUP
## # ... with 491 more rows
Second, getting stock prices in tidy format used to be a pain:
Before tidyquant (Don’t use this):
library(quantmod)
# Function to Get Stock Prices in Tidy Form
get_stock_prices <- function(symbol, return_format = "tibble", ...) {
# Get stock prices; Handle errors
stock_prices <- tryCatch({
getSymbols(Symbols = symbol, auto.assign = FALSE, ...)
}, error = function(e) {
return(NA) # Return NA on error
})
if (!is.na(stock_prices[[1]])) {
# Rename
names(stock_prices) <- c("Open", "High", "Low", "Close", "Volume", "Adjusted")
# Return in xts format if tibble is not specified
if (return_format == "tibble") {
stock_prices <- stock_prices %>%
as_tibble() %>%
rownames_to_column(var = "Date") %>%
mutate(Date = ymd(Date))
}
return(stock_prices)
}
}
Now with tidyquant (Use this!):
tq_get("AAPL", get = "stock.prices")
Note that you can replace "stock.prices" with "key.ratios", "key.stats", "financials", etc to get other financial data for a stock symbol. These options can be scaled as well!
Processing In Series
The next computation is the routine that we wish to parallelize, but first we’ll time the script running on one processor, looping in series. We are collecting ten years of historical daily stock prices for each of the 500+ stocks. This is now a simple chaining operation with tidyquant, which accepts a tibble of stocks with the symbols in the first column.
# Map get_stock_prices() to list of stock symbols
from <- "2007-01-01"
to <- today()
# Series
start <- proc.time() # Start clock
sp_500 %>%
tq_get(get = "stock.prices", from = from, to = to)
time_elapsed_series <- proc.time() - start # End clock
The result, sp_500_processed_in_series is a tibble (tidy data frame) with the stock prices for the 500+ stocks.
sp_500_processed_in_series
## # A tibble: 1,209,822 × 9
## symbol company date open high low close volume adjusted
## <chr> <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 MMM 3M 2007-01-03 77.53 78.85 77.38 78.26 3781500 60.31064
## 2 MMM 3M 2007-01-04 78.40 78.41 77.45 77.95 2968400 60.07174
## 3 MMM 3M 2007-01-05 77.89 77.90 77.01 77.42 2765200 59.66330
## 4 MMM 3M 2007-01-08 77.42 78.04 76.97 77.59 2434500 59.79431
## 5 MMM 3M 2007-01-09 78.00 78.23 77.44 77.68 1896800 59.86367
## 6 MMM 3M 2007-01-10 77.31 77.96 77.04 77.85 1787500 59.99468
## 7 MMM 3M 2007-01-11 78.05 79.03 77.88 78.65 2372500 60.61120
## 8 MMM 3M 2007-01-12 78.41 79.50 78.22 79.36 2582200 61.15835
## 9 MMM 3M 2007-01-16 79.48 79.62 78.92 79.56 2526600 61.31248
## 10 MMM 3M 2007-01-17 79.33 79.51 78.75 78.91 2711300 60.81156
## # ... with 1,209,812 more rows
And, let’s see how long it took when processing in series. The processing time is the time elapsed in seconds. Converted to minutes this is approximately 3.71 minutes.
time_elapsed_series
## user system elapsed
## 113.62 4.31 222.79
Processing in Parallel
We just collected ten years of daily stock prices for over 500 stocks in about 3.71 minutes. Let’s parallelize the computation to get an improvement. We will follow the six steps shown in Figure 1.
Step 0: Get Number of Cores (Optional)
Prior to starting, you may want to determine how many cores your machine has. An easy way to do this is using parallel::detectCores(). This will be used to determine the number of groups to split the data into in the next set.
library(parallel)
cl <- detectCores()
cl
## [1] 8
Step 1: Add Groups
Let’s add groups to sp_500. The groups are needed to divide the data across your cl number cores. For me, this is 8 cores. We create a group vector, which is a sequential vector of 1:cl (1 to 8) repeated the length of the number of rows in sp_500. We then add the group vector to the sp_500 tibble using the dplyr::bind_cols() function.
group <- rep(1:cl, length.out = nrow(sp_500))
sp_500 <- bind_cols(tibble(group), sp_500)
sp_500
## # A tibble: 501 × 3
## group symbol company
## <int> <chr> <chr>
## 1 1 MMM 3M
## 2 2 ABT ABBOTT LABORATORIES
## 3 3 ABBV ABBVIE INC
## 4 4 ACN ACCENTURE
## 5 5 ATVI ACTIVISION BLIZZARD
## 6 6 AYI ACUITY BRANDS
## 7 7 ADBE ADOBE SYSTEMS
## 8 8 AAP ADVANCE AUTO PARTS
## 9 1 AET AETNA
## 10 2 AMG AFFILIATED MANAGERS GROUP
## # ... with 491 more rows
Step 2: Create Clusters
Use the create_cluster() function from the multidplyr package. Think of a cluster as a work environment on a core. Therefore, the code below establishes a work environment on each of the 8 cores.
cluster <- create_cluster(cores = cl)
cluster
## socket cluster with 8 nodes on host 'localhost'
Step 3: Partition by Group
Next is partitioning. Think of partitioning as sending a subset of the initial tibble to each of the clusters. The result is a partitioned data frame (party_df), which we explore next. Use the partition() function from the multidplyr package to split the sp_500 list by group and send each group to a different cluster.
by_group <- sp_500 %>%
partition(group, cluster = cluster)
by_group
## Source: party_df [501 x 3]
## Groups: group
## Shards: 8 [62--63 rows]
##
## # S3: party_df
## group symbol company
## <int> <chr> <chr>
## 1 7 ADBE ADOBE SYSTEMS
## 2 7 ALK ALASKA AIR GROUP
## 3 7 MO ALTRIA
## 4 7 AWK AMERICAN WATER WORKS
## 5 7 ANTM ANTHEM, INC.
## 6 7 AIZ ASSURANT
## 7 7 AVY AVERY DENNISON
## 8 7 BDX BECTON DICKINSON
## 9 7 BMY BRISTOL-MYERS SQUIBB
## 10 7 CAT CATERPILLAR
## # ... with 491 more rows
The result, by_group, looks similar to our original tibble, but it is a party_df, which is very different. The key is to notice that the there are 8 Shards. Each Shard has between 63 and 64 rows, which evenly splits our data among each shard. Now that our tibble has been partitioned into a party_df, we are ready to move onto setting up the clusters.
Step 4: Setup Clusters
The clusters have a local, bare-bones R work environment, which doesn’t work for the vast majority of cases. Code typically depends on libraries, functions, expressions, variables, and/or data that are not available in base R. Fortunately, there is a way to add these items to the clusters. Let’s see how.
For our computation, we are going to need to add the tidyquant library and our variables to, and from. We do this by using the cluster_library() and cluster_assign_value() functions, respectively.
from <- "2007-01-01"
to <- today()
# Utilize pipe (%>%) to assign libraries, functions, and values to clusters
by_group %>%
# Libraries
cluster_library("tidyquant") %>%
# Load functions/variable
cluster_assign_value("from", from) %>%
cluster_assign_value("to", to)
We can verify that the libraries are loaded using the cluster_eval() function.
cluster_eval(by_group, search())[[1]] # results for first cluster shown only
## [1] ".GlobalEnv" "package:tidyquant" "package:dplyr"
## [4] "package:purrr" "package:readr" "package:tidyr"
## [7] "package:tibble" "package:ggplot2" "package:tidyverse"
## [10] "package:quantmod" "package:TTR" "package:xts"
## [13] "package:zoo" "package:lubridate" "package:stats"
## [16] "package:graphics" "package:grDevices" "package:utils"
## [19] "package:datasets" "package:methods" "Autoloads"
## [22] "package:base"
Step 5: Run Parallelized Code
Now that we have our clusters and partitions set up and everything looks good, we can run the parallelized code. The code chunk is a little bit different than before because we need to use purrr to map tq_get() to each stock symbol:
- Instead of starting with the
sp_500 tibble, we start with the by_group party_df
- This is how we scale with
purrr: We use a combination of dplyr::mutate() and purrr::map() to map our tq_get() function to the stocks.
- We combine the results at the end using the
multidplyr::collect() function. The result is a nested tibble.
- We unnest with
tidyr::unnest() to return the same single-level tibble as before.
- Finally, we use
dplyr::arrange() to arrange the stocks in the same order as previous. The collect() function returns the shards (cluster data groups) binded in whatever group is done first. Typically you’ll want to re-arrange.
start <- proc.time() # Start clock
sp_500_processed_in_parallel <- by_group %>%
mutate(
stock.prices = map(symbol,
function(.x) tq_get(.x,
get = "stock.prices",
from = from,
to = to)
)
) %>%
collect() %>%
unnest() %>%
arrange(symbol)
time_elapsed_parallel <- proc.time() - start # End clock
Let’s check out the results
sp_500_processed_in_parallel
## Source: local data frame [1,209,820 x 10]
## Groups: group [8]
##
## group symbol company date open high low
## <int> <chr> <chr> <date> <dbl> <dbl> <dbl>
## 1 4 A AGILENT TECHNOLOGIES 2007-01-03 34.99 35.48 34.05
## 2 4 A AGILENT TECHNOLOGIES 2007-01-04 34.30 34.60 33.46
## 3 4 A AGILENT TECHNOLOGIES 2007-01-05 34.30 34.40 34.00
## 4 4 A AGILENT TECHNOLOGIES 2007-01-08 33.98 34.08 33.68
## 5 4 A AGILENT TECHNOLOGIES 2007-01-09 34.08 34.32 33.63
## 6 4 A AGILENT TECHNOLOGIES 2007-01-10 34.04 34.04 33.37
## 7 4 A AGILENT TECHNOLOGIES 2007-01-11 33.83 34.04 33.35
## 8 4 A AGILENT TECHNOLOGIES 2007-01-12 33.67 34.04 33.54
## 9 4 A AGILENT TECHNOLOGIES 2007-01-16 33.51 33.93 33.34
## 10 4 A AGILENT TECHNOLOGIES 2007-01-17 33.43 33.48 32.76
## # ... with 1,209,810 more rows, and 3 more variables: close <dbl>,
## # volume <dbl>, adjusted <dbl>
And, let’s see how long it took when processing in parallel.
time_elapsed_parallel
## user system elapsed
## 2.47 0.85 39.48
The processing time is approximately 0.66 minutes, which is 5.6X faster! Note that it’s not a full 8X faster because of transmission time as data is sent to and from the nodes. With that said, the speed will approach 8X improvement as calculations become longer since the transmission time is fixed whereas the computation time is variable.
Conclusion
Parallelizing code can drastically improve speed on multi-core machines. It makes the most sense in situations involving many iterative computations. On an 8 core machine, processing time significantly improves. It will not be quite 8X faster, but the longer the computation the closer the speed gets to the full 8X improvement. For a computation that takes two minutes under normal conditions, we improved the processing speed by over 5X through parallel processing!
Recap
The focus of this post was to show how you can implement tidyquant with the multidplyr parallel-processing package for parallel processing financial applications. We worked through the five main steps in the multidplyr workflow using the new tidyquant package, which makes it much easier to get financial data in tidy format. Keep in mind that you can use any tq_get “get” option at scale.
Further Reading
-
Tidyquant Vignettes: This tutorial just scratches the surface of tidyquant. The vignettes explain much, much more!
-
Multidplyr on GitHub: The vignette explains the multidplyr workflow using the flights data set from the nycflights13 package.