Customer Segmentation Part 1: K Means Clustering
Written

In this post, we’ll be using k-means clustering in R to segment customers into distinct groups based on purchasing habits. k-means clustering is an unsupervised learning technique, which means we don’t need to have a target for clustering. All we need is to format the data in a way the algorithm can process, and we’ll let it determine the customer segments or clusters. This makes k-means clustering great for exploratory analysis as well as a jumping-off point for more detailed analysis. We’ll walk through a relevant example using the Cannondale bikes data set from the orderSimulatoR project GitHub repository.
3 Part Series
Customer Segmentation Cheat Sheet
We have a cheat sheet that walks the user through the workflow for segmenting customers. You can download it here.
Download the Segmentation and Clustering Cheat Sheet
10-Minute Overview of Segmentation and Clustering taught in our Business Analysis with R (DS4B 101-R) Course
Table of Contents
How K-Means Works
The k-means clustering algorithm works by finding like groups based on Euclidean distance, a measure of distance or similarity. The practitioner selects \(k\) groups to cluster, and the algorithm finds the best centroids for the \(k\) groups. The practitioner can then use those groups to determine which factors group members relate. For customers, these would be their buying preferences.
Getting Started
To start, we’ll get need some orders to evaluate. If you’d like to follow along, we will be using the bikes data set, which can be retrieved here. We’ll load the data first using the xlsx package for reading Excel files.
# Read Cannondale orders data --------------------------------------------------
library(xlsx)
customers <- read.xlsx("./data/bikeshops.xlsx", sheetIndex = 1)
products <- read.xlsx("./data/bikes.xlsx", sheetIndex = 1)
orders <- read.xlsx("./data/orders.xlsx", sheetIndex = 1)
Next, we’ll get the data into a usable format, typical of an SQL query from an ERP database. The following code merges the customers, products and orders data frames using the dplyr package.
# Combine orders, customers, and products data frames --------------------------
library(dplyr)
orders.extended <- merge(orders, customers, by.x = "customer.id", by.y="bikeshop.id")
orders.extended <- merge(orders.extended, products, by.x = "product.id", by.y = "bike.id")
orders.extended <- orders.extended %>%
mutate(price.extended = price * quantity) %>%
select(order.date, order.id, order.line, bikeshop.name, model,
quantity, price, price.extended, category1, category2, frame) %>%
arrange(order.id, order.line)
knitr::kable(head(orders.extended)) # Preview the data
| order.date |
order.id |
order.line |
bikeshop.name |
model |
quantity |
price |
price.extended |
category1 |
category2 |
frame |
| 2011-01-07 |
1 |
1 |
Ithaca Mountain Climbers |
Jekyll Carbon 2 |
1 |
6070 |
6070 |
Mountain |
Over Mountain |
Carbon |
| 2011-01-07 |
1 |
2 |
Ithaca Mountain Climbers |
Trigger Carbon 2 |
1 |
5970 |
5970 |
Mountain |
Over Mountain |
Carbon |
| 2011-01-10 |
2 |
1 |
Kansas City 29ers |
Beast of the East 1 |
1 |
2770 |
2770 |
Mountain |
Trail |
Aluminum |
| 2011-01-10 |
2 |
2 |
Kansas City 29ers |
Trigger Carbon 2 |
1 |
5970 |
5970 |
Mountain |
Over Mountain |
Carbon |
| 2011-01-10 |
3 |
1 |
Louisville Race Equipment |
Supersix Evo Hi-Mod Team |
1 |
10660 |
10660 |
Road |
Elite Road |
Carbon |
| 2011-01-10 |
3 |
2 |
Louisville Race Equipment |
Jekyll Carbon 4 |
1 |
3200 |
3200 |
Mountain |
Over Mountain |
Carbon |
Developing a Hypothesis for Customer Trends
Developing a hypothesis is necessary as the hypothesis will guide our decisions on how to formulate the data in such a way to cluster customers. For the Cannondale orders, our hypothesis is that bike shops purchase Cannondale bike models based on features such as Mountain or Road Bikes and price tier (high/premium or low/affordable). Although we will use bike model to cluster on, the bike model features (e.g. price, category, etc) will be used for assessing the preferences of the customer clusters (more on this later).
To start, we’ll need a unit of measure to cluster on. We can select quantity purchased or total value of purchases. We’ll select quantity purchased because total value can be skewed by the bike unit price. For example, a premium bike can be sold for 10X more than an affordable bike, which can mask the quantity buying habits.
Manipulating the Data Frame
Next, we need a data manipulation plan of attack to implement clustering on our data. We’ll user our hypothesis to guide us. First, we’ll need to get the data frame into a format conducive to clustering bike models to customer id’s. Second, we’ll need to manipulate price into a categorical variables representing high/premium and low/affordable. Last, we’ll need to scale the bike model quantities purchased by customer so the k-means algorithm weights the purchases of each customer evenly.
We’ll tackle formatting the data frame for clustering first. We need to spread the customers by quantity of bike models purchased.
# Group by model & model features, summarize by quantity purchased -------------
library(tidyr) # Needed for spread function
customerTrends <- orders.extended %>%
group_by(bikeshop.name, model, category1, category2, frame, price) %>%
summarise(total.qty = sum(quantity)) %>%
spread(bikeshop.name, total.qty)
customerTrends[is.na(customerTrends)] <- 0 # Remove NA's
Next, we need to convert the unit price to categorical high/low variables. One way to do this is with the cut2() function from the Hmisc package. We’ll segment the price into high/low by median price. Selecting g = 2 divides the unit prices into two halves using the median as the split point.
# Convert price to binary high/low category ------------------------------------
library(Hmisc) # Needed for cut2 function
customerTrends$price <- cut2(customerTrends$price, g=2)
Last, we need to scale the quantity data. Unadjusted quantities presents a problem to the k-means algorithm. Some customers are larger than others meaning they purchase higher volumes. Fortunately, we can resolve this issue by converting the customer order quantities to proportion of the total bikes purchased by a customer. The prop.table() matrix function provides a convenient way to do this. An alternative is to use the scale() function, which normalizes the data. However, this is less interpretable than the proportion format.
# Convert customer purchase quantity to percentage of total quantity -----------
customerTrends.mat <- as.matrix(customerTrends[,-(1:5)]) # Drop first five columns
customerTrends.mat <- prop.table(customerTrends.mat, margin = 2) # column-wise pct
customerTrends <- bind_cols(customerTrends[,1:5], as.data.frame(customerTrends.mat))
The final data frame (first five rows shown below) is now ready for clustering.
# View data post manipulation --------------------------------------------------
knitr::kable(head(customerTrends))
| model |
category1 |
category2 |
frame |
price |
Albuquerque Cycles |
Ann Arbor Speed |
Austin Cruisers |
Cincinnati Speed |
Columbus Race Equipment |
Dallas Cycles |
Denver Bike Shop |
Detroit Cycles |
Indianapolis Velocipedes |
Ithaca Mountain Climbers |
Kansas City 29ers |
Las Vegas Cycles |
Los Angeles Cycles |
Louisville Race Equipment |
Miami Race Equipment |
Minneapolis Bike Shop |
Nashville Cruisers |
New Orleans Velocipedes |
New York Cycles |
Oklahoma City Race Equipment |
Philadelphia Bike Shop |
Phoenix Bi-peds |
Pittsburgh Mountain Machines |
Portland Bi-peds |
Providence Bi-peds |
San Antonio Bike Shop |
San Francisco Cruisers |
Seattle Race Equipment |
Tampa 29ers |
Wichita Speed |
| Bad Habit 1 |
Mountain |
Trail |
Aluminum |
[ 415, 3500) |
0.0174825 |
0.0066445 |
0.0081301 |
0.0051151 |
0.0101523 |
0.0128205 |
0.0117340 |
0.0099206 |
0.0062696 |
0.0181962 |
0.0181504 |
0.0016026 |
0.0062893 |
0.0075949 |
0.0042135 |
0.0182648 |
0.0086705 |
0.0184783 |
0.0074074 |
0.0129870 |
0.0244898 |
0.0112755 |
0.0159151 |
0.0108696 |
0.0092251 |
0.0215054 |
0.0026738 |
0.0156250 |
0.0194175 |
0.0059172 |
| Bad Habit 2 |
Mountain |
Trail |
Aluminum |
[ 415, 3500) |
0.0069930 |
0.0099668 |
0.0040650 |
0.0000000 |
0.0000000 |
0.0170940 |
0.0139070 |
0.0158730 |
0.0031348 |
0.0110759 |
0.0158456 |
0.0000000 |
0.0094340 |
0.0000000 |
0.0112360 |
0.0167428 |
0.0173410 |
0.0021739 |
0.0074074 |
0.0095238 |
0.0040816 |
0.0190275 |
0.0026525 |
0.0108696 |
0.0239852 |
0.0000000 |
0.0026738 |
0.0078125 |
0.0000000 |
0.0000000 |
| Beast of the East 1 |
Mountain |
Trail |
Aluminum |
[ 415, 3500) |
0.0104895 |
0.0149502 |
0.0081301 |
0.0000000 |
0.0000000 |
0.0042735 |
0.0182529 |
0.0119048 |
0.0094044 |
0.0213608 |
0.0181504 |
0.0016026 |
0.0251572 |
0.0000000 |
0.0140449 |
0.0167428 |
0.0086705 |
0.0086957 |
0.0172840 |
0.0242424 |
0.0000000 |
0.0126850 |
0.0053050 |
0.0108696 |
0.0092251 |
0.0053763 |
0.0000000 |
0.0156250 |
0.0097087 |
0.0000000 |
| Beast of the East 2 |
Mountain |
Trail |
Aluminum |
[ 415, 3500) |
0.0104895 |
0.0099668 |
0.0081301 |
0.0000000 |
0.0050761 |
0.0042735 |
0.0152108 |
0.0059524 |
0.0094044 |
0.0181962 |
0.0138289 |
0.0000000 |
0.0220126 |
0.0050633 |
0.0084270 |
0.0076104 |
0.0086705 |
0.0097826 |
0.0172840 |
0.0086580 |
0.0000000 |
0.0232558 |
0.0106101 |
0.0155280 |
0.0147601 |
0.0107527 |
0.0026738 |
0.0234375 |
0.0291262 |
0.0019724 |
| Beast of the East 3 |
Mountain |
Trail |
Aluminum |
[ 415, 3500) |
0.0034965 |
0.0033223 |
0.0000000 |
0.0000000 |
0.0025381 |
0.0042735 |
0.0169492 |
0.0119048 |
0.0000000 |
0.0102848 |
0.0181504 |
0.0032051 |
0.0000000 |
0.0050633 |
0.0042135 |
0.0152207 |
0.0202312 |
0.0043478 |
0.0049383 |
0.0051948 |
0.0204082 |
0.0162086 |
0.0026525 |
0.0201863 |
0.0073801 |
0.0322581 |
0.0000000 |
0.0078125 |
0.0097087 |
0.0000000 |
| CAAD Disc Ultegra |
Road |
Elite Road |
Aluminum |
[ 415, 3500) |
0.0139860 |
0.0265781 |
0.0203252 |
0.0153453 |
0.0101523 |
0.0000000 |
0.0108648 |
0.0079365 |
0.0094044 |
0.0000000 |
0.0106598 |
0.0112179 |
0.0157233 |
0.0278481 |
0.0210674 |
0.0182648 |
0.0375723 |
0.0152174 |
0.0172840 |
0.0103896 |
0.0163265 |
0.0126850 |
0.0026525 |
0.0139752 |
0.0073801 |
0.0053763 |
0.0026738 |
0.0078125 |
0.0000000 |
0.0098619 |
K-Means Clustering
Now we are ready to perform k-means clustering to segment our customer-base. Think of clusters as groups in the customer-base. Prior to starting we will need to choose the number of customer groups, \(k\), that are to be detected. The best way to do this is to think about the customer-base and our hypothesis. We believe that there are most likely to be at least four customer groups because of mountain bike vs road bike and premium vs affordable preferences. We also believe there could be more as some customers may not care about price but may still prefer a specific bike category. However, we’ll limit the clusters to eight as more is likely to overfit the segments.
Running the K-Means Algorithm
The code below does the following:
-
Converts the customerTrends data frame into kmeansDat.t. The model and features are dropped so the customer columns are all that are left. The data frame is transposed to have the customers as rows and models as columns. The kmeans() function requires this format.
-
Performs the kmeans() function to cluster the customer segments. We set minClust = 4 and maxClust = 8. From our hypothesis, we expect there to be at least four and at most six groups of customers. This is because customer preference is expected to vary by price (high/low) and category1 (mountain vs bike). There may be other groupings as well. Beyond eight segments may be overfitting the segments.
-
Uses the silhouette() function to obtain silhouette widths. Silhouette is a technique in clustering that validates the best cluster groups. The silhouette() function from the cluster package allows us to get the average width of silhouettes, which will be used to programmatically determine the optimal cluster size.
# Running the k-means algorithm -------------------------------------------------
library(cluster) # Needed for silhouette function
kmeansDat <- customerTrends[,-(1:5)] # Extract only customer columns
kmeansDat.t <- t(kmeansDat) # Get customers in rows and products in columns
# Setup for k-means loop
km.out <- list()
sil.out <- list()
x <- vector()
y <- vector()
minClust <- 4 # Hypothesized minimum number of segments
maxClust <- 8 # Hypothesized maximum number of segments
# Compute k-means clustering over various clusters, k, from minClust to maxClust
for (centr in minClust:maxClust) {
i <- centr-(minClust-1) # relevels start as 1, and increases with centr
set.seed(11) # For reproducibility
km.out[i] <- list(kmeans(kmeansDat.t, centers = centr, nstart = 50))
sil.out[i] <- list(silhouette(km.out[[i]][[1]], dist(kmeansDat.t)))
# Used for plotting silhouette average widths
x[i] = centr # value of k
y[i] = summary(sil.out[[i]])[[4]] # Silhouette average width
}
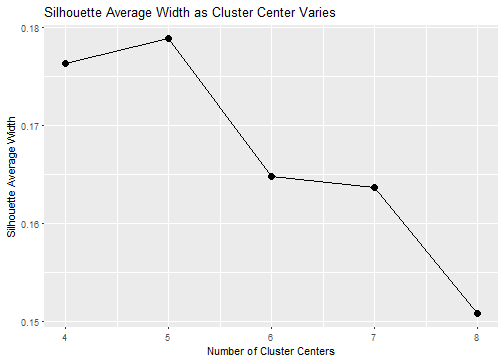
Next, we plot the silhouette average widths for the choice of clusters. The best cluster is the one with the largest silhouette average width, which turns out to be 5 clusters.
# Plot silhouette results to find best number of clusters; closer to 1 is better
library(ggplot2)
ggplot(data = data.frame(x, y), aes(x, y)) +
geom_point(size=3) +
geom_line() +
xlab("Number of Cluster Centers") +
ylab("Silhouette Average Width") +
ggtitle("Silhouette Average Width as Cluster Center Varies")
Which Customers are in Each Segment?
Now that we have clustered the data, we can inspect the groups find out which customers are grouped together. The code below groups the customer names by cluster X1 through X5.
# Get customer names that are in each segment ----------------------------------
# Get attributes of optimal k-means output
maxSilRow <- which.max(y) # Row number of max silhouette value
optimalClusters <- x[maxSilRow] # Number of clusters
km.out.best <- km.out[[maxSilRow]] # k-means output of best cluster
# Create list of customer names for each cluster
clusterNames <- list()
clusterList <- list()
for (clustr in 1:optimalClusters) {
clusterNames[clustr] <- paste0("X", clustr)
clusterList[clustr] <- list(
names(
km.out.best$cluster[km.out.best$cluster == clustr]
)
)
}
names(clusterList) <- clusterNames
print(clusterList)
## $X1
## [1] "Ithaca Mountain Climbers" "Pittsburgh Mountain Machines"
## [3] "Tampa 29ers"
##
## $X2
## [1] "Philadelphia Bike Shop" "San Antonio Bike Shop"
##
## $X3
## [1] "Ann Arbor Speed" "Austin Cruisers"
## [3] "Indianapolis Velocipedes" "Miami Race Equipment"
## [5] "Nashville Cruisers" "New Orleans Velocipedes"
## [7] "Oklahoma City Race Equipment" "Seattle Race Equipment"
##
## $X4
## [1] "Albuquerque Cycles" "Dallas Cycles"
## [3] "Denver Bike Shop" "Detroit Cycles"
## [5] "Kansas City 29ers" "Los Angeles Cycles"
## [7] "Minneapolis Bike Shop" "New York Cycles"
## [9] "Phoenix Bi-peds" "Portland Bi-peds"
## [11] "Providence Bi-peds"
##
## $X5
## [1] "Cincinnati Speed" "Columbus Race Equipment"
## [3] "Las Vegas Cycles" "Louisville Race Equipment"
## [5] "San Francisco Cruisers" "Wichita Speed"
Determining the Preferences of the Customer Segments
The easiest way to determine the customer preferences is by inspection of factors related to the model (e.g. price point, category of bike, etc). Advanced algorithms to classify the groups can be used if there are many factors, but typically this is not necessary as the trends tend to jump out. The code below attaches the k-means centroids to the bike models and categories for trend inspection.
# Combine cluster centroids with bike models for feature inspection ------------
custSegmentCntrs <- t(km.out.best$centers) # Get centroids for groups
colnames(custSegmentCntrs) <- make.names(colnames(custSegmentCntrs))
customerTrends.clustered <- bind_cols(customerTrends[,1:5], as.data.frame(custSegmentCntrs))
Now, on to cluster inspection.
Cluster 1
We’ll order by cluster 1’s top ten bike models in descending order. We can quickly see that the top 10 models purchased are predominantly high-end and mountain. The all but one model has a carbon frame.
# Arrange top 10 bike models by cluster in descending order --------------------
attach(customerTrends.clustered) # Allows ordering by column name
knitr::kable(head(customerTrends.clustered[order(-X1), c(1:5, 6)], 10))
| model |
category1 |
category2 |
frame |
price |
X1 |
| Scalpel-Si Carbon 3 |
Mountain |
Cross Country Race |
Carbon |
[3500,12790] |
0.0342692 |
| Jekyll Carbon 4 |
Mountain |
Over Mountain |
Carbon |
[ 415, 3500) |
0.0302818 |
| Scalpel 29 Carbon Race |
Mountain |
Cross Country Race |
Carbon |
[3500,12790] |
0.0280391 |
| Trigger Carbon 3 |
Mountain |
Over Mountain |
Carbon |
[3500,12790] |
0.0259353 |
| Habit Carbon 2 |
Mountain |
Trail |
Carbon |
[3500,12790] |
0.0233750 |
| Trigger Carbon 4 |
Mountain |
Over Mountain |
Carbon |
[ 415, 3500) |
0.0232606 |
| Catalyst 4 |
Mountain |
Sport |
Aluminum |
[ 415, 3500) |
0.0215639 |
| Jekyll Carbon 2 |
Mountain |
Over Mountain |
Carbon |
[3500,12790] |
0.0210792 |
| Supersix Evo Hi-Mod Dura Ace 2 |
Road |
Elite Road |
Carbon |
[3500,12790] |
0.0210578 |
| Trigger Carbon 2 |
Mountain |
Over Mountain |
Carbon |
[3500,12790] |
0.0210433 |
Cluster 2
Next, we’ll inspect cluster 2. We can see that the top models are all low-end/affordable models. There’s a mix of road and mountain for the primariy category and a mix of frame material as well.
# Arrange top 10 bike models by cluster in descending order
knitr::kable(head(customerTrends.clustered[order(-X2), c(1:5, 7)], 10))
| model |
category1 |
category2 |
frame |
price |
X2 |
| Slice Ultegra |
Road |
Triathalon |
Carbon |
[ 415, 3500) |
0.0554531 |
| Trigger Carbon 4 |
Mountain |
Over Mountain |
Carbon |
[ 415, 3500) |
0.0304147 |
| CAAD12 105 |
Road |
Elite Road |
Aluminum |
[ 415, 3500) |
0.0270792 |
| Beast of the East 3 |
Mountain |
Trail |
Aluminum |
[ 415, 3500) |
0.0263331 |
| Trail 1 |
Mountain |
Sport |
Aluminum |
[ 415, 3500) |
0.0249397 |
| Bad Habit 1 |
Mountain |
Trail |
Aluminum |
[ 415, 3500) |
0.0229976 |
| F-Si Carbon 4 |
Mountain |
Cross Country Race |
Carbon |
[ 415, 3500) |
0.0224490 |
| CAAD12 Disc 105 |
Road |
Elite Road |
Aluminum |
[ 415, 3500) |
0.0209568 |
| Synapse Disc 105 |
Road |
Endurance Road |
Aluminum |
[ 415, 3500) |
0.0209568 |
| Trail 2 |
Mountain |
Sport |
Aluminum |
[ 415, 3500) |
0.0203094 |
detach(customerTrends.clustered)
Clusters 3, 4 & 5
Inspecting clusters 3, 4 and 5 produce interesting results. For brevity, we won’t display the tables. Here’s the results:
- Cluster 3: Tends to prefer road bikes that are low-end.
- Cluster 4: Is very similar to Cluster 2 with the majority of bikes in the low-end price range.
- Cluster 5: Tends to refer road bikes that are high-end.
Reviewing Results
Once the clustering is finished, it’s a good idea to take a step back and review what the algorithm is saying. For our analysis, we got clear trends for four of five groups, but two groups (clusters 2 and 4) are very similar. Because of this, it may make sense to combine these two groups or to switch from \(k\) = 5 to \(k\) = 4 results.
Recap
The customer segmentation process can be performed with various clustering algorithms. In this post, we focused on k-means clustering in R. While the algorithm is quite simple to implement, half the battle is getting the data into the correct format and interpreting the results. We went over formatting the order data, running the kmeans() function to cluster the data with several hypothetical \(k\) clusters, using silhouette() from the cluster package to determine the optimal number of \(k\) clusters, and interpreting the results by inspection of the k-means centroids. Happy clustering!
Further Reading
- Data Smart by John Foreman: Chapter 2 covers k-medians clustering and silhouette analysis, which is very similar to the approach I use here.
Updates
-
August 28, 2016: There was an issue with the set.seed() being outside of the for-loop in the k-means algorithm preventing the kmeans output from being completely reproducible. The set.seed() was moved inside the for-loop.
-
August 16, 2017: There is an issue with cbind() from base R that resulted in data frames binding incorrectly. The bind_cols() function from dplyr is used instead.
Business Science University
Enjoy data science for business? We do too. This is why we created Business Science University where we teach you how to do Data Science For Busines (#DS4B) just like us!
Our first DS4B course (HR 201) is now available!
Who is this course for?
Anyone that is interested in applying data science in a business context (we call this DS4B). All you need is basic R, dplyr, and ggplot2 experience. If you understood this article, you are qualified.
What do you get it out of it?
You learn everything you need to know about how to apply data science in a business context:
-
Using ROI-driven data science taught from consulting experience!
-
Solve high-impact problems (e.g. $15M Employee Attrition Problem)
-
Use advanced, bleeding-edge machine learning algorithms (e.g. H2O, LIME)
-
Apply systematic data science frameworks (e.g. Business Science Problem Framework)