tidyquant 0.5.0: select, rollapply, and Quandl
Written by Davis Vaughan
We’ve got some good stuff cooking over at Business Science. Yesterday, we had the fifth official release (0.5.0) of tidyquant to CRAN. The release includes some great new features. First, the Quandl integration is complete, which now enables getting Quandl data in “tidy” format. Second, we have a new mechanism to handle selecting which columns get sent to the mutation functions. The new argument name is… select, and it provides increased flexibility which we show off in a rollapply example. Finally, we have added several PerformanceAnalytics functions that deal with modifying returns to the mutation functions. In this post, we’ll go over a few of the new features in version 5.
Quandl integration
We couldn’t wait to talk about the new Quandl integration for tidyquant! Two weeks ago, we went ahead and released a Quandl blog post using the GitHub development version. However, it is worth mentioning again now that it is officially being released. Definitely go check out that post to learn more!
We would like to highlight one feature that that post didn’t cover: data tables. These are data sets from Quandl that aren’t in a time series format, but are more of a treasure trove of other information. Many of them are premium datasets, meaning they cost money, but a few are free or have free samples. One of them is the Fundamentals Condensed datatable from Zacks. According to Quandl,
“Updated daily, this database contains over 70 fundamental indicators, including income statement, balance sheet, cash flow line items and precalculated ratios, for over 17,000 US and Canadian Equities, including 9,000+ delisted stocks.”
Without a premium Quandl account, we won’t be able to access all of it, but Quandl still offers a sample of the data. Let’s see how to grab this. First, we will want to set the Quandl API key linked to our account so that we have more than 50 calls per day.
library(tidyquant)
quandl_api_key("api-key-goes-here")
Now, we can use tq_get(get = "quandl.datatable") with the ZACKS/FC Quandl code. There’s a lot of data here, including mailing address, company officers, and numerous fundamentals stats!
FC <- tq_get("ZACKS/FC", get = "quandl.datatable")
FC %>%
slice(1:3) %>%
knitr::kable()
| m_ticker |
ticker |
comp_name |
comp_name_2 |
exchange |
currency_code |
per_end_date |
per_type |
per_code |
per_fisc_year |
per_fisc_qtr |
per_cal_year |
per_cal_qtr |
data_type_ind |
filing_type |
qtr_nbr |
zacks_sector_code |
zacks_x_ind_code |
zacks_metrics_ind_code |
fye_month |
comp_cik |
per_len |
sic_code |
filing_date |
last_changed_date |
state_incorp_name |
bus_address_line_1 |
bus_city |
bus_state_name |
bus_post_code |
bus_phone_nbr |
bus_fax_nbr |
mail_address_line_1 |
mail_city |
mail_state_name |
mail_post_code |
country_name |
country_code |
home_exchange_name |
emp_cnt |
emp_pt_cnt |
emp_ft_cnt |
emp_other_cnt |
comm_share_holder |
auditor |
auditor_opinion |
comp_url |
email_addr |
nbr_shares_out |
shares_out_date |
officer_name_1 |
officer_title_1 |
officer_name_2 |
officer_title_2 |
officer_name_3 |
officer_title_3 |
officer_name_4 |
officer_title_4 |
officer_name_5 |
officer_title_5 |
rpt_0_date |
tot_revnu |
cost_good_sold |
gross_profit |
tot_deprec_amort |
int_exp_oper |
int_invst_income_oper |
res_dev_exp |
in_proc_res_dev_exp_aggr |
tot_sell_gen_admin_exp |
rental_exp_ind_broker |
pension_post_retire_exp |
other_oper_income_exp |
tot_oper_exp |
oper_income |
non_oper_int_exp |
int_cap |
asset_wdown_impair_aggr |
restruct_charge |
merger_acq_income_aggr |
rental_income |
spcl_unusual_charge |
impair_goodwill |
litig_aggr |
gain_loss_sale_asset_aggr |
gain_loss_sale_invst_aggr |
stock_div_subsid |
income_loss_equity_invst_other |
pre_tax_minority_int |
int_invst_income |
other_non_oper_income_exp |
tot_non_oper_income_exp |
pre_tax_income |
tot_provsn_income_tax |
income_aft_tax |
minority_int |
equity_earn_subsid |
invst_gain_loss_other |
other_income |
income_cont_oper |
income_discont_oper |
income_bef_exord_acct_change |
exord_income_loss |
cumul_eff_acct_change |
consol_net_income_loss |
non_ctl_int |
net_income_parent_comp |
pref_stock_div_other_adj |
net_income_loss_share_holder |
eps_basic_cont_oper |
eps_basic_discont_oper |
eps_basic_acct_change |
eps_basic_extra |
eps_basic_consol |
eps_basic_parent_comp |
basic_net_eps |
eps_diluted_cont_oper |
eps_diluted_discont_oper |
eps_diluted_acct_change |
eps_diluted_extra |
eps_diluted_consol |
eps_diluted_parent_comp |
diluted_net_eps |
dilution_factor |
avg_d_shares |
avg_b_shares |
norm_pre_tax_income |
norm_aft_tax_income |
ebitda |
ebit |
rpt_1_date |
cash_sterm_invst |
note_loan_rcv |
rcv_est_doubt |
rcv_tot |
invty |
prepaid_expense |
def_charge_curr |
def_tax_asset_curr |
asset_discont_oper_curr |
other_curr_asset |
tot_curr_asset |
gross_prop_plant_equip |
tot_accum_deprec |
net_prop_plant_equip |
net_real_estate_misc_prop |
cap_software |
lterm_invst |
adv_dep |
lterm_rcv |
invty_lterm |
goodwill_intang_asset_tot |
def_charge_non_curr |
def_tax_asset_lterm |
asset_discont_oper_lterm |
pension_post_retire_asset |
other_lterm_asset |
tot_lterm_asset |
tot_asset |
note_pay |
acct_pay |
div_pay |
other_pay |
accrued_exp |
other_accrued_exp |
curr_portion_debt |
curr_portion_cap_lease |
curr_portion_tax_pay |
defer_revnu_curr |
defer_tax_liab_curr |
liab_discont_oper_curr |
other_curr_liab |
tot_curr_liab |
tot_lterm_debt |
defer_revnu_non_curr |
pension_post_retire_liab |
defer_tax_liab_lterm |
mand_redeem_pref_sec_subsid |
pref_stock_liab |
min_int |
liab_disc_oper_lterm |
other_non_curr_liab |
tot_lterm_liab |
tot_liab |
tot_pref_stock |
comm_stock_net |
addtl_paid_in_cap |
retain_earn_accum_deficit |
equity_equiv |
treas_stock |
compr_income |
def_compsn |
other_share_holder_equity |
tot_comm_equity |
tot_share_holder_equity |
tot_liab_share_holder_equity |
comm_shares_out |
pref_stock_shares_out |
tang_stock_holder_equity |
rpt_2_date |
net_income_loss |
tot_deprec_amort_cash_flow |
other_non_cash_item |
tot_non_cash_item |
change_acct_rcv |
change_invty |
change_acct_pay |
change_acct_pay_accrued_liab |
change_income_tax |
change_asset_liab |
tot_change_asset_liab |
oper_activity_other |
cash_flow_oper_activity |
net_change_prop_plant_equip |
net_change_intang_asset |
net_acq_divst |
net_change_sterm_invst |
net_change_lterm_invst |
net_change_invst_tot |
invst_activity_other |
cash_flow_invst_activity |
net_lterm_debt |
net_curr_debt |
debt_issue_retire_net_tot |
net_comm_equity_issued_repurch |
net_pref_equity_issued_repurch |
net_tot_equity_issued_repurch |
tot_comm_pref_stock_div_paid |
fin_activity_other |
cash_flow_fin_activity |
fgn_exchange_rate_adj |
disc_oper_misc_cash_flow_adj |
incr_decr_cash |
beg_cash |
end_cash |
stock_based_compsn |
comm_stock_div_paid |
pref_stock_div_paid |
tot_deprec_amort_qd |
stock_based_compsn_qd |
cash_flow_oper_activity_qd |
net_change_prop_plant_equip_qd |
comm_stock_div_paid_qd |
pref_stock_div_paid_qd |
tot_comm_pref_stock_div_qd |
wavg_shares_out |
wavg_shares_out_diluted |
eps_basic_net |
eps_diluted_net |
| AAPL |
AAPL |
APPLE INC |
Apple Inc. |
NSDQ |
USD |
2011-09-30 |
A |
NA |
2011 |
4 |
2011 |
3 |
F |
10-K |
2011 |
10 |
199 |
9 |
9 |
0000320193 |
12 |
3571 |
2011-10-26 |
2011-10-26 |
CA |
ONE INFINITE LOOP |
CUPERTINO |
CA |
95014 |
408-996-1010 |
408-996-0275 |
ONE INFINITE LOOP |
CUPERTINO |
CA |
95014 |
UNITED STATES |
X1 |
NA |
63300 |
2900 |
60400 |
NA |
28543 |
Ernst & Young LLP |
Fair |
www.apple.com |
[email protected] |
6505863000 |
2011-10-14 |
Timothy D. Cook |
Chief Executive Officer and Director |
Peter Oppenheimer |
Senior Vice President and Chief Financial Officer |
Betsy Rafael |
Vice President and Corporate Controller |
William V. Campbell |
Director |
Millard S. Drexler |
Director |
2013-10-30 |
108249 |
64431 |
43818 |
NA |
NA |
NA |
2429 |
NA |
7599 |
NA |
NA |
NA |
74459 |
33790 |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
415 |
415 |
34205 |
8283 |
25922 |
NA |
NA |
NA |
NA |
25922 |
NA |
25922 |
NA |
NA |
25922 |
NA |
25922 |
NA |
25922 |
4.0066 |
NA |
NA |
NA |
4.0066 |
4.0066 |
4.0071 |
3.9536 |
NA |
NA |
NA |
3.9536 |
3.9536 |
3.9543 |
4.3340 |
6556.515 |
6469.806 |
34205 |
25922 |
35604 |
33790 |
2012-10-31 |
25952 |
NA |
NA |
11717 |
776 |
NA |
NA |
2014 |
NA |
4529 |
44988 |
11768 |
3991 |
7777 |
NA |
NA |
55618 |
NA |
NA |
NA |
4432 |
NA |
NA |
NA |
NA |
3556 |
71383 |
116371 |
NA |
14632 |
NA |
NA |
9247 |
NA |
NA |
NA |
NA |
4091 |
NA |
NA |
NA |
27970 |
NA |
1686 |
NA |
NA |
NA |
NA |
NA |
NA |
10100 |
11786 |
39756 |
NA |
13331 |
NA |
62841 |
NA |
NA |
443 |
NA |
NA |
76615 |
76615 |
116371 |
6504.939 |
NA |
72183 |
2013-10-30 |
25922 |
1814 |
4036 |
5850 |
143 |
275 |
2515 |
NA |
NA |
2824 |
5757 |
NA |
37529 |
-4260 |
-3192 |
-244 |
-32464 |
NA |
-32464 |
-259 |
-40419 |
NA |
NA |
NA |
831 |
NA |
831 |
NA |
613 |
1444 |
NA |
NA |
-1446 |
11261 |
9815 |
1168 |
0 |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
6469.806 |
6556.515 |
4.0071 |
3.9543 |
| AAPL |
AAPL |
APPLE INC |
Apple Inc. |
NSDQ |
USD |
2012-09-30 |
A |
NA |
2012 |
4 |
2012 |
3 |
F |
10-K |
2012 |
10 |
199 |
9 |
9 |
0000320193 |
12 |
3571 |
2012-10-31 |
2012-10-31 |
CA |
ONE INFINITE LOOP |
CUPERTINO |
CA |
95014 |
408-996-1010 |
408-996-0275 |
ONE INFINITE LOOP |
CUPERTINO |
CA |
95014 |
UNITED STATES |
X1 |
NA |
76100 |
3300 |
72800 |
NA |
27696 |
Ernst & Young LLP |
Fair |
www.apple.com |
[email protected] |
6584844000 |
2012-10-19 |
Timothy D. Cook |
Chief Executive Officer and Director |
Peter Oppenheimer |
Senior Vice President and Chief Financial Officer |
William V. Campbell |
Director |
Millard S. Drexler |
Director |
Al Gore |
Director |
2014-10-27 |
156508 |
87846 |
68662 |
NA |
NA |
NA |
3381 |
NA |
10040 |
NA |
NA |
NA |
101267 |
55241 |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
522 |
522 |
55763 |
14030 |
41733 |
NA |
NA |
NA |
NA |
41733 |
NA |
41733 |
NA |
NA |
41733 |
NA |
41733 |
NA |
41733 |
6.3776 |
NA |
NA |
NA |
6.3776 |
6.3776 |
6.3771 |
6.3065 |
NA |
NA |
NA |
6.3065 |
6.3065 |
6.3071 |
23.3164 |
6617.485 |
6543.726 |
55763 |
41733 |
58518 |
55241 |
2013-10-30 |
29129 |
NA |
NA |
18692 |
791 |
NA |
NA |
2583 |
NA |
6458 |
57653 |
21887 |
6435 |
15452 |
NA |
NA |
92122 |
NA |
NA |
NA |
5359 |
NA |
NA |
NA |
NA |
5478 |
118411 |
176064 |
NA |
21175 |
NA |
NA |
11414 |
NA |
NA |
NA |
NA |
5953 |
NA |
NA |
NA |
38542 |
NA |
2648 |
NA |
NA |
NA |
NA |
NA |
NA |
16664 |
19312 |
57854 |
NA |
16422 |
NA |
101289 |
NA |
NA |
499 |
NA |
NA |
118210 |
118210 |
176064 |
6574.456 |
NA |
112851 |
2014-10-27 |
41733 |
3277 |
6145 |
9422 |
-5551 |
-15 |
4467 |
NA |
NA |
800 |
-299 |
NA |
50856 |
-8295 |
-1107 |
-350 |
-38427 |
NA |
-38427 |
-48 |
-48227 |
NA |
NA |
NA |
665 |
NA |
665 |
-2488 |
125 |
-1698 |
NA |
NA |
931 |
9815 |
10746 |
1740 |
-2488 |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
6543.726 |
6617.483 |
6.3800 |
6.3100 |
| AAPL |
AAPL |
APPLE INC |
Apple Inc. |
NSDQ |
USD |
2013-09-30 |
A |
NA |
2013 |
4 |
2013 |
3 |
F |
10-K |
2013 |
10 |
199 |
9 |
9 |
0000320193 |
12 |
3571 |
2013-10-30 |
2013-10-29 |
CA |
ONE INFINITE LOOP |
CUPERTINO |
CA |
95014 |
408-996-1010 |
408-974-2483 |
ONE INFINITE LOOP |
CUPERTINO |
CA |
95014 |
UNITED STATES |
X1 |
NA |
84400 |
4100 |
80300 |
NA |
24710 |
Ernst & Young LLP |
Fair |
www.apple.com |
[email protected] |
6298166000 |
2013-10-18 |
Timothy D. Cook |
Chief Executive Officer and Director |
Peter Oppenheimer |
Senior Vice President and Chief Financial Officer |
Luca Maestri |
Vice President and Corporate Controller |
William V. Campbell |
Director |
Millard S. Drexler |
Director |
2015-10-28 |
170910 |
106606 |
64304 |
NA |
NA |
NA |
4475 |
NA |
10830 |
NA |
NA |
NA |
121911 |
48999 |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
1156 |
1156 |
50155 |
13118 |
37037 |
NA |
NA |
NA |
NA |
37037 |
NA |
37037 |
NA |
NA |
37037 |
NA |
37037 |
NA |
37037 |
5.7180 |
NA |
NA |
NA |
5.7180 |
5.7180 |
5.7186 |
5.6791 |
NA |
NA |
NA |
5.6791 |
5.6791 |
5.6786 |
5.8789 |
6521.634 |
6477.317 |
50155 |
37037 |
55756 |
48999 |
2014-10-27 |
40546 |
NA |
NA |
20641 |
1764 |
NA |
NA |
3453 |
NA |
6882 |
73286 |
28519 |
11922 |
16597 |
NA |
NA |
106215 |
NA |
NA |
NA |
5756 |
NA |
NA |
NA |
NA |
5146 |
133714 |
207000 |
NA |
22367 |
NA |
NA |
13856 |
NA |
NA |
NA |
NA |
7435 |
NA |
NA |
NA |
43658 |
16960 |
2625 |
NA |
NA |
NA |
NA |
NA |
NA |
20208 |
39793 |
83451 |
NA |
19764 |
NA |
104256 |
NA |
NA |
-471 |
NA |
NA |
123549 |
123549 |
207000 |
6294.494 |
NA |
117793 |
2015-10-28 |
37037 |
6757 |
3394 |
10151 |
-2172 |
-973 |
2340 |
NA |
NA |
7283 |
6478 |
NA |
53666 |
-8165 |
-911 |
-496 |
-24042 |
NA |
-24042 |
-160 |
-33774 |
16896 |
NA |
16896 |
-22330 |
NA |
-22330 |
-10564 |
-381 |
-16379 |
NA |
NA |
3513 |
10746 |
14259 |
2253 |
-10564 |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
NA |
6477.320 |
6521.634 |
5.7200 |
5.6800 |
Quandl is a very extensive data source. Finding the right series can sometimes be a challenge, but their documentation and search function has greatly improved from a few years ago. In addition, with quandl_search() users can even find data sets from within the R console. Let’s search for the WTI crude prices within the FRED database.
quandl_search(query = "WTI", database_code = "FRED", silent = TRUE) %>%
select(-description) %>%
slice(1:3) %>%
knitr::kable()
| id |
dataset_code |
database_code |
name |
refreshed_at |
newest_available_date |
oldest_available_date |
column_names |
frequency |
type |
premium |
database_id |
| 34399442 |
WTISPLC |
FRED |
Spot Crude Oil Price: West Texas Intermediate (WTI) |
2017-03-18T04:39:31.083Z |
2017-02-01 |
1946-01-01 |
DATE, VALUE |
monthly |
Time Series |
FALSE |
118 |
| 120621 |
ACOILWTICO |
FRED |
Crude Oil Prices: West Texas Intermediate (WTI) - Cushing, Oklahoma |
2016-12-11T19:35:20.310Z |
2015-01-01 |
1986-01-01 |
DATE, VALUE |
annual |
Time Series |
FALSE |
118 |
| 120619 |
MCOILWTICO |
FRED |
Crude Oil Prices: West Texas Intermediate (WTI) - Cushing, Oklahoma |
2017-03-17T15:46:22.490Z |
2017-02-01 |
1986-01-01 |
DATE, VALUE |
monthly |
Time Series |
FALSE |
118 |
selecting columns: A flexible approach
Previously, when selecting columns with tq_mutate() and tq_transmute(), we would use the ohlc_fun argument to select the columns to mutate on. ohlc_fun leveraged the numerous functions from quantmod that extract specific columns from OHLC (Open High Low Close) price data such as Ad() (adjusted) or Cl() (close). While this was great for OHLC data, it was not ideal for datasets not in the OHLC form. It also kept users from performing rolling regressions using custom functions with rollapply(). To fix this, we’ve come up with a new approach that replaces ohlc_fun through a new argument, select. This new approach uses dplyr for selecting data frame columns instead of relying on quantmod, and as a result it has a “tidyverse” feel. While this seems like a small change, in the following examples you will see just how much more flexibility this brings.
select VS ohlc_fun
Here’s a quick example demonstrating the difference in the approaches. Let’s first grab the stock price data for IBM.
ibm <- tq_get("IBM")
ibm
## # A tibble: 2,581 × 7
## date open high low close volume adjusted
## <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2007-01-03 97.18 98.40 96.26 97.27 9196800 77.73997
## 2 2007-01-04 97.25 98.79 96.88 98.31 10524500 78.57116
## 3 2007-01-05 97.60 97.95 96.91 97.42 7221300 77.85985
## 4 2007-01-08 98.50 99.50 98.35 98.90 10340000 79.04270
## 5 2007-01-09 99.08 100.33 99.07 100.07 11108200 79.97778
## 6 2007-01-10 98.50 99.05 97.93 98.89 8744800 79.03470
## 7 2007-01-11 99.00 99.90 98.50 98.65 8000700 78.84289
## 8 2007-01-12 98.99 99.69 98.50 99.34 6636500 79.39435
## 9 2007-01-16 99.40 100.84 99.30 100.82 9602200 80.57719
## 10 2007-01-17 100.69 100.90 99.90 100.02 8200700 79.93782
## # ... with 2,571 more rows
What if you wanted to calculate the daily returns of the adjusted stock price? Previously, you might have done something like this…
tq_mutate(ibm, ohlc_fun = Ad, mutate_fun = dailyReturn) %>%
slice(1:5) %>%
knitr::kable()
## Warning: Argument ohlc_fun is deprecated; please use select instead.
| date |
open |
high |
low |
close |
volume |
adjusted |
daily.returns |
| 2007-01-03 |
97.18 |
98.40 |
96.26 |
97.27 |
9196800 |
77.73997 |
0.0000000 |
| 2007-01-04 |
97.25 |
98.79 |
96.88 |
98.31 |
10524500 |
78.57116 |
0.0106919 |
| 2007-01-05 |
97.60 |
97.95 |
96.91 |
97.42 |
7221300 |
77.85985 |
-0.0090530 |
| 2007-01-08 |
98.50 |
99.50 |
98.35 |
98.90 |
10340000 |
79.04270 |
0.0151920 |
| 2007-01-09 |
99.08 |
100.33 |
99.07 |
100.07 |
11108200 |
79.97778 |
0.0118301 |
At this point, ohlc_fun will still work, but you’ll notice that a warning appears notifying you that we’ve deprecated ohlc_fun. In version 6, we will remove the argument completely. Let’s see the new approach with select.
tq_mutate(ibm, select = adjusted, mutate_fun = dailyReturn) %>%
slice(1:5) %>%
knitr::kable()
| date |
open |
high |
low |
close |
volume |
adjusted |
daily.returns |
| 2007-01-03 |
97.18 |
98.40 |
96.26 |
97.27 |
9196800 |
77.73997 |
0.0000000 |
| 2007-01-04 |
97.25 |
98.79 |
96.88 |
98.31 |
10524500 |
78.57116 |
0.0106919 |
| 2007-01-05 |
97.60 |
97.95 |
96.91 |
97.42 |
7221300 |
77.85985 |
-0.0090530 |
| 2007-01-08 |
98.50 |
99.50 |
98.35 |
98.90 |
10340000 |
79.04270 |
0.0151920 |
| 2007-01-09 |
99.08 |
100.33 |
99.07 |
100.07 |
11108200 |
79.97778 |
0.0118301 |
As you can see, the new approach is similar to dplyr::mutate in that you simply specify the name of the columns that get mutated. You can even select multiple columns with the dplyr shorthand. Here we succinctly select the columns open, high, low, and close and change to a weekly periodicity. Since we change periodicity, we have to use tq_transmute() to drop the other columns.
tq_transmute(ibm, select = open:close, mutate_fun = to.weekly) %>%
slice(1:5) %>%
knitr::kable()
| date |
open |
high |
low |
close |
| 2007-01-05 |
97.60 |
97.95 |
96.91 |
97.42 |
| 2007-01-12 |
98.99 |
99.69 |
98.50 |
99.34 |
| 2007-01-19 |
95.00 |
96.85 |
94.55 |
96.17 |
| 2007-01-26 |
97.52 |
97.83 |
96.84 |
97.45 |
| 2007-02-02 |
99.10 |
99.73 |
98.88 |
99.17 |
One final note. If you want to mutate the entire dataset, you can leave off the select argument so that it keeps its default value of NULL which passes the entire data frame to the mutate function.
Working with non-OHLC data
The select argument is more than a surface level change. The change from the OHLC functions allows us to work with non-OHLC data straight from tq_mutate(). This used to be a little awkward. Since the columns of non-OHLC data could not be selected with a quantmod function, we had to use tq_mutate_xy() to find them. The intended use of the *_xy() functions is for working with functions that require mutating both x and y in parallel, so this definitely wasn’t best practice. Check out this old example of working with some crude oil prices from FRED, and applying a 1 period lag.
oil_prices <- tq_get("DCOILWTICO", get = "economic.data")
oil_prices
## # A tibble: 2,671 × 2
## date price
## <date> <dbl>
## 1 2007-01-01 NA
## 2 2007-01-02 60.77
## 3 2007-01-03 58.31
## 4 2007-01-04 55.65
## 5 2007-01-05 56.29
## 6 2007-01-08 56.08
## 7 2007-01-09 55.65
## 8 2007-01-10 53.95
## 9 2007-01-11 51.91
## 10 2007-01-12 52.96
## # ... with 2,661 more rows
tq_mutate_xy() was the only thing that worked in the old version, but it just felt wrong!
tq_mutate_xy(oil_prices, x = price, y = NULL, mutate_fun = lag.xts, k = 1)
## # A tibble: 2,671 × 3
## date price lag.xts
## <date> <dbl> <dbl>
## 1 2007-01-01 NA NA
## 2 2007-01-02 60.77 NA
## 3 2007-01-03 58.31 60.77
## 4 2007-01-04 55.65 58.31
## 5 2007-01-05 56.29 55.65
## 6 2007-01-08 56.08 56.29
## 7 2007-01-09 55.65 56.08
## 8 2007-01-10 53.95 55.65
## 9 2007-01-11 51.91 53.95
## 10 2007-01-12 52.96 51.91
## # ... with 2,661 more rows
Enter, select. This works much better!
tq_mutate(oil_prices, select = price, mutate_fun = lag.xts, k = 1)
## # A tibble: 2,671 × 3
## date price lag.xts
## <date> <dbl> <dbl>
## 1 2007-01-01 NA NA
## 2 2007-01-02 60.77 NA
## 3 2007-01-03 58.31 60.77
## 4 2007-01-04 55.65 58.31
## 5 2007-01-05 56.29 55.65
## 6 2007-01-08 56.08 56.29
## 7 2007-01-09 55.65 56.08
## 8 2007-01-10 53.95 55.65
## 9 2007-01-11 51.91 53.95
## 10 2007-01-12 52.96 51.91
## # ... with 2,661 more rows
Getting things rolling with rollapply
Something that we are very excited about with this new version is the ability to perform custom rolling calculations with rollapply. This is a byproduct of the new select argument, and has some pretty cool use cases. In the example below, we will walk through a rolling CAPM analysis of Apple stock.
CAPM stands for Capital Asset Pricing Model, and is a way to determine the theoretically appropriate expected stock return, based on exposure to market risk. Essentially, the CAPM model performs a linear regression with Apple’s excess return as the dependent variable, and the “market’s” excess return as the independent variable. We will pull from the Fama French website for the risk free rate and the market return. Here is the regression formula for CAPM:
\[r_{apple} - r_f = \alpha + \beta (r_{mkt} - r_f) + \epsilon\]
Where r_f is the risk free return, and epsilon is the normally distributed error term. The key terms of interest are alpha and beta, the coefficients estimated from the regression. Alpha is the excess return of a stock relative to a market index, and beta is a measure of the volatility of a stock in relation to the market. It would be interesting to evaluate the stability of the model, and one way of doing this is by performing a rolling regression to see how alpha and beta change throughout time.
First, we will need two datasets: Fama French factors and Apple stock returns.
Fama French factors
Quandl actually has a cleaned up series for the Fama French factors going back to 1926! As of writing this, the most recent data point in their weekly series is 02/24/2017, so for reproducibility purposes we will stop the series there.
fama_french <- tq_get("KFRENCH/FACTORS_W", get = "quandl", to = "2017-02-24")
fama_french
## # A tibble: 5,849 × 5
## date mkt.rf smb hml rf
## <date> <dbl> <dbl> <dbl> <dbl>
## 1 2017-02-24 0.48 -1.09 -0.46 0.009
## 2 2017-02-17 1.53 -0.54 -0.39 0.009
## 3 2017-02-10 0.88 0.14 -1.20 0.009
## 4 2017-02-03 0.15 0.41 -0.67 0.009
## 5 2017-01-27 1.15 0.22 0.59 0.009
## 6 2017-01-20 -0.31 -1.13 -0.15 0.009
## 7 2017-01-13 0.09 0.47 -1.04 0.009
## 8 2017-01-06 1.69 -0.58 -1.25 0.009
## 9 2016-12-30 -1.16 -0.11 0.13 0.006
## 10 2016-12-23 0.32 0.17 0.71 0.006
## # ... with 5,839 more rows
We only need two columns for the CAPM analysis, mkt.rf and rf, so let’s select them.
fama_french <- fama_french %>%
select(date, mkt.rf, rf)
fama_french
## # A tibble: 5,849 × 3
## date mkt.rf rf
## <date> <dbl> <dbl>
## 1 2017-02-24 0.48 0.009
## 2 2017-02-17 1.53 0.009
## 3 2017-02-10 0.88 0.009
## 4 2017-02-03 0.15 0.009
## 5 2017-01-27 1.15 0.009
## 6 2017-01-20 -0.31 0.009
## 7 2017-01-13 0.09 0.009
## 8 2017-01-06 1.69 0.009
## 9 2016-12-30 -1.16 0.006
## 10 2016-12-23 0.32 0.006
## # ... with 5,839 more rows
Apple weekly stock returns
This one is easy, we will use tq_get() to pull the stock prices, and then use tq_transmute() for the returns. For this analysis, we will pull 15 years of prices.
apple_prices <- tq_get("AAPL",
get = "stock.prices",
from = "2002-02-24",
to = "2017-02-24")
apple_prices
## # A tibble: 3,778 × 7
## date open high low close volume adjusted
## <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2002-02-25 22.85 24.72 22.36 23.81 106712200 1.542406
## 2 2002-02-26 23.91 24.37 23.25 23.67 65032800 1.533337
## 3 2002-02-27 23.94 24.25 20.94 21.96 257539800 1.422564
## 4 2002-02-28 22.15 22.59 21.35 21.70 114234400 1.405721
## 5 2002-03-01 21.93 23.50 21.82 23.45 87248000 1.519086
## 6 2002-03-04 23.26 24.58 22.76 24.29 87064600 1.573501
## 7 2002-03-05 24.15 24.43 23.40 23.53 68675600 1.524268
## 8 2002-03-06 23.48 24.34 22.93 24.07 56551600 1.559249
## 9 2002-03-07 24.06 24.53 23.61 24.38 64562400 1.579331
## 10 2002-03-08 24.74 25.09 24.30 24.66 67443600 1.597469
## # ... with 3,768 more rows
Now, let’s get the weekly returns. We have to use tq_transmute() because the periodicity changes, and we will use the periodReturn() function from quantmod as our mutate_fun. Lastly, we change the return to a percentage because that is the form that the Fama French factors are in.
apple_return <- tq_transmute(apple_prices,
select = adjusted,
col_rename = "weekly_return",
mutate_fun = periodReturn,
period = "weekly") %>%
mutate(weekly_return = weekly_return * 100)
apple_return
## # A tibble: 783 × 2
## date weekly_return
## <date> <dbl>
## 1 2002-03-01 -1.5119236
## 2 2002-03-08 5.1598790
## 3 2002-03-15 1.1759853
## 4 2002-03-22 -3.4468571
## 5 2002-03-28 -1.7434935
## 6 2002-04-05 4.5205327
## 7 2002-04-12 1.2934187
## 8 2002-04-19 -0.3192103
## 9 2002-04-26 -7.8862983
## 10 2002-05-03 2.1729753
## # ... with 773 more rows
Merge the two datasets
Alright, now that we have the two data sets, let’s join them together. We want to keep all of apple_return, and just match the fama_french data to it. A left_join will serve that purpose.
joined_data <- left_join(apple_return, fama_french)
joined_data
## # A tibble: 783 × 4
## date weekly_return mkt.rf rf
## <date> <dbl> <dbl> <dbl>
## 1 2002-03-01 -1.5119236 3.79 0.033
## 2 2002-03-08 5.1598790 3.15 0.033
## 3 2002-03-15 1.1759853 0.09 0.033
## 4 2002-03-22 -3.4468571 -1.19 0.033
## 5 2002-03-28 -1.7434935 -0.04 0.033
## 6 2002-04-05 4.5205327 -2.15 0.038
## 7 2002-04-12 1.2934187 -0.51 0.038
## 8 2002-04-19 -0.3192103 1.26 0.038
## 9 2002-04-26 -7.8862983 -4.13 0.038
## 10 2002-05-03 2.1729753 -0.13 0.036
## # ... with 773 more rows
Remembering that the left side of the CAPM formula is apple return minus the risk free rate, we calculate that as well.
joined_data <- mutate(joined_data,
weekly_ret_rf = weekly_return - rf)
joined_data
## # A tibble: 783 × 5
## date weekly_return mkt.rf rf weekly_ret_rf
## <date> <dbl> <dbl> <dbl> <dbl>
## 1 2002-03-01 -1.5119236 3.79 0.033 -1.5449236
## 2 2002-03-08 5.1598790 3.15 0.033 5.1268790
## 3 2002-03-15 1.1759853 0.09 0.033 1.1429853
## 4 2002-03-22 -3.4468571 -1.19 0.033 -3.4798571
## 5 2002-03-28 -1.7434935 -0.04 0.033 -1.7764935
## 6 2002-04-05 4.5205327 -2.15 0.038 4.4825327
## 7 2002-04-12 1.2934187 -0.51 0.038 1.2554187
## 8 2002-04-19 -0.3192103 1.26 0.038 -0.3572103
## 9 2002-04-26 -7.8862983 -4.13 0.038 -7.9242983
## 10 2002-05-03 2.1729753 -0.13 0.036 2.1369753
## # ... with 773 more rows
Rolling CAPM
We are almost ready for the rolling CAPM. The last thing we need is a function that is applied at each iteration of our roll, which here will be a regression. We are really only interested in the coefficients from the regression, so that is what we will return. Note that the incoming data_xts will be an xts object, so we need to convert to a data.frame in the lm() function. The output should be a numeric vector. tq_mutate will take care of adding the appropriate columns provided the custom function (in our case regr_fun()) is handled in this manner.
regr_fun <- function(data_xts) {
lm(weekly_ret_rf ~ mkt.rf, data = as_data_frame(data_xts)) %>%
coef()
}
Now let’s work some magic. We will leave select out of this call to tq_mutate() since we can just pass the entire dataset into rollapply. To have enough data for a good analysis, we will set width equal to 260 for a 5 year rolling window of data per call. The final argument, by.column, is especially important so that rollapply doesn’t try and apply our regression to each column individually.
joined_data <- joined_data %>%
tq_mutate(mutate_fun = rollapply,
width = 260,
FUN = regr_fun,
by.column = FALSE,
col_rename = c("alpha", "beta"))
joined_data %>%
slice(255:265)
## # A tibble: 11 × 7
## date weekly_return mkt.rf rf weekly_ret_rf alpha
## <date> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2007-01-12 11.2522154 1.73 0.111 11.1412154 NA
## 2 2007-01-19 -6.4679733 -0.31 0.111 -6.5789733 NA
## 3 2007-01-26 -3.5254340 -0.57 0.111 -3.6364340 NA
## 4 2007-02-02 -0.7378731 1.94 0.096 -0.8338731 NA
## 5 2007-02-09 -1.7463114 -0.65 0.096 -1.8423114 NA
## 6 2007-02-16 1.8734247 1.22 0.096 1.7774247 0.6905407
## 7 2007-02-23 4.9982362 -0.05 0.096 4.9022362 0.7304938
## 8 2007-03-02 -4.1091364 -4.62 0.106 -4.2151364 0.7331868
## 9 2007-03-09 2.9973031 1.00 0.106 2.8913031 0.7353908
## 10 2007-03-16 1.8415416 -1.18 0.106 1.7355416 0.7560794
## 11 2007-03-23 4.3866501 3.48 0.106 4.2806501 0.7626701
## # ... with 1 more variables: beta <dbl>
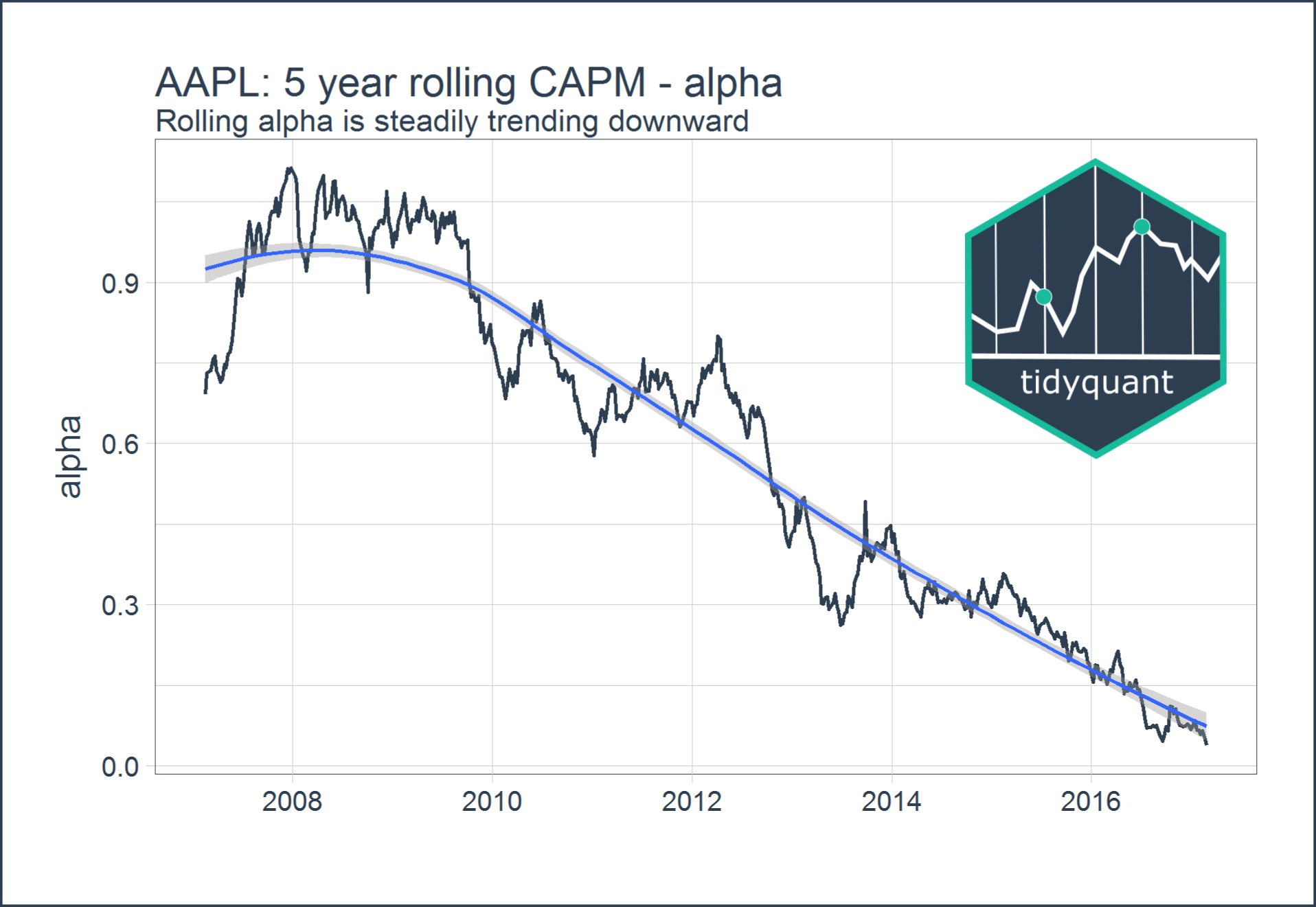
We had to scroll down to row 260 before we find any values for alpha and beta, but it’s more useful to create a plot. Looking at the rolling coefficient for alpha, it seems to be steadily trending downward over time.
filter(joined_data, !is.na(alpha)) %>%
ggplot(aes(x = date, y = alpha)) +
geom_line(size = 1, color = palette_light()[[1]]) +
geom_smooth() +
labs(title = "AAPL: 5 year rolling CAPM - alpha", x = "",
subtitle = "Rolling alpha is steadily trending downward") +
theme_tq(base_size = 18)
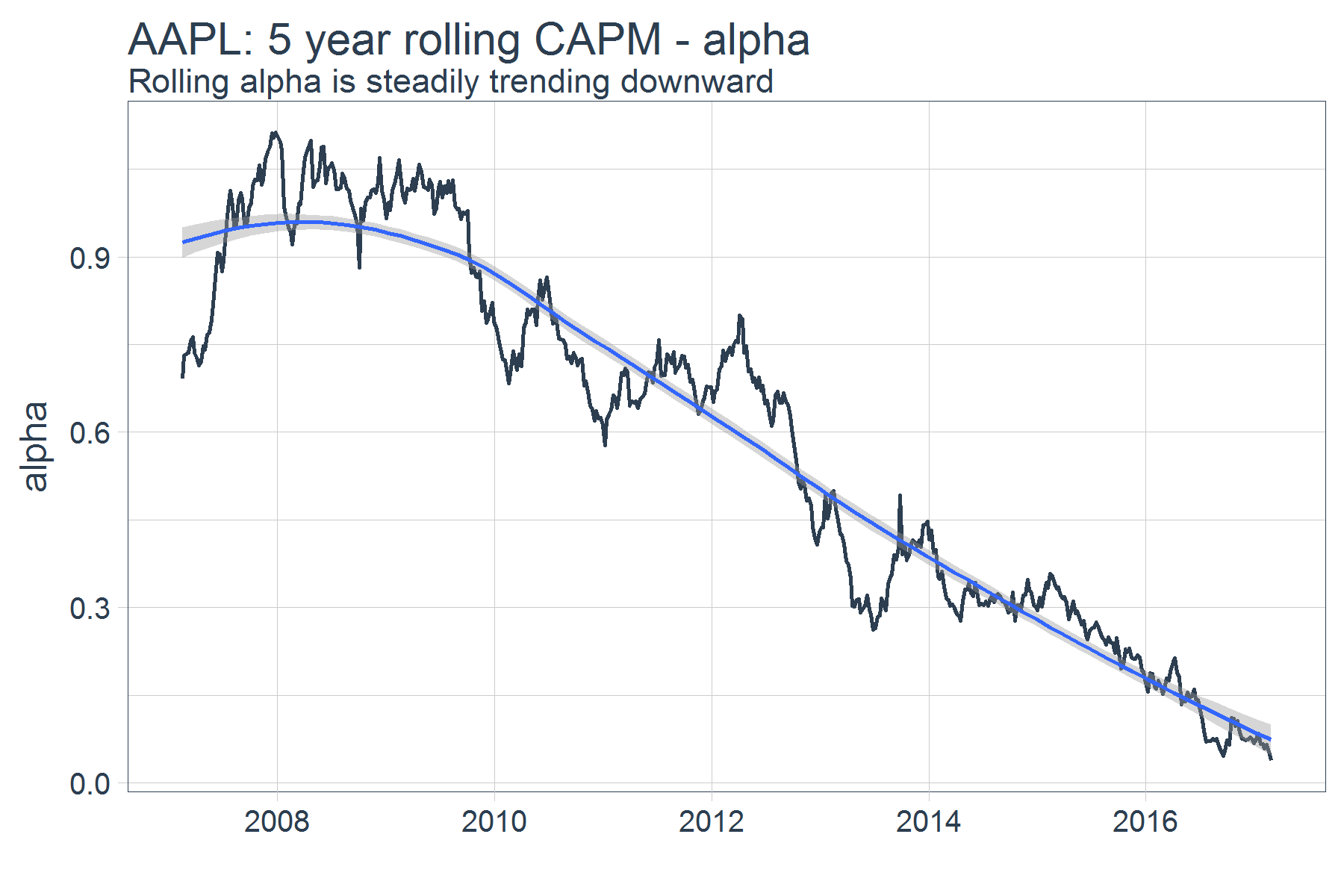
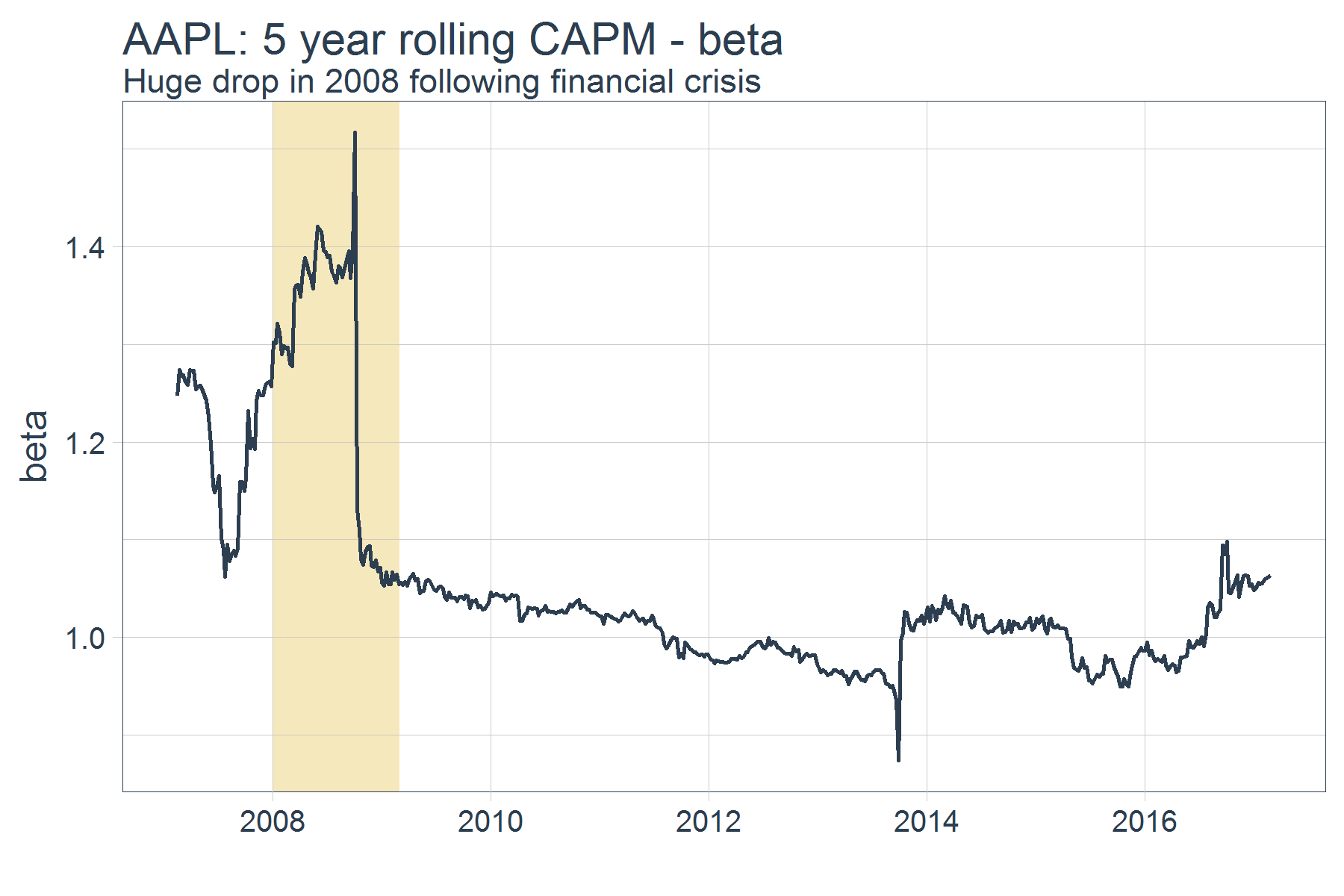
The rolling coefficient for beta is just as interesting, with a huge drop around 2008 likely having to deal with the financial crisis, but consistently over or near 1.
filter(joined_data, !is.na(alpha)) %>%
ggplot(aes(x = date, y = beta)) +
geom_rect(xmin = as.numeric(ymd("2008-01-01")),
xmax = as.numeric(ymd("2009-03-01")),
ymin = 0, ymax = 2.0,
fill = palette_light()[[4]], alpha = 0.01) +
geom_line(size = 1, color = palette_light()[[1]]) +
labs(title = "AAPL: 5 year rolling CAPM - beta", x = "",
subtitle = "Huge drop in 2008 following financial crisis") +
theme_tq(base_size = 18)
Hopefully you can see the power that tidyquant gives to the user by allowing them to perform these rolling calculations with data frames!
As an aside, there are some improvements to this model that could be of interest to some users:
-
This says nothing to how well the CAPM model fits Apple’s return data. It only monitors the stability of the coefficients.
-
The mkt.rf data pulled from the Fama-French data set was only one part of a more detailed extension of CAPM, the Fama French 3 Factor Model. It would be interesting the stability of this model over time as well.
We have added a few new functions from the PerformanceAnalytics package to tq_mutate() and tq_transmute(), which can be reviewed using tq_mutate_fun_options()$PerformanceAnalytics. These differ from the PerformanceAnalytics functions available for use with tq_performance() (refer to tq_performance_fun_options()) in that the deal with transforming the returns data rather than calculating performance metrics.
tq_mutate_fun_options()$PerformanceAnalytics
## [1] "Return.annualized" "Return.annualized.excess"
## [3] "Return.clean" "Return.cumulative"
## [5] "Return.excess" "Return.Geltner"
## [7] "zerofill"
We can use the functions to clean and format returns for the FANG data set. The example below uses three progressive applications of tq_transmute() to apply various quant functions to the grouped stock prices from the FANG data set. First, we calculate daily returns using periodReturn from the quantmod package. Next, we use Return.clean to clean outliers from the return data. The alpha parameter is the percentage of outliers to be cleaned. Finally, Return.excess is used to calculate the excess returns using a risk-free rate of 3% (divided by 252 for 252 trade days in one year). Finally, we calculate general statistics on the returns by passing to tq_performance(performance_fun = table.Stats).
FANG %>%
group_by(symbol) %>%
tq_transmute(adjusted, periodReturn, period = "daily") %>%
tq_transmute(daily.returns, Return.clean, alpha = 0.05) %>%
tq_transmute(daily.returns, Return.excess, Rf = 0.03 / 252,
col_rename = "formatted.returns") %>%
tq_performance(Ra = formatted.returns,
performance_fun = table.Stats) %>%
knitr::kable()
| symbol |
ArithmeticMean |
GeometricMean |
Kurtosis |
LCLMean(0.95) |
Maximum |
Median |
Minimum |
NAs |
Observations |
Quartile1 |
Quartile3 |
SEMean |
Skewness |
Stdev |
UCLMean(0.95) |
Variance |
| FB |
0.0015 |
0.0013 |
35.2725 |
2e-04 |
0.2960 |
1e-03 |
-0.0695 |
0 |
1008 |
-0.0098 |
0.0119 |
7e-04 |
2.9098 |
0.0220 |
0.0029 |
0.0005 |
| AMZN |
0.0011 |
0.0009 |
9.6476 |
-1e-04 |
0.1412 |
6e-04 |
-0.1101 |
0 |
1008 |
-0.0082 |
0.0111 |
6e-04 |
0.4804 |
0.0194 |
0.0023 |
0.0004 |
| NFLX |
0.0026 |
0.0021 |
35.9090 |
6e-04 |
0.4221 |
-1e-04 |
-0.1938 |
0 |
1008 |
-0.0119 |
0.0149 |
1e-03 |
3.0745 |
0.0324 |
0.0046 |
0.0011 |
| GOOG |
0.0007 |
0.0006 |
22.1306 |
-2e-04 |
0.1604 |
0e+00 |
-0.0533 |
0 |
1008 |
-0.0067 |
0.0078 |
5e-04 |
2.2165 |
0.0148 |
0.0017 |
0.0002 |
Getting, cleaning and calculating excess returns is that easy with the additional PerformanceAnalytics mutation functions.
Further Reading
That’s all for now. We hope you enjoy the new release, and be on the lookout for more to come!
-
Tidyquant Vignettes: The Core Functions in tidyquant vignette has a nice section on the features related to the Quandl integration! The R Quantitative Analysis Package Integrations in tidyquant vignette includes another example of working with rollapply.
-
R for Data Science: A free book that thoroughly covers the “tidyverse”. A prerequisite for maximizing your abilities with tidyquant.